python3常用的数据清洗方法(小结)
首先载入各种包:
import pandas as pd import numpy as np from collections import Counter from sklearn import preprocessing from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 sns.set(font='SimHei') # 解决Seaborn中文显示问题
读入数据:这里数据是编造的
data=pd.read_excel('dummy.xlsx')
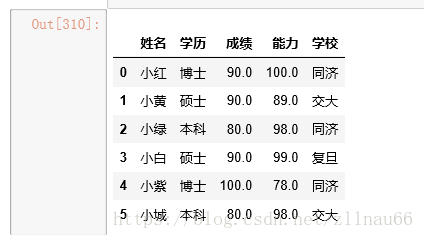
本案例的真实数据是这样的:
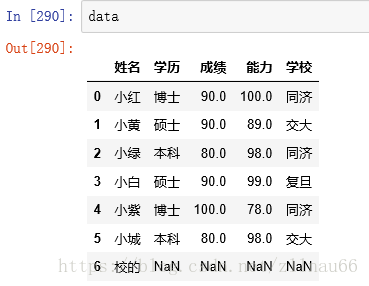
对数据进行多方位的查看:
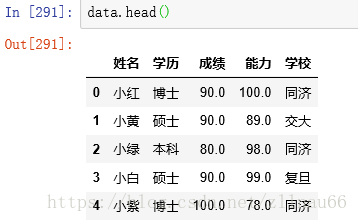
实际情况中可能会有很多行,一般用head()看数据基本情况
data.head() #查看长啥样 data.shape #查看数据的行列大小 data.describe()

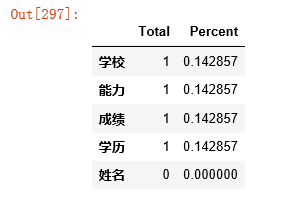
#列级别的判断,但凡某一列有null值或空的,则为真 data.isnull().any() #将列中为空或者null的个数统计出来,并将缺失值最多的排前 total = data.isnull().sum().sort_values(ascending=False) print(total) #输出百分比: percent =(data.isnull().sum()/data.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) missing_data.head(20)
也可以从视觉上直观查看缺失值:
import missingno missingno.matrix(data) data=data.dropna(thresh=data.shape[0]*0.5,axis=1) #至少有一半以上是非空的列筛选出来
#如果某一行全部都是na才删除: data.dropna(axis=0,how='all')
#默认情况下是只保留没有空值的行 data=data.dropna(axis=0)
#统计重复记录数 data.duplicated().sum() data.drop_duplicates()
对连续型数据和离散型数据分开处理:
data.columns #第一步,将整个data的连续型字段和离散型字段进行归类 id_col=['姓名'] cat_col=['学历','学校'] #这里是离散型无序,如果有序,请参考map用法,一些博客上有写 cont_col=['成绩','能力'] #这里是数值型 print (data[cat_col]) #这里是离散型的数据部分 print (data[cont_col])#这里是连续性数据部分
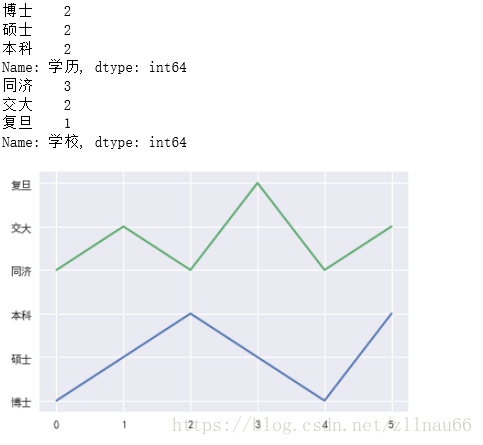
对于离散型部分:
#计算出现的频次 for i in cat_col: print (pd.Series(data[i]).value_counts()) plt.plot(data[i])
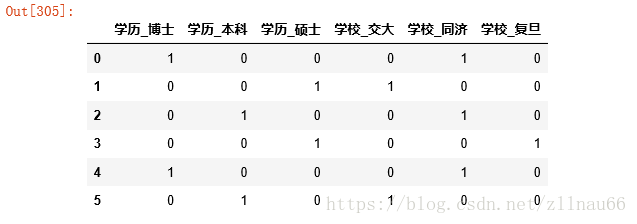
#对于离散型数据,对其获取哑变量 dummies=pd.get_dummies(data[cat_col]) dummies
对于连续型部分:
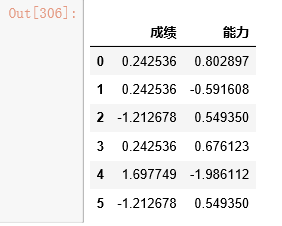
#对于连续型数据的大概统计: data[cont_col].describe() #对于连续型数据,看偏度,一般大于0.75的数值做一个log转化,使之尽量符合正态分布,因为很多模型的假设数据是服从正态分布的 skewed_feats = data[cont_col].apply(lambda x: (x.dropna()).skew() )#compute skewness skewed_feats = skewed_feats[skewed_feats > 0.75] skewed_feats = skewed_feats.index data[skewed_feats] = np.log1p(data[skewed_feats]) skewed_feats
#对于连续型数据,对其进行标准化 scaled=preprocessing.scale(data[cont_col]) scaled=pd.DataFrame(scaled,columns=cont_col) scaled
m=dummies.join(scaled) data_cleaned=data[id_col].join(m) data_cleaned
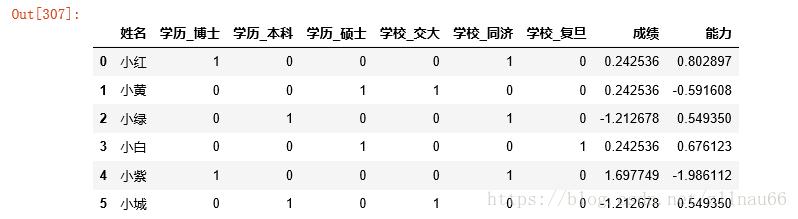
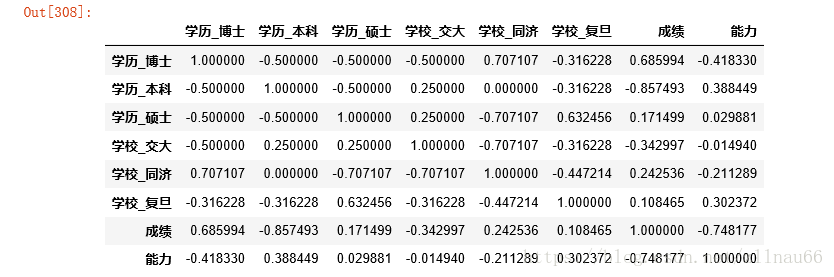
看变量之间的相关性:
data_cleaned.corr()
#以下是相关性的热力图,方便肉眼看
def corr_heat(df):
dfData = abs(df.corr())
plt.subplots(figsize=(9, 9)) # 设置画面大小
sns.heatmap(dfData, annot=True, vmax=1, square=True, cmap="Blues")
# plt.savefig('./BluesStateRelation.png')
plt.show()
corr_heat(data_cleaned)
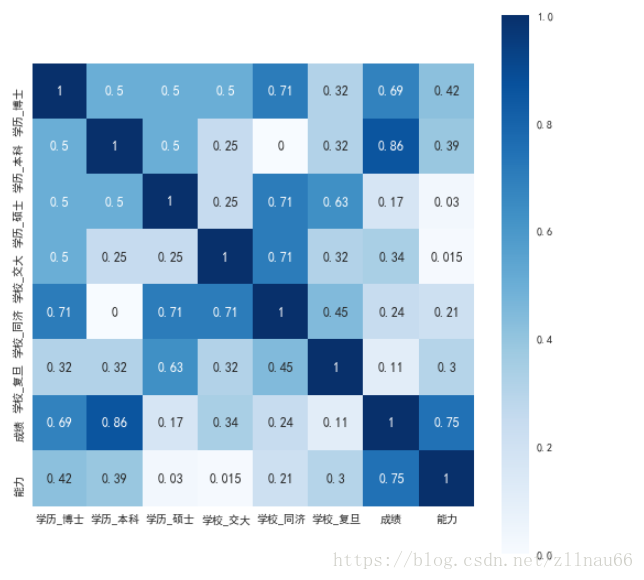
如果有觉得相关性偏高的视情况删减某些变量。
#取出与某个变量(这里指能力)相关性最大的前四个,做出热点图表示
k = 4 #number of variables for heatmap
cols = corrmat.nlargest(k, '能力')['能力'].index
cm = np.corrcoef(data_cleaned[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python数据清洗系列之字符串处理详解
前言 数据清洗是一项复杂且繁琐(kubi)的工作,同时也是整个数据分析过程中最为重要的环节.有人说一个分析项目80%的时间都是在清洗数据,这听起来有些匪夷所思,但在实际的工作中确实如此.数据清洗的目的有两个,第一是通过清洗让数据可用.第二是让数据变的更适合进行后续的分析工作.换句话说就是有"脏"数据要洗,干净的数据也要洗. 在数据分析中,特别是文本分析中,字符处理需要耗费极大的精力,因而了解字符处理对于数据分析而言,也是一项很重要的能力. 字符串处理方法 首先我们先了解下都有哪些基础方
-
8段用于数据清洗Python代码(小结)
最近,大数据工程师Kin Lim Lee在Medium上发表了一篇文章,介绍了8个用于数据清洗的Python代码. 数据清洗,是进行数据分析和使用数据训练模型的必经之路,也是最耗费数据科学家/程序员精力的地方. 这些用于数据清洗的代码有两个优点:一是由函数编写而成,不用改参数就可以直接使用.二是非常简单,加上注释最长的也不过11行.在介绍每一段代码时,Lee都给出了用途,也在代码中也给出注释.大家可以把这篇文章收藏起来,当做工具箱使用. 涵盖8大场景的数据清洗代码 这些数据清洗代码,一共涵盖8个
-
对python数据清洗容易遇到的函数-re.sub bytes string详解
re.sub 功能,比replace强大的替换函数,将正则表达式匹配上的模块替换成repl re.sub(pattern, repl, string, count=0, flags=0) 返回最左边正则表达式限定的被repl代替的字符串,如果正则表达式没有匹配上,则字符串不做修改. \n is converted to a single newline character, \r is converted to a carriage return, and so forth. Unknown e
-
python 数据清洗之数据合并、转换、过滤、排序
前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作, 数据清洗一直是数据分析中极为重要的一个环节. 数据合并 在pandas中可以通过merge对数据进行合并操作. import numpy as np import pandas as pd data1 = pd.DataFrame({'level':['a','b','c','d'], 'numeber':[1,3,5,7]}) data2=pd.DataFrame({'level':['a','b','c','e'], '
-
python3常用的数据清洗方法(小结)
首先载入各种包: import pandas as pd import numpy as np from collections import Counter from sklearn import preprocessing from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 p
-
SQL Server 常用函数使用方法小结
之前就想要把一些 SQL 的常用函数记录下来,不过一直没有实行...嘿嘿... 直到今天用到substring()这个函数,C# 里面这个方法起始值是 0,而 SQL 里面起始值是 1.傻傻分不清楚... 这篇博客作为记录 SQL 的函数的使用方法,想到哪里用到哪里就写到哪里... SubString():用于截取指定字符串的方法.该方法有三个参数: 参数1:用于指定要操作的字符串. 参数2:用于指定要截取的字符串的起始位置,起始值为 1 . 参数3:用于指定要截取的长度. select sub
-
Python3常用内置方法代码实例
这篇文章主要介绍了Python3常用内置方法代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 max()/min() 传入一个参数 (可迭代对象), 返回这个可迭代对象中最大的元素 可以设置default关键字参数, 当这个可迭代对象为空时, 返回default的值 传入多个参数, 返回这些参数中最大的参数 多个参数必须是同类型的 两种方法都可以设置key关键字参数(传入函数) """ max(iterable, *[
-
C#实现的4种常用数据校验方法小结(CRC校验,LRC校验,BCC校验,累加和校验)
CRC即循环冗余校验码(Cyclic Redundancy Check):是数据通信领域中最常用的一种查错校验码,其特征是信息字段和校验字段的长度可以任意选定.循环冗余检查(CRC)是一种数据传输检错功能,对数据进行多项式计算,并将得到的结果附在帧的后面,接收设备也执行类似的算法,以保证数据传输的正确性和完整性. CRC算法参数模型解释: NAME:参数模型名称. WIDTH:宽度,即CRC比特数. POLY:生成项的简写,以16进制表示.例如:CRC-32即是0x04C11DB7,忽略了最高位
-
jQuery操作表单常用控件方法小结
本文实例总结了jQuery操作表单常用控件方法.分享给大家供大家参考.具体如下: 下面的JS代码列出了jQuery操作表单常用控件(包括select,radiobox,checkbox)的常用方法,相信一定有你需要的 操作radio的html代码 Radion <input type="radio" name="rd" id="rd1" checked="checked" value="rd1" /&
-
ES6中字符串string常用的新增方法小结
本文实例讲述了ES6中字符串string常用的新增方法.分享给大家供大家参考,具体如下: ES6为js新增了很多方法,包括遍历.查询.替换等等,可以很简洁的替换ES5中的类似方法,本文不考虑codePointAt等不常用方法. for-of: let str="wbiokr"; for(let s of str){ console.log(s) } //结果:w, b, i, o, k, r 由于es5并没有为js制定字符串相关遍历方法,for-of无疑会是接下来前端开发中的一个很重要
-
Python3 常用数据标准化方法详解
数据标准化是机器学习.数据挖掘中常用的一种方法.包括我自己在做深度学习方面的研究时,数据标准化是最基本的一个步骤. 数据标准化主要是应对特征向量中数据很分散的情况,防止小数据被大数据(绝对值)吞并的情况. 另外,数据标准化也有加速训练,防止梯度爆炸的作用. 下面是从李宏毅教授视频中截下来的两张图. 左图表示未经过数据标准化处理的loss更新函数,右图表示经过数据标准化后的loss更新图.可见经过标准化后的数据更容易迭代到最优点,而且收敛更快. 一.[0, 1] 标准化 [0, 1] 标准化是最基
-
Javascript中常用的检测方法小结
一.数组检测 1.使用ARRAY.ISARRAY() Array.isArray(obj) 例如: Array.isArray([]) //true Array.isArray({}) //false 兼容性: CHROME FIREFOX IE OPERA SAFARI 5 4.0(2.0) 9 10.5 5 可以使用以下方式,先检测是否支持Array.isArray. if(Array.isArray){ return Array.isArray(obj); } 2. 使用INSTANCEO
-
Python3内置模块random随机方法小结
前言 random是Python中与随机数相关的模块,其本质就是一个伪随机数生成器,我们可以利用random模块基础生成各种不同的随机数,以及一些基于随机数的操作. 生成随机数相关 生成0~1之间的浮点数 import random r = random.random() print(r) r = random.random() print(r) 示例结果: 0.9928249533693085 0.474901555446297 生成指定范围内的浮点数 import random r = ra
-
python3 selenium 切换窗口的几种方法小结
第一种方法: 使用场景: 打开多个窗口,需要定位到新打开的窗口 使用方法: # 获取打开的多个窗口句柄 windows = driver.window_handles # 切换到当前最新打开的窗口 driver.switch_to.window(windows[-1]) 举例说明: # _._ coding:utf-8 _._ """ :author: 花花测试 :time: 2017.05.03 :content: 使用第一种方法切换浏览器 ""&quo