基于postgresql行级锁for update测试
创建表:
CREATE TABLE db_user ( id character varying(50) NOT NULL, age integer, name character varying(100), roleid character varying, CONSTRAINT db_user_pkey PRIMARY KEY (id) )
随便插入几条数据即可。
一、不加锁演示
1、打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行:
begin;
select * from db_user where name='lisi';
输出结果:

2、再打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行:
begin;
select * from db_user where name='lisi';
输出结果:

二、加锁演示(for update)
1、打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行:
begin;
select * from db_user where name='lisi' for update;
输出结果:

2、再打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行:
begin;
select * from db_user where name='lisi' for update;
输出结果:

查询一直处于执行中状态。
3、第一个窗口执行:
commit;
第二个窗口立即执行查询操作,结果如下:

第二个窗口记得提交commit;。
三、加锁演示(for update nowait)
1、打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行:
begin;
select * from db_user where name='lisi' for update nowait;
输出结果:

2、再打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行:
begin;
select * from db_user where name='lisi' for update nowait;
输出结果:
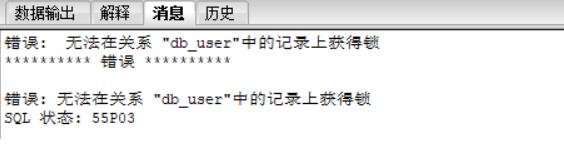
不会进行资源等待,返回错误信息。
3、第一个窗口执行:
commit;
提交成功,资源锁释放。
总结:
for update nowait和 for update 都会对所查询到得结果集进行加锁,所不同的是,如果另外一个线程正在修改结果集中的数据,for update nowait 不会进行资源等待,只要发现结果集中有些数据被加锁,立刻返回 “55P03错误,内容是无法在记录上获得锁.
命令说明:
begin;--开启事务
begin transaction;--开启事务
commit;--提交
rollback;--回滚
set lock_timeout=5000;--设置超时时间
注意:
连表查询加锁时,不支持单边连接形式,例如:
select u.*,r.* from db_user u left join db_role r on u.roleid=r.id for update;
支持以下形式,并锁住了两个表中关联的数据:
select u.*,r.* from db_user u, db_role r where u.roleid=r.id for update;
补充:PostgreSQL select for update指定列(兼容oracle)
我们可以使用select for update语句来指定锁住某一张表,在oracle中我们可以在for update语句后指定某一列,用来单独锁定指定列的数据。
oracle例子:
建表:
SQL> create table t1(id int, c2 varchar(20), c3 int, c4 float, c5 float); Table created. SQL> create table t2(id int, c6 int); Table created. SQL> insert into t1 values (1, 'SA_REP', 1, 100, 1); 1 row created. SQL> insert into t1 values (1, 'SA_REP123', 1, 100, 1); 1 row created. SQL> insert into t2 values (1, 2500); 1 row created.
查询:
我们使用下列查询用来只锁住c4列。
SQL> SELECT e.c3, e.c4, e.c5
2 FROM t1 e JOIN t2 d
USING (id)
WHERE c2 = 'SA_REP'
AND c6 = 2500
3 4 5 6 FOR UPDATE OF e.c4
7 ORDER BY e.c3;
C3 C4 C5
---------- ---------- ----------
1 100 1
PostgreSQL兼容方法:
建表:
create table t1(id int, c2 text, c3 int, c4 float, c5 float); create table t2(id int, c6 int); insert into t1 values (1, 'SA_REP', 1, 100, 1); insert into t1 values (1, 'SA_REP123', 1, 100, 1); insert into t2 values (1, 2500);
pg中使用方法和oracle类似,只是需要将order by语法放到前面,并且将列名换成表名。
bill=# SELECT e.c3, e.c4, e.c5 bill-# FROM t1 e JOIN t2 d bill-# USING (id) bill-# WHERE c2 = 'SA_REP' bill-# AND c6 = 2500 bill-# ORDER BY e.c3 bill-# FOR UPDATE OF e ; c3 | c4 | c5 ----+-----+---- 1 | 100 | 1 (1 row)
验证:
我们可以验证下pg中是否只锁定了指定的行。
1、安装pgrowlocks插件
bill=# create extension pgrowlocks;
CREATE EXTENSION
2、观察
t1表被锁:
bill=# select * from pgrowlocks('t1');
locked_row | locker | multi | xids | modes | pids
------------+--------+-------+--------+----------------+--------
(0,1) | 1037 | f | {1037} | {"For Update"} | {2022}
(1 row)
t2表没有被锁:
bill=# select * from pgrowlocks('t2');
locked_row | locker | multi | xids | modes | pids
------------+--------+-------+------+-------+------
(0 rows)
我们还可以再看看t1表中具体被锁住的数据:
bill=# SELECT * FROM t1 AS a, pgrowlocks('t1') AS p
bill-# WHERE p.locked_row = a.ctid;
id | c2 | c3 | c4 | c5 | locked_row | locker | multi | xids | modes | pids
----+--------+----+-----+----+------------+--------+-------+--------+----------------+--------
1 | SA_REP | 1 | 100 | 1 | (0,1) | 1037 | f | {1037} | {"For Update"} | {2022}
(1 row)
除此之外,pg中for update子句还有其它的选项:
UPDATE – 当前事务可以改所有字段
NO KEY UPDATE – 当前事务可以改除referenced KEY以外的字段
SHARE – 其他事务不能改所有字段
KEY SHARE – 其他事务不能改referenced KEY字段
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

postgresql插入后返回id的操作
如下所示: 补充:PostgreSQL中执行insert同时返回插入的那行数据 通过使用语句: INSERT INTO tab1 ... RETURNING *; 以上这篇postgresql插入后返回id的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
postgreSql分组统计数据的实现代码
1. 背景 比如气象台的气温监控,每半小时上报一条数据,有很多个地方的气温监控,这样数据表里就会有很多地方的不同时间的气温数据 2. 需求: 每次查询只查最新的气温数据按照不同的温度区间来分组查出,比如:高温有多少地方,正常有多少地方,低温有多少地方 3. 构建数据 3.1 创建表结构: -- DROP TABLE public.t_temperature CREATE TABLE public.t_temperature ( id int4 NOT NULL GENERATED ALWAYS
-
postgresql 实现数据的导入导出
最近想把服务器上的测试数据库数据导到我本地的电脑上,本地电脑数据库是安装在windows系统下 之前没使用过pgsql,网上找了点资料,记入如下: 一,首先把服务器上的数据进行备份 pg_dump -U 用户名 数据库名 (-t 表名)> 数据存放路径 二,把.sql 文件下载到本地之后,首先切换到pgsql路径下的bin目录 然后执行这条命令: -d:数据库名 -h:地址 -p:端口 -u:用户名 -f:sql文件路径 之后输入口令: 这样就可以了! 补充:Sqoop从PostgreSQL导入
-
查看postgresql数据库用户系统权限、对象权限的方法
PostgreSQL简介 PostgreSQL是一种特性非常齐全的自由软件的对象-关系型数据库管理系统(ORDBMS),是以加州大学计算机系开发的POSTGRES,4.2版本为基础的对象关系型数据库管理系统.POSTGRES的许多领先概念只是在比较迟的时候才出现在商业网站数据库中.PostgreSQL支持大部分的SQL标准并且提供了很多其他现代特性,如复杂查询.外键.触发器.视图.事务完整性.多版本并发控制等.同样,PostgreSQL也可以用许多方法扩展,例如通过增加新的数据类型.函数.操作符
-
Python操作PostgreSql数据库的方法(基本的增删改查)
Python操作PostgreSql数据库(基本的增删改查) 操作数据库最快的方式当然是直接用使用SQL语言直接对数据库进行操作,但是偶尔我们也会碰到在代码中操作数据库的情况,我们可能用ORM类的库对数控库进行操作,但是当需要操作大量的数据时,ORM的数据显的太慢了.在python中,遇到这样的情况,我推荐使用psycopg2操作postgresql数据库 psycopg2 官方文档传送门: http://initd.org/psycopg/docs/index.html 简单的增删改查 连接
-
postgreSQL数据库 实现向表中快速插入1000000条数据
不用创建函数,直接向表中快速插入1000000条数据 create table tbl_test (id int, info text, c_time timestamp); insert into tbl_test select generate_series(1,100000),md5(random()::text),clock_timestamp(); select count(id) from tbl_test; --查看个数据条数 补充:postgreSQL 批量插入10000条数据
-
Postgresql锁机制详解(表锁和行锁)
表锁 LOCK [ TABLE ] [ ONLY ] name [ * ] [, ...] [ IN lockmode MODE ] [ NOWAIT ] lockmode包括以下几种: ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE LOCK TABLE命令用于获取一个表锁,获取过程将阻塞一直
-
PostgreSQL function返回多行的操作
1. 建表 postgres=# create table tb1(id integer,name character varying); CREATE TABLE postgres=# postgres=# insert into tb1 select generate_series(1,5),'aa'; INSERT 0 5 2. 返回单字段的多行(returns setof datatype) 不指定out参数,使用return next xx: create or replace fun
-
基于postgresql行级锁for update测试
创建表: CREATE TABLE db_user ( id character varying(50) NOT NULL, age integer, name character varying(100), roleid character varying, CONSTRAINT db_user_pkey PRIMARY KEY (id) ) 随便插入几条数据即可. 一.不加锁演示 1.打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行: begin; s
-
Java操作数据库(行级锁,for update)
目录 一.悲观锁(也叫行级锁) 1.使用悲观锁(在事务中的sql语句中使用) 2..完整代码 3..测试代码 4.结论 一.悲观锁(也叫行级锁) 在本次事务的执行过程当中,我们指定的记录被查询,在我查询的过程当中记录就会被锁定,任何人,任何事务都不能对我指定查询数据进行修改操作(不能改,但是可以看),直到我都查询结束. 1.使用悲观锁(在事务中的sql语句中使用) //sql指令 String sql = "select * from t_shuihuo where id < ? for
-
MySQL行级锁、表级锁、页级锁详细介绍
页级:引擎 BDB.表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行行级:引擎 INNODB , 单独的一行记录加锁 表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作.如果你是写锁,则其它进程则读也不允许行级,,仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作.页级,表级锁速度快,但冲突多,行级冲突少,但速度慢.所以取了折衷的页级,一次锁定相邻的一组记录. MySQL 5.1支持对MyISAM和MEMORY表进行表级锁定,对BDB表进行
-
MySQL中的行级锁、表级锁、页级锁
在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的满足. 在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎).表级锁(MYISAM引擎)和页级锁(BDB引擎 ). 一.行级锁 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁.行级锁能大大减少数据库操作的冲突.其加锁粒度最小,但加锁的开销也最大.行级锁分为共享锁 和 排他锁. 特点 开销大,加锁慢:会出现死锁:锁定粒度最小,发生锁冲突的概率最低,并发度也
-
MySQL的表级锁,行级锁,排它锁和共享锁
目录 前言 一.表级锁&行级锁 二.排它锁&共享锁 1. 测试不同事务之间排它锁和共享锁的兼容性 2. 测试行锁加在索引项上 三.串行化隔离级别测试 前言 如果我们和面试官聊到事务的问题,怎么回答呢? 先说下事务是什么,因为我们业务是比较复杂的,不可能一个sql就能解决的,涉及多个sql就组成一个事务.事务就是一组sql共同执行,要么完全成功,要么完全失败,不能出现部分成功或者部分失败的情况.一个事务有ACID特性(可以参考:事务的ACID特性和MySQL事务的隔离级别): 原子性:要么全
-
Oracle 数据库针对表主键列并发导致行级锁简单演示
本文内容 •软件环境 •简单演示 Oracle 数据库并发导致行级锁 本文简单演示针对表主键并发导致的行级锁.并发是两个以上的用户对同样的数据进行修改(包括插入.删除和修改).锁的产生是因为并发.没有并发,就没有锁.并发的产生是因为系统需要,系统需要是因为用户需要. 软件环境 -------------------------------------------------------------------------------- •Windows 2003 Server •Oracle 1
-
Oracle行级锁的特殊用法简析
Oracle有许多的锁,各种锁的效用是不一样的.下面重点介绍Oracle行级锁,Oracle行级锁只对用户正在访问的行进行锁定.可以更好的保证数据的安全性. 如果该用户正在修改某行,那么其他用户就可以更新同一表中该行之外的数据. Oracle行级锁是一种排他锁,防止其他事务修改此行,但是不会阻止读取此行的操作. 在使用INSERT.UPDATE.DELETE 和SELECT-FOR UPDATE 等 语句时,Oracle会自动应用Oracle行级锁行级锁锁定.SELECT...FOR UPDAT
-
Mysql 行级锁的使用及死锁的预防方案
一.前言 mysql的InnoDB,支持事务和行级锁,可以使用行锁来处理用户提现等业务.使用mysql锁的时候有时候会出现死锁,要做好死锁的预防. 二.MySQL行级锁 行级锁又分共享锁和排他锁. 共享锁: 名词解释:共享锁又叫做读锁,所有的事务只能对其进行读操作不能写操作,加上共享锁后其他事务不能再加排他锁了只能加行级锁. 用法: SELECT `id` FROM table WHERE id in(1,2) LOCK IN SHARE MODE 结果集的数据都会加共享锁 排他锁: 名词解释:
-
MySQL中的行级锁定示例详解
前言 锁是在执行多线程时用于强行限定资源访问的同步机制,数据库锁根据锁的粒度可分为行级锁,表级锁和页级锁 行级锁 行级锁是mysql中粒度最细的一种锁机制,表示只对当前所操作的行进行加锁,行级锁发生冲突的概率很低,其粒度最小,但是加锁的代价最大.行级锁分为共享锁和排他锁. 特点: 开销大,加锁慢,会出现死锁:锁定粒度最小,发生锁冲突的概率最大,并发性也高: 实现原理: InnoDB行锁是通过给索引项加锁来实现的,这一点mysql和oracle不同,后者是通过在数据库中对相应的数据行加锁来实现的,
-
基于String实现同步锁的方法步骤
在某些时候,我们可能想基于字符串做一些事情,比如:针对同一用户的并发同步操作,使用锁字符串的方式实现比较合理.因为只有在相同字符串的情况下,并发操作才是不被允许的.而如果我们不分青红皂白直接全部加锁,那么整体性能就下降得厉害了. 因为string的多样性,看起来string锁是天然比分段锁之类的高级锁更有优势呢. 因为String 类型的变量赋值是这样的: String a = "hello world."; 所有往往会有个错误的映象,String对象就是不可变的. 额,关于这个问题的