基于python爬取有道翻译过程图解
1.准备工作
先来到有道在线翻译的界面http://fanyi.youdao.com/
F12 审查元素 ->选Network一栏,然后F5刷新 (如果看不到Method一栏,右键Name栏,选中Method)

输入文字自动翻译后发现Method一栏有GET还有POST;GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据、
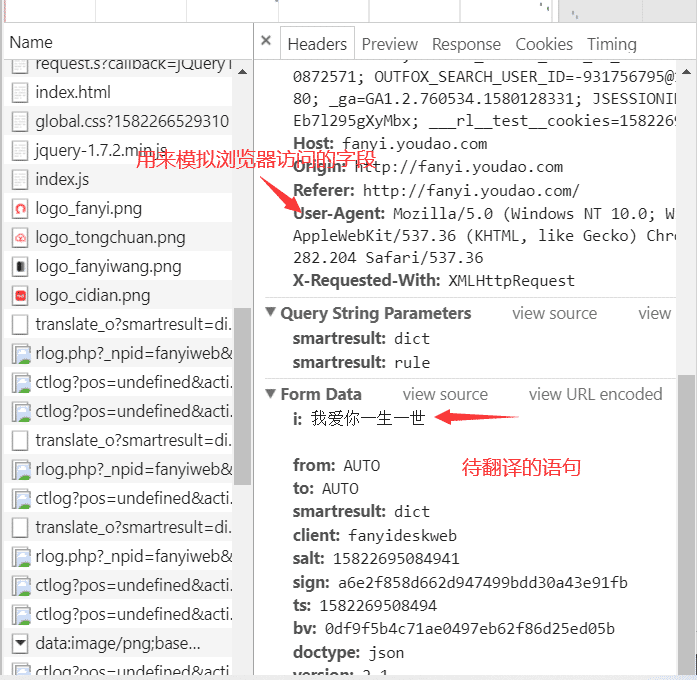
随便打开一个POST,找到preview可以看到我们输入的“我爱你一生一世”数据,可以证明post的提交数据的

下面分析一下Headers各个字段的意义;User-agent字段很重要

下面来看一下request模块中urlopen方法,查看文档;
发现urlopen有一个data参数,如果参数没赋值(默认None)就是GET形式,如果data参数被赋值了,就以POST形式提交

在这里,data参数其实是一个字典 ;就是源代码中From Data的数据
下面一篇文章是对urlencode与unquote的详细解释:(urllib库里可惜没有urldecode函数)
https://www.jb51.net/article/183857.htm
为什么要进行编码和解码呢?------》对于一些中文或者字符,url是不识别的,需要进行编码转换!encode('utf-8')把unicode的形式变成utf-8decode('utf-8')把utf-8形式变成Unicode编码形式2.下面进行敲!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python实现决策树并且使用Graphvize可视化的例子
一.什么是决策树(decision tree)--机器学习中的一个重要的分类算法 决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点 根据天气情况决定出游与否的案例 二.决策树算法构建 2.1决策树的核心思路 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法). 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集
-
解决使用export_graphviz可视化树报错的问题
在使用可视化树的过程中,报错了.说是'dot.exe'not found in path 原代码: # import tools needed for visualization from sklearn.tree import export_graphviz import pydot #Pull out one tree from the forest tree = rf.estimators_[5] # Export the image to a dot file export_graphv
-
windows下Graphviz安装及入门教程的实现方法
下载安装配置环境变量intall配置环境变量验证基本绘图入门graphdigraph一个复杂的例子和python交互 发现好的工具,如同发现新大陆.有时,我们会好奇,论文中.各种专业的书中那么形象的插图是如何做出来的,无一例外不是对绘图工具的熟练使用. 下载安装.配置环境变量 intall windows版本下载地址:http://www.graphviz.org/Download_windows.php 双击msi文件,然后一直next(记住安装路径,后面配置环境变量会用到路径信息),安装完成
-
Python调用graphviz绘制结构化图形网络示例
首先要下载:Graphviz - Graph Visualization Software 安装完成后将安装目录的bin 路径加到系统路径中,有时候需要重启电脑. 然后: pip install graphviz import graphviz as gz 有向图 dot = gz.Digraph() dot.node('1', 'Test1') dot.node('2', 'Test2') dot.node('3', 'Test3') dot.node('4', 'Test4') dot.ed
-
VSCode基础使用与VSCode调试python程序入门的图文教程
用VSCode编程是需要依赖扩展的.写python需要安装python的扩展,写C++需要安装C++的扩展.刚打开编辑器的时候,它一般会推荐一些扩展,你如果什么都不知道,可以先安装官方推荐的这些扩展: 修改VSCode的一些选项的默认值 VSCode有很多选项可以被修改,其各个选项都有默认值,这些默认值存储在"\settings.json"中(不过我没找到这个文件),用户如果想修改某些选项的值(比如:修改字体的大小),VSCode会自动帮我们生成一个"settings.jso
-
Python使用graphviz画流程图过程解析
问题描述 项目中需要用到流程图,如果用js的echarts处理,不同层级建动态计算位置比较复杂,考虑用python来实现 测试demo 实现效果如下 完整代码 import yaml import os import ibm_db from graphviz import Digraph from datetime import datetime # db连接 def db2_query(sql): conn = ibm_db.connect( "DATABASE=%s;HOSTNAME=%s;
-
基于python爬取有道翻译过程图解
1.准备工作 先来到有道在线翻译的界面http://fanyi.youdao.com/ F12 审查元素 ->选Network一栏,然后F5刷新 (如果看不到Method一栏,右键Name栏,选中Method) 输入文字自动翻译后发现Method一栏有GET还有POST:GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据. 随便打开一个POST,找到preview可以看到我们输入的"我爱你一生一世"数据,可以证明post的提交数据的 下面分析一下Header
-
Python爬取阿拉丁统计信息过程图解
背景 目前项目在移动端上,首推使用微信小程序.各项目的小程序访问数据有必要进行采集入库,方便后续做统计分析.虽然阿拉丁后台也提供了趋势分析等功能,但一个个的获取数据做数据分析是很痛苦的事情.通过将数据转换成sql持久化到数据库上,为后面的数据分析和展示提供了基础. 实现思路 阿拉丁产品分开放平台和统计平台两个产品线,目前开放平台有api及配套的文档.统计平台api需要收费,而且贼贵.既然没有现成的api可以获取数据,那么我们尝试一下用python抓取页面上的数据,毕竟python擅长干这种事情.
-
基于python爬取梨视频实现过程解析
目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8.其实你要哪一页都行,你喜欢就行.嘿嘿- 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,想要锻炼的可以找找看哈: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0 这个就是我们要找的目标网址啦,后面的0就代表页数,让
-
Python爬虫实现简单的爬取有道翻译功能示例
本文实例讲述了Python爬虫实现简单的爬取有道翻译功能.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import urllib.request import urllib.parse import json while True : content = input("请输入需要翻译的内容:(按q退出)") if content == 'q' : break url = 'http://fanyi.youdao.com/trans
-

利用python爬取有道词典的方法
前言 大家好 最近python爬虫有点火啊,啥python爬取马保国视频--我也来凑个热闹,今天我们来试着做个翻译软件--不是不是,说错了,今天我们来试着提交翻译内容并爬取翻译结果 主要内容 材料 1.Python 3.8.4 2.电脑一台(应该不至于有"穷苦人家"连一台电脑都没有吧) 3.Google浏览器(其他的也行,但我是用的Google) 写程序前准备 打开Google浏览器,找的有道词典的翻译网页(http://fanyi.youdao.com/) 打开后摁F12打开开发
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi
-
基于Python爬取爱奇艺资源过程解析
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素"英文名",然后出来的视频,共有20页,那么我们便从第一页开始,解析网页,然后分析 分析每一页网址,找出规律就可以直接得到所有页面 然后根据每一个视频的URL的标签,如'class' 'div' 'href'......通过bs4库进行爬取 而其他的信息则是直接循环所爬取到的URL,在每一个
-
基于Python爬取fofa网页端数据过程解析
FOFA-网络空间安全搜索引擎是网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,拥有全球联网IT设备更全的DNA信息.探索全球互联网的资产信息,进行资产及漏洞影响范围分析.应用分布统计.应用流行度态势感知等. 安装环境: pip install requests pip install lxml pip install fire 使用命令: python fofa.py -s=title="你的关键字" -o="结果输出文件" -c=&qu
-
基于Python爬取搜狐证券股票过程解析
数据的爬取 我们以上证50的股票为例,首先需要找到一个网站包含这五十只股票的股票代码,例如这里我们使用搜狐证券提供的列表. https://q.stock.sohu.com/cn/bk_4272.shtml 可以看到,在这个网站中有上证50的所有股票代码,我们希望爬取的就是这个包含股票代码的表,并获取这个表的第一列. 爬取网站的数据我们使用Beautiful Soup这个工具包,需要注意的是,一般只能爬取到静态网页中的信息. 简单来说,Beautiful Soup是Python的一个库,最主要的
-
如何基于Python爬取隐秘的角落评论
"一起去爬山吧?" 这句台词火爆了整个朋友圈,没错,就是来自最近热门的<隐秘的角落>,豆瓣评分8.9分,好评不断. 感觉还是蛮不错的.同时,为了想更进一步了解一下小伙伴观剧的情况,永恒君抓取了爱奇艺平台评论数据并进行了分析.下面来做个分享,给大伙参考参考. 1.爬取评论数据 因为该剧是在爱奇艺平台独播的,自然数据源从这里取比较合适.永恒君爬取了<隐秘的角落>12集的从开播日6月16日-6月26日的评论数据. 使用 Chrome 查看源代码模式,在播放页面往下面滑