SQL Server中使用表变量和临时表
一、表变量
表变量在SQL Server 2000中首次被引入。
表变量的具体定义包括列定义,列名,数据类型和约束。而在表变量中可以使用的约束包括主键约束,唯一约束,NULL约束和CHECK约束(外键约束不能在表变量中使用)。
定义表变量的语句是和正常使用Create Table定义表语句的子集。只是表变量通过DECLARE @local_variable语句进行定义。
1、定义和使用表变量
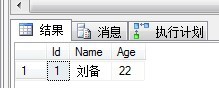
定义一个表变量,插入一条数据,然后查询:
DECLARE @tb1 Table ( Id int, Name varchar(20), Age int ) INSERT INTO @tb1 VALUES(1,'刘备',22) SELECT * FROM @tb1
输出结果如下:
2、表变量不能做如下事情:
来试试一些不符合要求的情况,例如添加表变量后,添加约束,并对约束命名:
ALTER TABLE @tb1 ADD CONSTRAINT CN_AccountAge
CHECK
(Account_Age > 18); -- 插入年龄必须大于18
SQL Server提示错误如下:

SQL Server不支持定义表变量时对Constraint命名,也不支持定义表变量后,对其建Constraint。
更多的不允许,请查看下面的要求。
- 虽然表变量是一个变量,但是其不能赋值给另一个变量。
- check约束,默认值和计算列不能引用自定义函数。
- 不能为约束命名。
- 不能Truncate表变量。
- 不能向标识列中插入显式值(也就是说表变量不支持SET IDENTITY_INSERT ON)
3、表变量的特征:
- 表变量拥有特定作用域(在当前批处理语句中,但不在任何当前批处理语句调用的存储过程和函数中),表变量在批处理结束后自动被清除。
- 表变量较临时表产生更少的存储过程重编译。
- 针对表变量的事务仅仅在更新数据时生效,所以锁和日志产生的数量会更少。
- 由于表变量的作用域如此之小,而且不属于数据库的持久部分,所以事务回滚不会影响表变量。
表变量可以在其作用域内像正常的表一样使用。更确切的说,表变量可以被当成正常的表或者表表达式一样在SELECT,DELETE,UPDATE,INSERT语句中使用,但是表变量不能在类似"SELECT select_list INTO table_variable"这样的语句中使用。而在SQL Server2000中,表变量也不能用于INSERT INTO table_variable EXEC stored_procedure这样的语句中。
二、临时表
在深入临时表之前,我们要了解一下会话(Session),一个会话仅仅是一个客户端到数据引擎的连接。在SQL Server Management Studio中,每一个查询窗口都会和数据库引擎建立连接。
一个应用程序可以和数据库建立一个或多个连接,除此之外,应用程序还可能建立连接后一直不释放知道应用程序结束,也可能使用完释放连接需要时建立连接。
临时表和Create Table语句创建的表有着相同的物理工程,但临时表与正常的表不同之处有:
- 临时表的名称不能超过116个字符,这是由于数据库引擎为了辨别不同会话建立不同的临时表,所以会自动在临时表的名字后附加一串。
- 局部临时表(以"#"开头命名的)作用域仅仅在当前的连接内,从在存储过程中建立局部临时表的角度来看,局部临时表会在下列情况下被Drop:
a、显示调用Drop Table语句
b、当局部临时表在存储过程内被创建时,存储过程结束也就意味着局部临时表被Drop。
c、当前会话结束,在会话内创建的所有局部临时表都会被Drop。 - 全局临时表(以"##"开头命名的)在所有的会话内可见,所以在创建全局临时表之前首先检查其是否存在,否则如果已经存在,你将会得到重复创建对象的错误。
a、全局临时表会在创建其的会话结束后被Drop,Drop后其他会话将不能对全局临时表进行引用。
b、引用是在语句级别进行 - 不能对临时表进行分区。
- 不能对临时表加外键约束。
- 临时表内列的数据类型不能定义成没有在TempDb中没有定义自定义数据类型(自定义数据类型是数据库级别的对象,而临时表属于TempDb)。
由于TempDb在每次SQL Server重启后会被自动创建,所以你必须使用startup stored procedure来为TempDb创建自定义数据类型。你也可以通过修改Model数据库来达到这一目标。 - XML列不能定义成XML集合的形式,除非这个集合已经在TempDb中定义。
临时表既可以通过Create Table语句创建,也可以通过"SELECT <select_list> INTO #table"语句创建。你还可以针对临时表用"INSERT INTO #table EXEC stored_procedure"这样的语句。
临时表可以拥有命名的约束和索引。但是,当两个用户在同一时间调用同一存储过程时,将会产生”There is already an object named ‘<objectname>’ in the database”这样的错误。所以最好的做法是不用为建立的对象进行命名,而使用系统分配的在TempDb中唯一的。
1、全局临时表引用是在语句级别进行
如:
1.新建查询窗口,运行语句:
CREATE TABLE ##temp(RowID int) INSERT INTO ##temp VALUES(3)
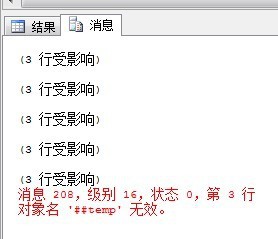
2.再次新建一个查询窗口,每5秒引用一次全局临时表
While 1=1 BEGIN SELECT * FROM ##temp WAITFOR delay '00:00:05' END
3.回到第一个窗口,关闭窗口。
4.下一次第二个窗口引用时,将产生错误。
三、比较
微软推荐使用表变量,如果表中的行数非常小,则使用表变量。
临时表和表变量有很多类似的地方。所以有时候并没有具体的细则规定如何选择哪一个。对任何特定的情况,你都需要考虑其各自优缺点并做一些性能测试。
下面的表格会让你比较其优略有了更详细的参考。
| 特性 | 表变量 | 临时表 |
|---|---|---|
| 作用域 | 当前批处理 | 当前会话,嵌套存储过程, 全局:所有会话 |
| 使用场景 | 自定义函数,存储过程,批处理 | 自定义函数,存储过程,批处理 |
| 创建方式 | 只能通过DECLEARE语句创建 |
CREATE TABLE 语句 SELECT INTO 语句. |
| 表名长度 | 最多128字节 | 最多116字节 |
| 列类型 |
可以使用自定义数据类型 可以使用XML集合 |
自定义数据类型和XML集合必须在TempDb内定义 |
| Collation | 字符串排序规则继承自当前数据库 | 字符串排序规则继承自TempDb数据库 |
| 索引 | 索引必须在表定义时建立 | 索引可以在表创建后建立 |
| 约束 | PRIMARY KEY, UNIQUE, NULL, CHECK约束可以使用,但必须在表建立时声明 | PRIMARY KEY, UNIQUE, NULL, CHECK. 约束可以使用,可以在任何时后添加,但不能有外键约束 |
| 表建立后使用DDL (索引,列) | 不允许 | 允许. |
| 数据插入方式 | INSERT 语句 (SQL 2000: 不能使用INSERT/EXEC). |
INSERT 语句, 包括 INSERT/EXEC. SELECT INTO 语句. |
| Insert explicit values into identity columns (SET IDENTITY_INSERT). | 不支持SET IDENTITY_INSERT语句 | 支持SET IDENTITY_INSERT语句 |
| Truncate table | 不允许 | 允许 |
| 析构方式 | 批处理结束后自动析构 | 显式调用 DROP TABLE 语句. 当前会话结束自动析构 (全局临时表: 还包括当其它会话语句不在引用表.) |
| 事务 | 只会在更新表的时候有事务,持续时间比临时表短 | 正常的事务长度,比表变量长 |
| 存储过程重编译 | 否 | 会导致重编译 |
| 回滚 | 不会被回滚影响 | 会被回滚影响 |
| 统计数据 | 不创建统计数据,所以所有的估计行数都为1,所以生成执行计划会不精准 | 创建统计数据,通过实际的行数生成执行计划。 |
| 作为参数传入存储过程 | 仅仅在SQL Server2008, 并且必须预定义 user-defined table type. | 不允许 |
| 显式命名对象 (索引, 约束). | 不允许 | 允许,但是要注意多用户的问题 |
| 动态SQL | 必须在动态SQL中定义表变量 | 可以在调用动态SQL之前定义临时表 |
到此这篇关于SQL Server中使用表变量和临时表的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

sqlserver 临时表 Vs 表变量 详细介绍
这里我们在SQL Server 2005\SQL Server 2008版本上通过举例子,说明临时表和表变量两者的一些特征,让我们对临时表和表变量有进一步的认识.在本章中,我们将从下面几个方面去进行描述,对其中的一些特征举例子说明: 约束(Constraint) 索引(Index) I/0开销 作用域(scope) 存儲位置 其他 例子描述 约束(Constraint) 在临时表和表变量,都可以创建Constraint.针对表变量,只有定义时能加Constraint. e.g.在Microsof
-
SQLServer中临时表与表变量的区别分析
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢? 临时表 临时表与永久表相似,只是它的创建是在Tempdb中,它只有在一个数据库连接结束后或者由SQL命令DROP掉,才会消失,否则就会一直存在.临时表在创建的时候都会产生SQL Server的系统日志,虽它们在Tempdb中体现,是分配在内存中的,它们也支持物理的磁盘,但用户在指定的磁盘里看不到文件. 临时表分为本地
-
SQL Server 表变量和临时表的区别(详细补充篇)
一.表变量 表变量在SQL Server 2000中首次被引入.表变量的具体定义包括列定义,列名,数据类型和约束.而在表变量中可以使用的约束包括主键约束,唯一约束,NULL约束和CHECK约束(外键约束不能在表变量中使用).定义表变量的语句是和正常使用Create Table定义表语句的子集.只是表变量通过DECLARE @local_variable语句进行定义. 表变量的特征: 1.表变量拥有特定作用域(在当前批处理语句中,但不在任何当前批处理语句调用的存储过程和函数中),表变量在批处理结束
-
SQL Server中使用表变量和临时表
一.表变量 表变量在SQL Server 2000中首次被引入. 表变量的具体定义包括列定义,列名,数据类型和约束.而在表变量中可以使用的约束包括主键约束,唯一约束,NULL约束和CHECK约束(外键约束不能在表变量中使用). 定义表变量的语句是和正常使用Create Table定义表语句的子集.只是表变量通过DECLARE @local_variable语句进行定义. 1.定义和使用表变量 定义一个表变量,插入一条数据,然后查询: DECLARE @tb1 Table ( Id int, Na
-
sql server中判断表或临时表是否存在的方法
1.判断数据表是否存在 方法一: use yourdb; go if object_id(N'tablename',N'U') is not null print '存在' else print '不存在' 例如: use fireweb; go if object_id(N'TEMP_TBL',N'U') is not null print '存在' else print '不存在' 方法二: USE [实例名] GO IF EXISTS (SELECT * FROM dbo.SysObjec
-
在sql查询中使用表变量
复制代码 代码如下: USE [DAF_DB] GO /****** Object: StoredProcedure [dbo].[PROG_WORKTASK_List] Script Date: 06/14/2010 21:14:43 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO --[PROG_WORKTASK_List] 62,0,'','',0,0,'','' -- ===========================
-
SQL Server中数据行批量插入脚本的存储实现
无意中看到朋友写的一篇文章"将表里的数据批量生成INSERT语句的存储过程的实现".我仔细看文中的两个存储代码,自我感觉两个都不太满意,都是生成的单行模式的插入,数据行稍微大些性能会受影响的.所在公司本来就存在第二个版本的类似实现,但是是基于多行模式的,还是需要手工添加UNAION ALL来满足多行模式的插入.看到这篇博文和基于公司数据行批量脚本的存储的缺点,这次改写和增强该存储的功能. 本存储运行于SQL Server 2005或以上版本,T-SQL代码如下: IF OBJECT_I
-
SQL Server 中 RAISERROR 的用法详细介绍
SQL Server 中 RAISERROR 的用法 raiserror 的作用: raiserror 是用于抛出一个错误.[ 以下资料来源于sql server 2005的帮助 ] 其语法如下: RAISERROR ( { msg_id | msg_str | @local_variable } { ,severity ,state } [ ,argument [ ,...n ] ] ) [ WITH option [ ,...n ] ] 简要说明一下: 第一个参数:{ msg_id | ms
-
SQL Server中的XML数据进行insert、update、delete
SQL Server中新增加了XML.Modify()方法,分别为xml.modify(insert),xml.modify(delete),xml.modify(replace)对应XML的插入,删除和修改操作. 本文以下面XML为例,对三种DML进行说明: declare @XMLVar xml = ' <catalog> <book category="ITPro"> <title>Windows Step By Step</title&
-
SQL Server中的XML数据进行insert、update、delete操作实现代码
SQL Server中新增加了XML.Modify()方法,分别为xml.modify(insert),xml.modify(delete),xml.modify(replace)对应XML的插入,删除和修改操作. 本文以下面XML为例,对三种DML进行说明: 复制代码 代码如下: declare @XMLVar XML; SET @XMLVar= ' <catalog> <book category="ITPro"> <title>Windows
-
sql server中随机函数NewID()和Rand()
在SQL Server中,随机函数有rand(),NewID(),其中rand是在0到1内随机取数,NewID则是生成随机的uniqueidentifier唯一标识符. SELECT * FROM Northwind..Orders ORDER BY NEWID() --随机排序 SELECT TOP 10 * FROM Northwind..Orders ORDER BY NEWID() --从Orders表中随机取出10条记录 示例 A.对变量使用 NEWID 函数 以下示例使用 NEWID
-
SQL Server中关于基数估计计算预估行数的一些方法探讨
关于SQL Server 2014中的基数估计,官方文档Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator里有大量细节介绍,但是全部是英文,估计也没有几个人仔细阅读.那么SQL Server 2014中基数估计的预估行数到底是怎么计算的呢? 有哪一些规律呢?我们下面通过一些例子来初略了解一下,下面测试案例仅供参考,如有不足或肤浅的地方,敬请指教! 下面实验测试的环境主要为SQL Server 201
-
在SQL Server中实现最短路径搜索的解决方法
开始这是去年的问题了,今天在整理邮件的时候才发现这个问题,感觉顶有意思的,特记录下来. 在表RelationGraph中,有三个字段(ID,Node,RelatedNode),其中Node和RelatedNode两个字段描述两个节点的连接关系:现在要求,找出从节点"p"至节点"j",最短路径(即经过的节点最少). 图1. 解析: 了能够更好的描述表RelationGraph中字段Node和 RelatedNode的关系,我在这里特意使用一个图形来描述,如图2. 图2