深入SQL SERVER合并相关操作Union,Except,Intersect的详解
对于结果集有几个处理,值得讲解一下
1. 并集(union,Union all)
这个很简单,是把两个结果集水平合并起来。例如
SELECT * FROM A
UNION
SELECT * FROM B
【注意】union会删除重复值,也就是说A和B中重复的行,最终只会出现一次,而union all则会保留重复行。

2. 差异(Except)
就是两个集中不重复的部分。例如
SELECT * FROM A
EXCEPT
SELECT * FROM B
这个的意思是,凡是不出现在B表中的A表的行。
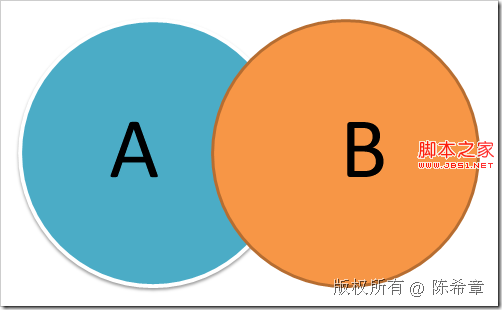
3. 交集(intersect)
就是两个集中共同的部分。例如
SELECT * FROM A
INTERSECT
SELECT * FROM B
这个的意思是,同时出现在A和B中的记录

相关推荐
-

深入SQL SERVER合并相关操作Union,Except,Intersect的详解
对于结果集有几个处理,值得讲解一下1. 并集(union,Union all)这个很简单,是把两个结果集水平合并起来.例如SELECT * FROM AUNIONSELECT * FROM B[注意]union会删除重复值,也就是说A和B中重复的行,最终只会出现一次,而union all则会保留重复行. 2. 差异(Except)就是两个集中不重复的部分.例如SELECT * FROM AEXCEPTSELECT * FROM B这个的意思是,凡是不出现在B表中的A表的行. 3. 交集(inte
-
SQL Server 树形表非循环递归查询的实例详解
很多人可能想要查询整个树形表关联的内容都会通过循环递归来查...事实上在微软在SQL2005或以上版本就能用别的语法进行查询,下面是示例. --通过子节点查询父节点 WITH TREE AS( SELECT * FROM Areas WHERE id = 6 -- 要查询的子 id UNION ALL SELECT Areas.* FROM Areas, TREE WHERE TREE.PId = Areas.Id ) SELECT Area FROM TREE --通过父节点查询子节点 WIT
-
SQL Server使用脚本实现自动备份的思路详解
因服务器安装的SQL Server版本不支持自动定时备份,需自行实现,大概思路为: 创建备份数据库的脚本 创建批处理脚本执行步骤一中的脚本 创建Windows定时任务执行步骤二中的脚本 1. 创建SQL脚本 新建db_backup.sql文件,填入以下内容. -- 定义需要备份的数据库 DECLARE @backupDatabase VARCHAR(20) = 'DB_NAME' -- 定义数据库备份文件存放的基础路径 DECLARE @backupBasePath VARCHAR(MAX) =
-
SQL Server CROSS APPLY和OUTER APPLY的应用详解
SQL Server数据库操作中,在2005以上的版本新增加了一个APPLY表运算符的功能.新增的APPLY表运算符把右表表达式应用到左表表达式中的每一行.它不像JOIN那样先计算那个表表达式都可以,APPLY必选先逻辑地计算左表达式.这种计算输入的逻辑顺序允许吧右表达式关联到左表表达式. APPLY有两种形式,一个是OUTER APPLY,一个是CROSS APPLY,区别在于指定OUTER,意味着结果集中将包含使右表表达式为空的左表表达式中的行,而指定CROSS,则相反,结果集中不包含使右表
-
SQL Server 2008 R2:error 26 开启远程连接详解
在学习ASP.NET 过程用到新建数据集并远程连接sql server 2008 数据库,出现下面的错误: <--在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误. 未找到或无法访问服务器.请验证实例名称是否正确并且 SQL Server 已配置为允许远程连接. (provider: SQL Network Interfaces, error: 26 - 定位指定的服务器/实例时出错)--> 因为sql server 2008默认是不允许远程连接的,sa帐
-
SQL Server如何通过创建临时表遍历更新数据详解
前言: 前段时间新项目上线为了赶进度很多模块的功能都没有经过详细的测试导致了生成环境中的数据和实际数据对不上,因此需要自己手写一个数据库脚本来更新下之前的数据.(线上数据库用是SQL Server2012)关于数据统计汇总的问题肯定会用到遍历统计汇总,那么问题来了数据库中如何遍历呢?好像并没有for和foreach这种类型的功能呀,不过关于数据库遍历最常见的方法当然是大家经常会想到的游标啦,但是这次我并没有使用游标,而是通过创建临时表的方式来更新遍历数据的. 为什么不使用游标,而使用创建临时表?
-
SQL Server 开窗函数 Over()代替游标的使用详解
前言: 今天在优化工作中遇到的sql慢的问题,发现以前用了挺多游标来处理数据,这样就导致在数据量多的情况下,需要一行一行去遍历从而计算需要的数据,这样处理的结果就是数据慢,容易卡死. 语法介绍: 1.与Row_Number() 函数结合使用,对结果进行排序,这个是我们使用的非常多的 2.与聚合函数结合使用,利用over子句的分组和排序,对需要的数据进行操作 例如:SUM() Over() 累加值.AVG() Over() 平均数 MAX() Over() 最大值.MIN() Over() 最小值
-
SQL SERVER 2012新增函数之逻辑函数CHOOSE详解
SQL SERVER 2012中新增了CHOOSE,该函数可以从值列表返回指定索引处的项. 例如: select CHOOSE(3,'A','B','C','D') as R1 /* R1 ---- C */ CHOOSE并不能这么用,例如有个字符串'A,B,C,D',我们并不能用choose得到其中的某个值: select choose(2,'A,B,C,D') /* null */ CHOOSE的主要功能和CASE WHEN类似,例如数据库中有字段Sex:1表示男,2表示女. if obje
-
SQL Server中row_number函数的常见用法示例详解
一.SQL Server Row_number函数简介 ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数. 行号以每个分区中第一行的行号开头. 以下是ROW_NUMBER()函数的语法实例: select *,row_number() over(partition by column1 order by column2) as n from tablename 在上面语法中: PARTITION BY子句将结果集划分为分区. ROW_NUMBER()函
-
SQL Server实现自动循环归档分区数据脚本详解
概述 大家应该都知道在很多业务场景下我们需要对一些记录量比较大的表进行分区,同时为了保证性能需要将一些旧的数据进行归档.在分区表很多的情况下如果每一次归档都需要人工干预的话工程量是比较大的而且也容易发生纰漏.接下来分享一个自己编写的自动归档分区数据的脚本,原理是分区表和归档表使用相同的分区方案,循环利用当前的文件组,话不多说了,来一起看看详细的介绍吧. 一.创建测试数据 ----01创建文件组 USE [master] GO ALTER DATABASE [chenmh] ADD FILEGRO