MySQL关键字Distinct的详细介绍
MySQL关键字Distinct用法介绍
DDL
Prepare SQL:
create table test(id bigint not null primary key auto_increment, name varchar(10) not null, phone varchar(10) not null, email varchar(30) not null)engine=innodb;
Prepare Data:
insert into test(name, phone, email)values('alibaba','0517','alibaba@alibaba.com');
insert into test(name, phone, email)values('alibaba','0517','alibaba@alibaba.com');
insert into test(name, phone, email)values('baidu','010','baidu@baidu.com');
insert into test(name, phone, email)values('tencent','0755','tencent@tencent.com');
insert into test(name, phone, email)values('vipshop','020','vipshop@vipshop.com');
insert into test(name, phone, email)values('ctrip','021','ctrip@ctrip.com');
insert into test(name, phone, email)values('suning','025','suning@suning.com');
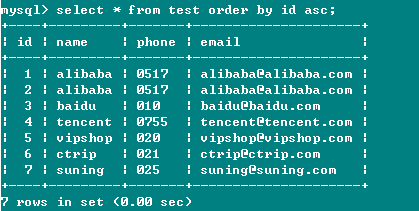
查询数据如下图所示:
第一种情况,使用Distinct关键字,查询单列数据,如下图所示:

结果:对 name 字段进行去重处理,符合预期期望,确实筛选掉了重复的字段值alibaba;
第二种情况,使用Distinct关键字(在前),查询多列数据,如下图所示:
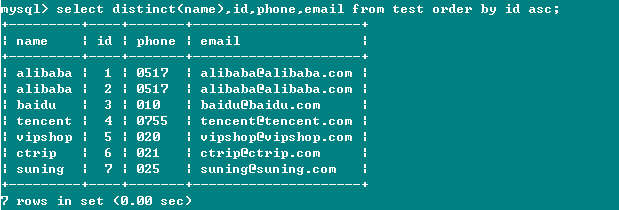
结果:对 name 字段进行去重处理,结果不符合预期期望,没有筛选掉重复的字段值alibaba;
第二种情况,使用Distinct关键字(在后),查询多列数据,如下图所示:

结果:对 name 字段进行去重处理,结果不符合预期期望,抛出SQL异常,错误码:1064;
解决办法:
不要用子查询,用分组来解决:

总结: SQL查询能用一条语句解决的尽量不要增加SQL的复杂度,特别是子查询!!!
以上就是关于MySQL关键字Distinct用法的讲解,如有疑问,请留言或者到本站设讨论,感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-
解析mysql中:单表distinct、多表group by查询去除重复记录
单表的唯一查询用:distinct多表的唯一查询用:group bydistinct 查询多表时,left join 还有效,全连接无效,在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重复记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的
-
MySQL中distinct语句的基本原理及其与group by的比较
DISTINCT 实际上和 GROUP BY 操作的实现非常相似,只不过是在 GROUP BY 之后的每组中只取出一条记录而已.所以,DISTINCT 的实现和 GROUP BY 的实现也基本差不多,没有太大的区别.同样可以通过松散索引扫描或者是紧凑索引扫描来实现,当然,在无法仅仅使用索引即能完成 DISTINCT 的时候,MySQL 只能通过临时表来完成.但是,和 GROUP BY 有一点差别的是,DISTINCT 并不需要进行排序.也就是说,在仅仅只是 DISTINCT 操作的 Query
-

MySQL中distinct与group by之间的性能进行比较
最近在网上看到了一些测试,感觉不是很准确,今天亲自测试了一番.得出了结论,测试过程在个人计算机上,可能不够全面,仅供参考. 测试过程: 准备一张测试表 CREATE TABLE `test_test` ( `id` int(11) NOT NULL auto_increment, `num` int(11) NOT NULL default '0', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1
-
MySQL中Distinct和Group By语句的基本使用教程
MySQL Distinct 去掉查询结果重复记录 DISTINCT 使用 DISTINCT 关键字可以去掉查询中某个字段的重复记录. 语法: SELECT DISTINCT(column) FROM tb_name 例子: 假定 user 表有如下记录: uid username 1 小李 2 小张 3 小李 4 小王 5 小李 6 小张 SQL 语句: SELECT DISTINCT(username) FROM user 返回查询结果如下: username 小李 小张 小王 提示 使用
-
MySQL中索引优化distinct语句及distinct的多字段操作
MySQL通常使用GROUPBY(本质上是排序动作)完成DISTINCT操作,如果DISTINCT操作和ORDERBY操作组合使用,通常会用到临时表.这样会影响性能. 在一些情况下,MySQL可以使用索引优化DISTINCT操作,但需要活学活用.本文涉及一个不能利用索引完成DISTINCT操作的实例. 实例1 使用索引优化DISTINCT操作 create table m11 (a int, b int, c int, d int, primary key(a)) engine=INNODB;
-
MySQL中distinct与group by语句的一些比较及用法讲解
在数据表中记录了用户验证时使用的书目,现在想取出所有书目,用DISTINCT和group by都取到了我想要的结果,但我发现返回结果排列不同,distinct会按数据存放顺序一条条显示,而group by会做个排序(一般是ASC). DISTINCT 实际上和 GROUP BY 操作的实现非常相似,只不过是在 GROUP BY 之后的每组中只取出一条记录而已.所以,DISTINCT 的实现和 GROUP BY 的实现也基本差不多,没有太大的区别,同样可以通过松散索引扫描或者是
-
使用distinct在mysql中查询多条不重复记录值的解决办法
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的.所以我花了很多时间来研究这个问题,网上也查不到解决方案,期间把容容拉来帮忙,结果是
-
分析MySQL中优化distinct的技巧
有这样的一个需求:select count(distinct nick) from user_access_xx_xx; 这条sql用于统计用户访问的uv,由于单表的数据量在10G以上,即使在user_access_xx_xx上加上nick的索引, 通过查看执行计划,也为全索引扫描,sql在执行的时候,会对整个服务器带来抖动: root@db 09:00:12>select count(distinct nick) from user_access; +--------+ | count(dis
-
MySQL中distinct语句去查询重复记录及相关的性能讨论
在 MySQL 查询中,可能会包含重复值.这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值. 关键词 DISTINCT 用于返回唯一不同的值,就是去重啦.用法也很简单: SELECT DISTINCT * FROM tableName DISTINCT 这个关键字来过滤掉多余的重复记录只保留一条. 另外,如果要对某个字段去重,可以试下: SELECT *, COUNT(DISTINCT nowamagic) FROM table GROUP BY nowamagic 这个用
-
MySQL中distinct和count(*)的使用方法比较
首先对于MySQL的DISTINCT的关键字的一些用法: 1.在count 不重复的记录的时候能用到,比如SELECT COUNT( DISTINCT id ) FROM tablename:就是计算talbebname表中id不同的记录有多少条. 2,在需要返回记录不同的id的具体值的时候可以用,比如SELECT DISTINCT id FROM tablename:返回talbebname表中不同的id的具体的值. 3.上面的情况2对于需要返回mysql表中2列以上的结果时会有歧义,比如SE