巧妙利用PARTITION分组排名递增特性解决合并连续相同数据行
问题提出
先造一些测试数据以说明题目:
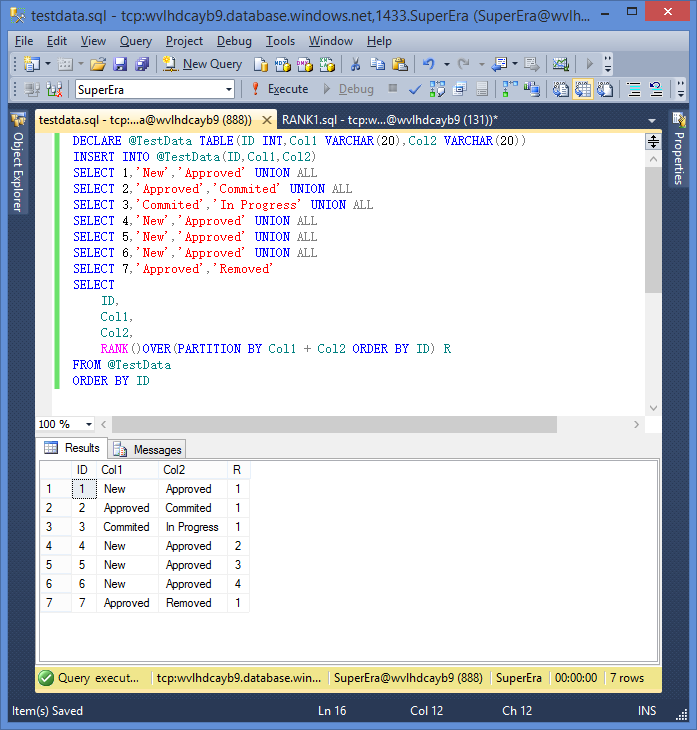
DECLARE @TestData TABLE(ID INT,Col1 VARCHAR(20),Col2 VARCHAR(20)) INSERT INTO @TestData(ID,Col1,Col2) SELECT 1,'New','Approved' UNION ALL SELECT 2,'Approved','Commited' UNION ALL SELECT 3,'Commited','In Progress' UNION ALL SELECT 4,'New','Approved' UNION ALL SELECT 5,'New','Approved' UNION ALL SELECT 6,'New','Approved' UNION ALL SELECT 7,'Approved','Removed' SELECT * FROM @TestData


数据说明,ID列连续自增,列1和列2都是TFS中PBI的状态记录,就是从什么变更到什么,如新建到批准,批准到提交神马的
现在要求连续且相同的状态变更记录合并,不连续或者不同的状态变更保留,例如:
以上图为例,ID为1,4,5,6的记录都是从New到Approved状态,但是记录1与记录4、5、6不相邻,或者说不连续,那么就要分成两组,
记录1一组,记录4、5、6一组,其它记录因为状态变更不相同所以全部保留,最后的查询结果应该长成下图这个样子:

继续之前你可以先自己试下,这可能会带来新的解题思路,
解题思路
该问题的关键在于GROUP BY会把记录1、4、5、6合并在一起,而这不符合要求,仅需要合并4、5、6,源表里没有这样一个字段可以将记录1与记录4、5、6区分开来,这是解题的关键
这里可以利用RANK函数配合使用PARTITION关键字,首先把1456分到一组去,同时产生一个组内排名的新字段R,这个排名R很关键,后边会用到,见下图:
RANK函数不了解的点这里
RANK函数以Col1 + Col2为分组条件,这样分成了四组,分别是New-Approved、Approved-Commited、Commited-In Progress、Approved-Removed
在New-Approved组内,记录1、4、5、6分别排名1、2、3、4;其它组内仅一条记录,在其组内排名均为1
现在制造了一个R字段,R字段标识了每条记录在其组内的排名,排名自1开始递增,
源表内ID自增,组内排名R递增,这就是解题的关键,
当连续相同的记录出现时,其ID与其排名R在同时递增,则其差值是相同的,拿到这个差值就可以很容易解决题目了,看下图:

记录4、5、6相同且连续出现,其ID与其排名在同时增长,其差值则保持不变,这里使用Col1 + Col2 + Gap作为分组条件即可将记录4、5、6合并,再取个最小ID出来,问题解决,完整脚本如下:

可是如果ID不连续时怎么办呢?这个不难,参考[MSSQL]ROW_NUMBER函数
相关推荐
-
分区软件PartitionMagic的使用方法(images)及注意事项
分区软件PartitionMagic的使用方法(images)及注意事项 一.调整分区容量 由于原来分区时考虑欠周.应用中有新的需要或要安装新的操作系统,经常会出现某个分区容量不够的情况,特别是C盘常常会被剩余空间不足所困扰,这时PartitionMagic就可以大显身手了. 1.选择硬盘和分区{ return imgzoom(this); }" onmouseover="function anonymous(){ if(this.width>screen.width*0.7)
-
Mysql数据表分区技术PARTITION浅析
在这一章节里, 我们来了解下 Mysql 中的分区技术 (RANGE, LIST, HASH) Mysql 的分区技术与水平分表有点类似, 但是它是在逻辑层进行的水平分表, 对于应用而言它还是一张表, 换句话说: 分区不是实际真正的对一张表进行拆分,分区之后表还是一个表,它是把存储文件进行拆分. 在 Mysql 5.1(后) 有了几种分区类型: RANGE分区: 基于属于一个给定连续区间的列值, 把多行分配给分区 LIST分区: 类似于按 RANGE 分区, 区别在于 LIST 分区是基
-
sqlserver巧用row_number和partition by分组取top数据
分组取TOP数据是T-SQL中的常用查询, 如学生信息管理系统中取出每个学科前3名的学生.这种查询在SQL Server 2005之前,写起来很繁琐,需要用到临时表关联查询才能取到.SQL Server 2005后之后,引入了row_number()函数,row_number()函数的分组排序功能使这种操作变得非常简单.下面是一个简单示例: 复制代码 代码如下: --1.创建测试表 create table #score ( name varchar(20), subject varchar(2
-

巧妙利用PARTITION分组排名递增特性解决合并连续相同数据行
问题提出 先造一些测试数据以说明题目: DECLARE @TestData TABLE(ID INT,Col1 VARCHAR(20),Col2 VARCHAR(20)) INSERT INTO @TestData(ID,Col1,Col2) SELECT 1,'New','Approved' UNION ALL SELECT 2,'Approved','Commited' UNION ALL SELECT 3,'Commited','In Progress' UNION ALL SELECT
-
PHP利用header跳转失效的解决方法
本文实例讲述了PHP利用header跳转失效的解决方法,分享给大家供大家参考.具体方法分析如下: 一.问题: 今天header(\"Location: $url\"),以往跳转总是可以的,今天却不动,只是输出结果,以往自己要确认检查,$url的值获取的是否正确,所以在前面加了echo $url:来调试用,结果就导致了header函数的无效. 二.解决方法: 在PHP中用header("location:test.php")进行跳转要注意以下几点: 1.locatio
-
PHP巧妙利用位运算实现网站权限管理的方法
首先我们先定义4个常量来设定四种权限: ===================================== define(ADD,1);//增加数据库记录的权限 define(UPD,2);//修改数据库记录的权限 define(SEL,4);//查找数据库记录的权限 define(DEL,8);//删除数据库记录的权限 ===================================== 接下来假设有3个用户: A用户拥有ADD-UPD-SEL-DEL四个权限,用位或运算计算A的
-
Mysql教程分组排名实现示例详解
目录 1.数据源 2.数据整体排名 1)普通排名 2)并列排名 3)并列排名 3.数据分组后组内排名 1)分组普通排名 2)分组后并列排名 3)分组后并列排名 4.分组后取各组的前两名 1.数据源 2.数据整体排名 1)普通排名 从1开始,按照顺序一次往下排(相同的值也是不同的排名). set @rank =0; select city , score, @rank := @rank+1 rank from cs order by score desc; 结果如下: 2)并列排名 相同的值是相同
-
MySql分组后随机获取每组一条数据的操作
思路:先随机排序然后再分组就好了. 1.创建表: CREATE TABLE `xdx_test` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `class` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2.插入数据 INSERT INTO xdx_test VALUES (1, '张三-1','
-
C++解决合并两个排序的链表问题
目录 题目描述: 示例: 解题思路: 测试代码: 题目描述: 输入两个递增的链表,单个链表的长度为n,合并这两个链表并使新链表中的节点仍然是递增排序的. 数据范围: n为0~1000,节点值为-1000~1000 要求:空间复杂度 O(1),时间复杂度 O(n) 如输入{1,3,5},{2,4,6}时,合并后的链表为{1,2,3,4,5,6},所以对应的输出为{1,2,3,4,5,6},转换过程如下图所示: 或输入{-1,2,4},{1,3,4}时,合并后的链表为{-1,1,2,3,4,4},所
-
php 利用array_slice函数获取随机数组或前几条数据
先给大家说下基本语法: array_slice ( array $array , int $offset [, int $length [, bool $preserve_keys ]] ) array_slice() 返回根据 offset 和 length 参数所指定的 array 数组中的一段序列. 如果 offset 非负,则序列将从 array 中的此偏移量开始.如果 offset 为负,则序列将从 array 中距离末端这么远的地方开始. 如果给出了 length 并且为正,则序列中
-
解决PHP里大量数据循环时内存耗尽的方法
最近在开发一个PHP程序的时候遇到如下一问题: PHP Fatal error: Allowed memory size of 268 435 456 bytes exhausted 错误信息显示允许的最大内存已经耗尽.遇到这样的错误起初让我很诧异,但转眼一想,也不奇怪,因为我正在开发的这个程序是要用一个foreach循环语句在一个有4万条记录的表里全表搜索具有特定特征的数据,也就是说,一次要把4万条数据取出,然后逐条检查每天数据.可想而知,4万条数据全部加载到内存中,内存不爆才怪. 毕竟编程这
-
解决Mysql数据库插入数据出现问号(?)的解决办法
首先,我用的mysql数据库是5.7.12版本. 出现的问题: 1.插入数据显示错误,插入不成功,出现:Incorrect string value: '\xCD\xF5\xD5\xBC\xBE\xA9' for column 'Sname' at row 1 2.插入中文,虽然插入成功,但是显示:?? 解决方法: 在my.ini文件中的 [mysqld] 中加入 #character-set-server=utf8 如图所示,必须在蓝圈的上方,就是说,蓝圈内的内容必须在[mysqld]的最下面
-
Python利用字典将两个通讯录文本合并为一个文本实例
本文实例主要实现的是利用字典将两个通讯录文本合并为一个文本,具体代码如下: def main(): ftele1=open("d:\TeleAddressBook.txt","rb") ftele2=open("d:\EmailAddressBook.txt","rb") ftele1.readline()#跳过第一行 ftele2.readline() lines1=ftele1.readlines() lines2=fte