Java concurrency集合之ConcurrentSkipListMap_动力节点Java学院整理
ConcurrentSkipListMap介绍
ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景。
ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表。但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。
关于跳表(Skip List),它是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
ConcurrentSkipListMap原理和数据结构
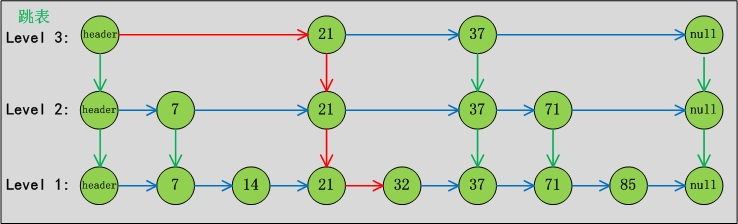
ConcurrentSkipListMap的数据结构,如下图所示:

说明:
先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
情况1:链表中查找“32”节点
路径如下图1-02所示:

需要4步(红色部分表示路径)。
情况2:跳表中查找“32”节点
路径如下图1-03所示:
忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。
下面说说Java中ConcurrentSkipListMap的数据结构。
(01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。
(02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。
(03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。
ConcurrentSkipListMap函数列表
// 构造一个新的空映射,该映射按照键的自然顺序进行排序。 ConcurrentSkipListMap() // 构造一个新的空映射,该映射按照指定的比较器进行排序。 ConcurrentSkipListMap(Comparator<? super K> comparator) // 构造一个新映射,该映射所包含的映射关系与给定映射包含的映射关系相同,并按照键的自然顺序进行排序。 ConcurrentSkipListMap(Map<? extends K,? extends V> m) // 构造一个新映射,该映射所包含的映射关系与指定的有序映射包含的映射关系相同,使用的顺序也相同。 ConcurrentSkipListMap(SortedMap<K,? extends V> m) // 返回与大于等于给定键的最小键关联的键-值映射关系;如果不存在这样的条目,则返回 null。 Map.Entry<K,V> ceilingEntry(K key) // 返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。 K ceilingKey(K key) // 从此映射中移除所有映射关系。 void clear() // 返回此 ConcurrentSkipListMap 实例的浅表副本。 ConcurrentSkipListMap<K,V> clone() // 返回对此映射中的键进行排序的比较器;如果此映射使用键的自然顺序,则返回 null。 Comparator<? super K> comparator() // 如果此映射包含指定键的映射关系,则返回 true。 boolean containsKey(Object key) // 如果此映射为指定值映射一个或多个键,则返回 true。 boolean containsValue(Object value) // 返回此映射中所包含键的逆序 NavigableSet 视图。 NavigableSet<K> descendingKeySet() // 返回此映射中所包含映射关系的逆序视图。 ConcurrentNavigableMap<K,V> descendingMap() // 返回此映射中所包含的映射关系的 Set 视图。 Set<Map.Entry<K,V>> entrySet() // 比较指定对象与此映射的相等性。 boolean equals(Object o) // 返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry<K,V> firstEntry() // 返回此映射中当前第一个(最低)键。 K firstKey() // 返回与小于等于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。 Map.Entry<K,V> floorEntry(K key) // 返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。 K floorKey(K key) // 返回指定键所映射到的值;如果此映射不包含该键的映射关系,则返回 null。 V get(Object key) // 返回此映射的部分视图,其键值严格小于 toKey。 ConcurrentNavigableMap<K,V> headMap(K toKey) // 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。 ConcurrentNavigableMap<K,V> headMap(K toKey, boolean inclusive) // 返回与严格大于给定键的最小键关联的键-值映射关系;如果不存在这样的键,则返回 null。 Map.Entry<K,V> higherEntry(K key) // 返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。 K higherKey(K key) // 如果此映射未包含键-值映射关系,则返回 true。 boolean isEmpty() // 返回此映射中所包含键的 NavigableSet 视图。 NavigableSet<K> keySet() // 返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry<K,V> lastEntry() // 返回映射中当前最后一个(最高)键。 K lastKey() // 返回与严格小于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。 Map.Entry<K,V> lowerEntry(K key) // 返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。 K lowerKey(K key) // 返回此映射中所包含键的 NavigableSet 视图。 NavigableSet<K> navigableKeySet() // 移除并返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry<K,V> pollFirstEntry() // 移除并返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。 Map.Entry<K,V> pollLastEntry() // 将指定值与此映射中的指定键关联。 V put(K key, V value) // 如果指定键已经不再与某个值相关联,则将它与给定值关联。 V putIfAbsent(K key, V value) // 从此映射中移除指定键的映射关系(如果存在)。 V remove(Object key) // 只有目前将键的条目映射到给定值时,才移除该键的条目。 boolean remove(Object key, Object value) // 只有目前将键的条目映射到某一值时,才替换该键的条目。 V replace(K key, V value) // 只有目前将键的条目映射到给定值时,才替换该键的条目。 boolean replace(K key, V oldValue, V newValue) // 返回此映射中的键-值映射关系数。 int size() // 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。 ConcurrentNavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) // 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。 ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey) // 返回此映射的部分视图,其键大于等于 fromKey。 ConcurrentNavigableMap<K,V> tailMap(K fromKey) // 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。 ConcurrentNavigableMap<K,V> tailMap(K fromKey, boolean inclusive) // 返回此映射中所包含值的 Collection 视图。 Collection<V> values()
下面从ConcurrentSkipListMap的添加,删除,获取这3个方面对它进行分析。
1. 添加
下面以put(K key, V value)为例,对ConcurrentSkipListMap的添加方法进行说明。
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
实际上,put()是通过doPut()将key-value键值对添加到ConcurrentSkipListMap中的。
doPut()的源码如下:
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为“key的前继节点的后继节点”,即n应该是“插入节点”的“后继节点”
Node<K,V> n = b.next;
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
// 如果两次获得的b.next不是相同的Node,就跳转到”外层for循环“,重新获得b和n后再遍历。
if (n != b.next)
break;
// v是“n的值”
Object v = n.value;
// 当n的值为null(意味着其它线程删除了n);此时删除b的下一个节点,然后跳转到”外层for循环“,重新获得b和n后再遍历。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// 如果其它线程删除了b;则跳转到”外层for循环“,重新获得b和n后再遍历。
if (v == n || b.value == null) // b is deleted
break;
// 比较key和n.key
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
// 新建节点(对应是“要插入的键值对”)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 设置“b的后继节点”为z
if (!b.casNext(n, z))
break; // 多线程情况下,break才可能发生(其它线程对b进行了操作)
// 随机获取一个level
// 然后在“第1层”到“第level层”的链表中都插入新建节点
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
说明:doPut() 的作用就是将键值对添加到“跳表”中。
要想搞清doPut(),首先要弄清楚它的主干部分 —— 我们先单纯的只考虑“单线程的情况下,将key-value添加到跳表中”,即忽略“多线程相关的内容”。它的流程如下:
第1步:找到“插入位置”。
即,找到“key的前继节点(b)”和“key的后继节点(n)”;key是要插入节点的键。
第2步:新建并插入节点。
即,新建节点z(key对应的节点),并将新节点z插入到“跳表”中(设置“b的后继节点为z”,“z的后继节点为n”)。
第3步:更新跳表。
即,随机获取一个level,然后在“跳表”的第1层~第level层之间,每一层都插入节点z;在第level层之上就不再插入节点了。若level数值大于“跳表的层次”,则新建一层。
主干部分“对应的精简后的doPut()的代码”如下(仅供参考):
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为key的后继节点
Node<K,V> n = b.next;
for (;;) {
// 新建节点(对应是“要被插入的键值对”)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 设置“b的后继节点”为z
b.casNext(n, z);
// 随机获取一个level
// 然后在“第1层”到“第level层”的链表中都插入新建节点
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
理清主干之后,剩余的工作就相对简单了。主要是上面几步的对应算法的具体实现,以及多线程相关情况的处理!
2. 删除
下面以remove(Object key)为例,对ConcurrentSkipListMap的删除方法进行说明。
public V remove(Object key) {
return doRemove(key, null);
}
实际上,remove()是通过doRemove()将ConcurrentSkipListMap中的key对应的键值对删除的。
doRemove()的源码如下:
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key的前继节点”
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
// f是“当前节点n的后继节点”
Node<K,V> f = n.next;
// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (n != b.next) // inconsistent read
break;
// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// 如果“前继节点b”被删除(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c < 0)
return null;
if (c > 0) {
b = n;
n = f;
continue;
}
// 以下是c=0的情况
if (value != null && !value.equals(v))
return null;
// 设置“当前节点n”的值为null
if (!n.casValue(v, null))
break;
// 设置“b的后继节点”为f
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // Retry via findNode
else {
// 清除“跳表”中每一层的key节点
findPredecessor(key); // Clean index
// 如果“表头的右索引为空”,则将“跳表的层次”-1。
if (head.right == null)
tryReduceLevel();
}
return (V)v;
}
}
}
说明:doRemove()的作用是删除跳表中的节点。
和doPut()一样,我们重点看doRemove()的主干部分,了解主干部分之后,其余部分就非常容易理解了。下面是“单线程的情况下,删除跳表中键值对的步骤”:
第1步:找到“被删除节点的位置”。
即,找到“key的前继节点(b)”,“key所对应的节点(n)”,“n的后继节点f”;key是要删除节点的键。
第2步:删除节点。
即,将“key所对应的节点n”从跳表中移除 -- 将“b的后继节点”设为“f”!
第3步:更新跳表。
即,遍历跳表,删除每一层的“key节点”(如果存在的话)。如果删除“key节点”之后,跳表的层次需要-1;则执行相应的操作!
主干部分“对应的精简后的doRemove()的代码”如下(仅供参考):
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key的前继节点”
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
// f是“当前节点n的后继节点”
Node<K,V> f = n.next;
// 设置“当前节点n”的值为null
n.casValue(v, null);
// 设置“b的后继节点”为f
b.casNext(n, f);
// 清除“跳表”中每一层的key节点
findPredecessor(key);
// 如果“表头的右索引为空”,则将“跳表的层次”-1。
if (head.right == null)
tryReduceLevel();
return (V)v;
}
}
}
3. 获取
下面以get(Object key)为例,对ConcurrentSkipListMap的获取方法进行说明。
public V get(Object key) {
return doGet(key);
}
doGet的源码如下:
private V doGet(Object okey) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key对应的节点”
Node<K,V> n = findNode(key);
if (n == null)
return null;
Object v = n.value;
if (v != null)
return (V)v;
}
}
说明:doGet()是通过findNode()找到并返回节点的。
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
// 如果“n为null”,则跳转中不存在key对应的节点,直接返回null。
if (n == null)
return null;
Node<K,V> f = n.next;
// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (n != b.next) // inconsistent read
break;
Object v = n.value;
// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
// 若n是当前节点,则返回n。
int c = key.compareTo(n.key);
if (c == 0)
return n;
// 若“节点n的key”小于“key”,则说明跳表中不存在key对应的节点,返回null
if (c < 0)
return null;
// 若“节点n的key”大于“key”,则更新b和n,继续查找。
b = n;
n = f;
}
}
}
说明:findNode(key)的作用是在返回跳表中key对应的节点;存在则返回节点,不存在则返回null。
先弄清函数的主干部分,即抛开“多线程相关内容”,单纯的考虑单线程情况下,从跳表获取节点的算法。
第1步:找到“被删除节点的位置”。
根据findPredecessor()定位key所在的层次以及找到key的前继节点(b),然后找到b的后继节点n。
第2步:根据“key的前继节点(b)”和“key的前继节点的后继节点(n)”来定位“key对应的节点”。
具体是通过比较“n的键值”和“key”的大小。如果相等,则n就是所要查找的键。
ConcurrentSkipListMap示例
import java.util.*;
import java.util.concurrent.*;
/*
* ConcurrentSkipListMap是“线程安全”的哈希表,而TreeMap是非线程安全的。
*
* 下面是“多个线程同时操作并且遍历map”的示例
* (01) 当map是ConcurrentSkipListMap对象时,程序能正常运行。
* (02) 当map是TreeMap对象时,程序会产生ConcurrentModificationException异常。
*
* @author skywang
*/
public class ConcurrentSkipListMapDemo1 {
// TODO: map是TreeMap对象时,程序会出错。
//private static Map<String, String> map = new TreeMap<String, String>();
private static Map<String, String> map = new ConcurrentSkipListMap<String, String>();
public static void main(String[] args) {
// 同时启动两个线程对map进行操作!
new MyThread("a").start();
new MyThread("b").start();
}
private static void printAll() {
String key, value;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
value = (String)entry.getValue();
System.out.print("("+key+", "+value+"), ");
}
System.out.println();
}
private static class MyThread extends Thread {
MyThread(String name) {
super(name);
}
@Override
public void run() {
int i = 0;
while (i++ < 6) {
// “线程名” + "序号"
String val = Thread.currentThread().getName()+i;
map.put(val, "0");
// 通过“Iterator”遍历map。
printAll();
}
}
}
}
(某一次)运行结果:
(a1, 0), (a1, 0), (b1, 0), (b1, 0), (a1, 0), (b1, 0), (b2, 0), (a1, 0), (a1, 0), (a2, 0), (a2, 0), (b1, 0), (b1, 0), (b2, 0), (b2, 0), (b3, 0), (b3, 0), (a1, 0), (a2, 0), (a3, 0), (a1, 0), (b1, 0), (a2, 0), (b2, 0), (a3, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (a1, 0), (b3, 0), (a2, 0), (b4, 0), (a3, 0), (a1, 0), (a4, 0), (a2, 0), (b1, 0), (a3, 0), (b2, 0), (a4, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (a1, 0), (b4, 0), (a2, 0), (b5, 0), (a3, 0), (a1, 0), (a4, 0), (a2, 0), (a5, 0), (a3, 0), (b1, 0), (a4, 0), (b2, 0), (a5, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (b6, 0), (b4, 0), (a1, 0), (b5, 0), (a2, 0), (b6, 0), (a3, 0), (a4, 0), (a5, 0), (a6, 0), (b1, 0), (b2, 0), (b3, 0), (b4, 0), (b5, 0), (b6, 0),
结果说明:
示例程序中,启动两个线程(线程a和线程b)分别对ConcurrentSkipListMap进行操作。以线程a而言,它会先获取“线程名”+“序号”,然后将该字符串作为key,将“0”作为value,插入到ConcurrentSkipListMap中;接着,遍历并输出ConcurrentSkipListMap中的全部元素。 线程b的操作和线程a一样,只不过线程b的名字和线程a的名字不同。
当map是ConcurrentSkipListMap对象时,程序能正常运行。如果将map改为TreeMap时,程序会产生ConcurrentModificationException异常。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

详解javaweb中jstl如何循环List中的Map数据
详解javaweb中jstl如何循环List中的Map数据 第一种方式: 1:后台代码(测试) List<Map<String, Object>> list = new ArrayList<Map<String,Object>>(); Map<String, Object> map = null; for (int i = 0; i < 4; i++) { map = new HashMap<String, Object>();
-
Struts2中ognl遍历数组,list和map方法详解
一.简介 <s:iterator />可以遍历数据栈里面的任何数组,集合等等 在使用这个标签的时候有三个属性值得我们关注 1. value属性:可选的属性,value属性是指一个被迭代的集合,使用ognl表达式指定,如果为空的话默认就是ValueStack栈顶的集合. 2.id属性:可选属性, 是指集合元素的id 3.status属性:可选属性,该属性在迭代时会产生一个IteratorStatus对象,该对象可以判断当前元素的位置,包含了以下属性方法: int getCount(); 迭代元素
-
java list,set,map,数组间的相互转换详解
java list,set,map,数组间的相互转换详解 1.list转set Set set = new HashSet( new ArrayList()); 2.set转list List list = new ArrayList( new HashSet()); 3.数组转为list List stooges = Arrays.asList( "Larry" , "Moe" , "Curly" ); 此时stooges中有有三个元素.注意
-
java 三种将list转换为map的方法详解
java 三种将list转换为map的方法详解 在本文中,介绍三种将list转换为map的方法: 1) 传统方法 假设有某个类如下 class Movie { private Integer rank; private String description; public Movie(Integer rank, String description) { super(); this.rank = rank; this.description = description; } public Int
-
详解Java中list,set,map的遍历与增强for循环
详解Java中list,set,map的遍历与增强for循环 Java集合类可分为三大块,分别是从Collection接口延伸出的List.Set和以键值对形式作存储的Map类型集合. 关于增强for循环,需要注意的是,使用增强for循环无法访问数组下标值,对于集合的遍历其内部采用的也是Iterator的相关方法.如果只做简单遍历读取,增强for循环确实减轻不少的代码量. 集合概念: 1.作用:用于存放对象 2.相当于一个容器,里面包含着一组对象,其中的每个对象作为集合的一个元素出现 3.jav
-
Java如何在List或Map遍历过程中删除元素
遍历删除List或Map中的元素有很多种方法,当运用不当的时候就会产生问题.下面通过这篇文章来再学习学习吧. 一.List遍历过程中删除元素 使用索引下标遍历的方式 示例:删除列表中的2 public static void main(String[] args) { List<Integer> list = new ArrayList<Integer>(); list.add(1); list.add(2); list.add(2); list.add(3); list.add(
-
详解 Spring注解的(List&Map)特殊注入功能
详解 Spring注解的(List&Map)特殊注入功能 最近接手一个新项目,已经没有原开发人员维护了.项目框架是基于spring boot进行开发.其中有两处Spring的注解花费了大量的时间才弄明白到底是怎么用的,这也涉及到spring注解的一个特殊的注入功能. 首先,看到代码中有直接注入一个List和一个Map的.示例代码如下: @Autowired private List<DemoService> demoServices; @Autowired private Map<
-
jstl之map,list访问遍历以及el表达式map取值的实现
场景: request域里的数据为Map<Role, Map<String, List<Menu>>>,Role为枚举类型,为用户的Role那么访问遍历如下: <c:set var="user" value="${session_usr_key}" /> <c:forEach items="${roleMenuMap[user.role]}" var="entry">
-
Java concurrency集合之ConcurrentSkipListMap_动力节点Java学院整理
ConcurrentSkipListMap介绍 ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景. ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表.但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的.第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的. 关于跳表(Skip List),它是平衡树的一种
-
Java concurrency集合之ConcurrentHashMap_动力节点Java学院整理
ConcurrentHashMap介绍 ConcurrentHashMap是线程安全的哈希表.HashMap, Hashtable, ConcurrentHashMap之间的关联如下: HashMap是非线程安全的哈希表,常用于单线程程序中. Hashtable是线程安全的哈希表,它是通过synchronized来保证线程安全的:即,多线程通过同一个"对象的同步锁"来实现并发控制.Hashtable在线程竞争激烈时,效率比较低(此时建议使用ConcurrentHashMap)!因为当一
-
Java concurrency集合之LinkedBlockingDeque_动力节点Java学院整理
LinkedBlockingDeque介绍 LinkedBlockingDeque是双向链表实现的双向并发阻塞队列.该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除):并且,该阻塞队列是支持线程安全. 此外,LinkedBlockingDeque还是可选容量的(防止过度膨胀),即可以指定队列的容量.如果不指定,默认容量大小等于Integer.MAX_VALUE. LinkedBlockingDeque原理和数据结构 LinkedBlockingDeque
-
Java concurrency集合之CopyOnWriteArraySet_动力节点Java学院整理
CopyOnWriteArraySet介绍 它是线程安全的无序的集合,可以将它理解成线程安全的HashSet.有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet:但是,HashSet是通过"散列表(HashMap)"实现的,而CopyOnWriteArraySet则是通过"动态数组(CopyOnWriteArrayList)"实现的,并不是散列表. 和CopyOnWriteArrayList类似,CopyO
-
Java concurrency集合之ConcurrentLinkedQueue_动力节点Java学院整理
ConcurrentLinkedQueue介绍 ConcurrentLinkedQueue是线程安全的队列,它适用于"高并发"的场景. 它是一个基于链接节点的无界线程安全队列,按照 FIFO(先进先出)原则对元素进行排序.队列元素中不可以放置null元素(内部实现的特殊节点除外). ConcurrentLinkedQueue原理和数据结构 ConcurrentLinkedQueue的数据结构,如下图所示: 说明: 1. ConcurrentLinkedQueue继承于AbstractQ
-
Java concurrency集合之ConcurrentSkipListSet_动力节点Java学院整理
ConcurrentSkipListSet介绍 ConcurrentSkipListSet是线程安全的有序的集合,适用于高并发的场景. ConcurrentSkipListSet和TreeSet,它们虽然都是有序的集合.但是,第一,它们的线程安全机制不同,TreeSet是非线程安全的,而ConcurrentSkipListSet是线程安全的.第二,ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,而TreeSet是通过TreeMap实现的. Con
-
Java concurrency集合之ArrayBlockingQueue_动力节点Java学院整理
ArrayBlockingQueue介绍 ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列. 线程安全是指,ArrayBlockingQueue内部通过"互斥锁"保护竞争资源,实现了多线程对竞争资源的互斥访问.而有界,则是指ArrayBlockingQueue对应的数组是有界限的. 阻塞队列,是指多线程访问竞争资源时,当竞争资源已被某线程获取时,其它要获取该资源的线程需要阻塞等待:而且,ArrayBlockingQueue是按 FIFO(先进先出)原则对元素进行
-
Java concurrency集合之 CopyOnWriteArrayList_动力节点Java学院整理
CopyOnWriteArrayList介绍 它相当于线程安全的ArrayList.和ArrayList一样,它是个可变数组:但是和ArrayList不同的时,它具有以下特性: 1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突. 2. 它是线程安全的. 3. 因为通常需要复制整个基础数组,所以可变操作(add().set() 和 remove() 等等)的开销很大. 4. 迭代器支持hasNext(), next()等不可
-
Java concurrency之锁_动力节点Java学院整理
根据锁的添加到Java中的时间,Java中的锁,可以分为"同步锁"和"JUC包中的锁". 同步锁 即通过synchronized关键字来进行同步,实现对竞争资源的互斥访问的锁.Java 1.0版本中就已经支持同步锁了. 同步锁的原理是,对于每一个对象,有且仅有一个同步锁:不同的线程能共同访问该同步锁.但是,在同一个时间点,该同步锁能且只能被一个线程获取到.这样,获取到同步锁的线程就能进行CPU调度,从而在CPU上执行:而没有获取到同步锁的线程,必须进行等待,直到获取
-
Java中StringBuffer和StringBuilder_动力节点Java学院整理
下面先给大家介绍下String.StringBuffer.StringBuilder区别,具体详情如下所示: StringBuffer.StringBuilder和String一样,也用来代表字符串.String类是不可变类,任何对String的改变都 会引发新的String对象的生成:StringBuffer则是可变类,任何对它所指代的字符串的改变都不会产生新的对象.既然可变和不可变都有了,为何还有一个StringBuilder呢?相信初期的你,在进行append时,一般都会选择StringB