wkhtmltopdf 最好用Html转pdf的工具
实习时公司需要把一些html页面中的部分内容生成pdf文件,然后我就找一些用php把html页面围成pdf文件的类。方法是可谓是找了很多很多,什么html2pdf,pdflib,FPDF这些都试过了,但是都没有达到我要的求(主要是不能解决中文乱码的问题以及样式排版的问题)。
pdflib,FPDF 这两个方法是需要编写程序去生成pdf的,就也是讲不支持直接把html页面转换成pdf;html2pdf这个虽然可以把html页面转换成pdf文 件,但是它只能转换一般简单的html代码,如果你的html内容要的是通过后台新闻编辑器排版的那肯定不行的。
纠结了半天,什么百度,谷歌搜索都用了,搜索了半天,功夫不负有心人,终于找到一个非常好用的方法了,下面就隆重介绍。
它就 是:wkhtmltopdf,wkhtmltopdf可以直接把任何一个可以在浏览器中浏览的网页直接转换成一个pdf,首先说明一下它不是一个php 类,而是一个把html页面转换成pdf的一个软件(需要安装在服务器上),但是它并不是一个简单的桌面软件,而且它直接cmd批处理的,使用php中的 shell_exec()函数就可以调用它。下面就介绍如何用php+js+html来让它生成pdf文件的方法(不过有个缺陷就是他需要在服务器端生成一个缓存文件,如果你使用thinkphp框架的话就可以将其缓存文件放在runtime 文件夹中暂存就行)。
一,下载并安装wkhtmltopdf
1、下载地址:http://wkhtmltopdf.org/downloads.html 如图:
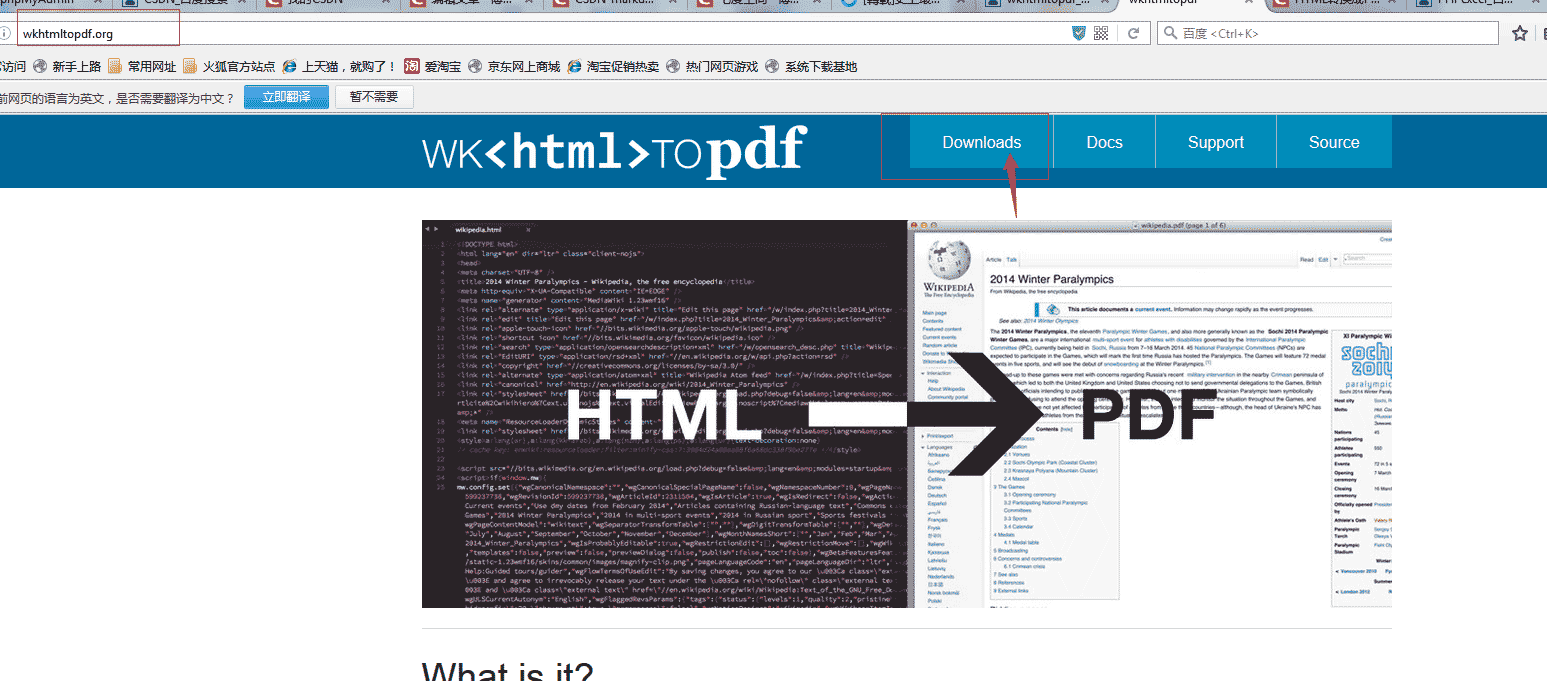
2、上面有各种平台下安装的安装包,英文不好的直接谷歌翻译一下。下面以 windows7平台上使用举例,我的下载的是stable(稳定版)的wkhtmltopdf-0.12.3.2-installer.exe这个版本,我在win7、win8 32位和64位以及win-sever上安装测试都没有问题的,系统时几位就下载几位的安装包。下载好以后直接安装就可以了,注意安装路径要知道,下面会用到的。
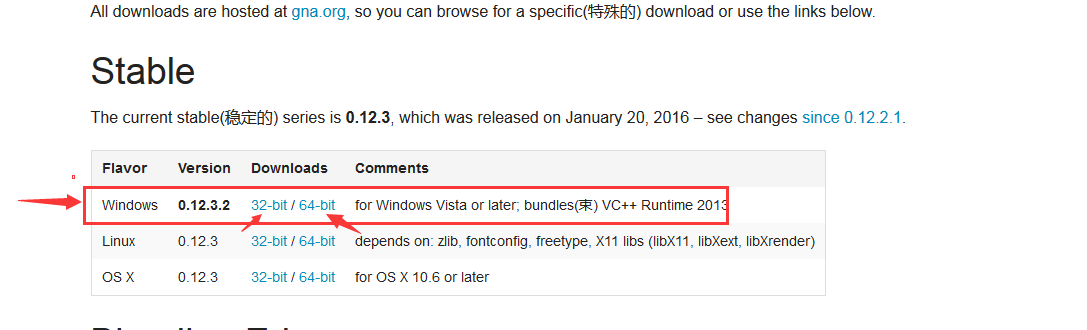
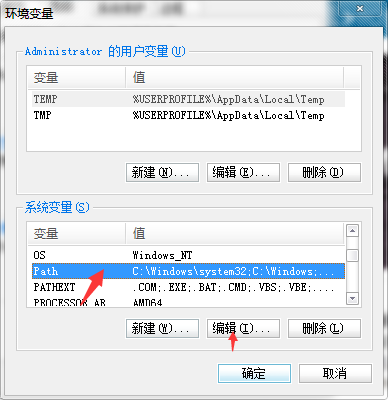
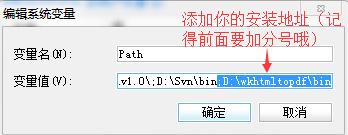
3、安装好以后需要在系统环境变量变量名为”Path”的后添加:;D:\wkhtmltopdf\bin 也就是你安装的目录。安装好以后重启电脑。
下图是如何设置环境变量:
打开我的电脑右键属性
点击高级系统设置
找到高级里面点击环境变量
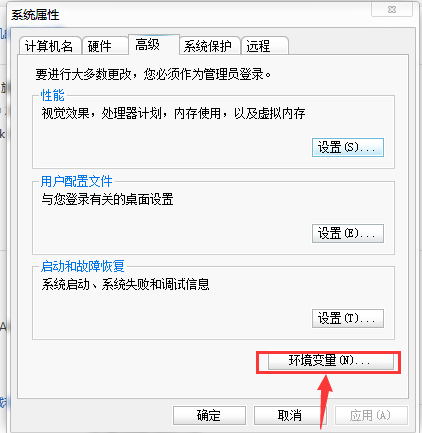
找到系统变量中的path,点击编辑,将刚刚的安装位置复制到最后,记得前面加一个分号哦!
二,测试使用效果
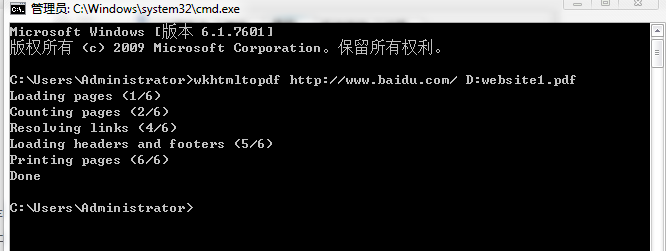
直接在cmd里输入:wkhtmltopdf http://www.baidu.com/ D:website1.pdf(注意中间有空格哈)
第一个是:运行软件名称(这个是不变的) 第二个是网址 第三个是生成后的路径及文件名。回车后是不是看生一个生成进度条的提示呢,恭喜您已经成功了,到你的生成目录里看看是不是有一个刚生成的pdf文件呢。
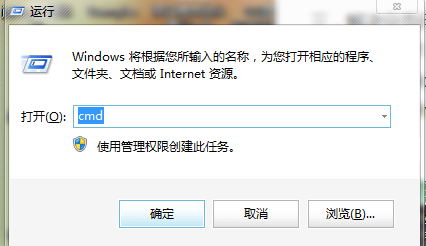
操作方法:1、windows键+r打开搜索框,输入cmd,点击确定
2、直接在cmd里输入:wkhtmltopdf http://www.baidu.com/ D:website1.pdf(注意中间有空格哈)

3、点击回车后,会看到一个进度条,然后就提示转换成功!
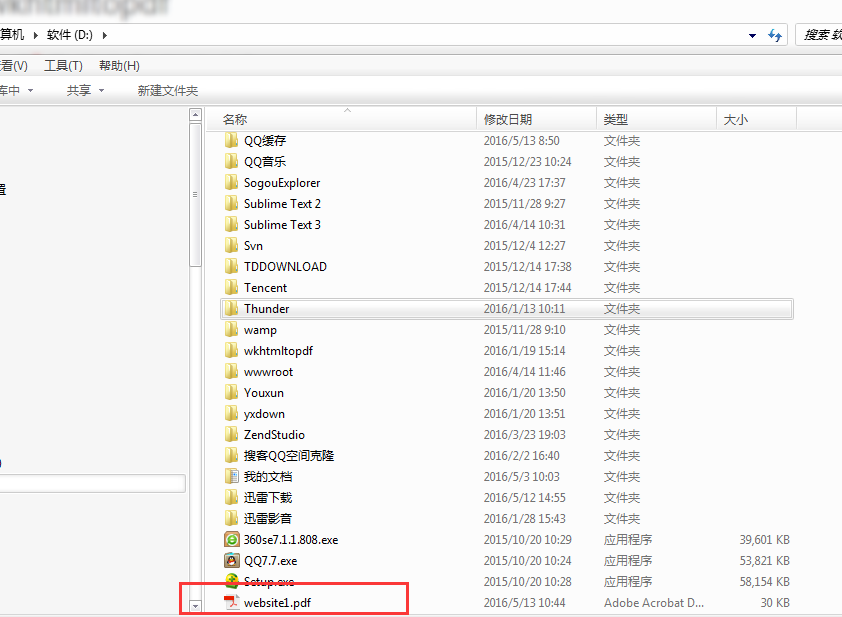
4、之后在相应位置(即刚刚设置的D盘)中会发现多了一个Pdf文件,就说明成功了
三,php里调用
php里调用是很简单的,用shell_exec这个函数就可以了,如果shell_exec函数不能用看看php.ini里是否补禁用了(找到php.ini中的shell_exec函数,取消注释就可以了,一般都是可以直接用的)。简单举例:
<?php shell_exec("wkhtmltopdf http://www.jb51.net/ 1.pdf") ?>
你会发现在你php文件的同级目录中会生成一个1.pdf的文件
下面代码举例介绍如何在网站开发中使用它:主要功能是截取网页的部分传递到php中处理成pdf文档
html页面代码:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<script src="js/jquery-2.1.4.min.js"></script>
<link rel="stylesheet" href="css/common.css" rel="external nofollow" rel="external nofollow" >
<link rel="stylesheet" href="css/myCenter.css" rel="external nofollow" rel="external nofollow" >
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>霍兰德职业测试</title>
</head>
<body>
<!--startprint-->
<div class="right5">
<div class="right_top" style="background-image:url(images/right-di.png);">
<h3>霍兰德测试报告</h3>
</div>
<div class="print">
<input type="button" value="下载报告" id="down" class="print_btn">
</div>
<div class="Hollander">
<h6>MBTI测试结果:ESTJ</h6>
<div id="chart"></div>
<p>约翰·霍兰德(John Holland)是美国约翰·霍普金斯大学心理学教授,美国著名的职业指导专家。霍兰德以职业兴趣理论为基础,先后编制了职业偏好量表(VocatIonaI Preference lnventory)和自我导向搜寻表(Self-directed Search)两种职业兴趣量表,霍兰德力求为每种职业兴趣找出两种相匹配的职业能力。兴趣测试和能力测试的结合在职业指导和职业咨询的实际操作中起到了促进作用。</p>
</div>
<table class="tbl1">
<tbody>
<tr node-type="toolBar">
<td class="tbl11">领导模式:</td>
<td class="tbl12">
<p>①直接领导,快速管理 ②运用过去经验解决问题 ③直接、明确地识别问题的核心 ④决策和执行决策非常迅速 ⑤传统型领导,尊重组织内部的等级和组织获得的成就</p>
</td>
</td>
</tr>
<tr node-type="toolBar">
<td class="tbl11">领导模式:</td>
<td class="tbl12">
<p>①直接领导,快速管理 ②运用过去经验解决问题 ③直接、明确地识别问题的核心 ④决策和执行决策非常迅速 ⑤传统型领导,尊重组织内部的等级和组织获得的成就</p>
</td>
</td>
</tr>
<tr node-type="toolBar">
<td class="tbl11">领导模式:</td>
<td class="tbl12">
<p>①直接领导,快速管理 ②运用过去经验解决问题 ③直接、明确地识别问题的核心 ④决策和执行决策非常迅速 ⑤传统型领导,尊重组织内部的等级和组织获得的成就</p>
</td>
</td>
</tr>
<tr node-type="toolBar">
<td class="tbl11">领导模式:</td>
<td class="tbl12">
<p>①直接领导,快速管理 ②运用过去经验解决问题 ③直接、明确地识别问题的核心 ④决策和执行决策非常迅速 ⑤传统型领导,尊重组织内部的等级和组织获得的成就</p>
</td>
</td>
</tr>
<tr node-type="toolBar">
<td class="tbl11">适合报考专业:</td>
<td class="tbl12">
<a><span>专业定位卡介绍>></span></a>
</td>
</td>
</tr>
</tbody>
</table>
</div>
<!--endprint-->
<form action="pdf.php" method="post" name="hld_res" id="hideform">
<input type="hidden" id="hide_content" name="html"/>
</form>
</body>
<script>
$(function () {
//获取需要传递的Html代码 通过<!--startprint--><!--endprint-->截取
bdhtml=window.document.body.innerHTML;
sprnstr="<!--startprint-->";
eprnstr="<!--endprint-->";
prnhtml=bdhtml.substr(bdhtml.indexOf(sprnstr)+17);
prnhtml=prnhtml.substring(0,prnhtml.indexOf(eprnstr));
//将获取的html代码添加到隐藏域中传给php文件处理
$("#hide_content").val(""+prnhtml+"");
} );
$("#down").click(function(){
$("#hideform").submit();
});
</script>
</html>
php页面:
<?php
//转成pdf
$html=$_POST['html'];
//Turn on output buffering
ob_start();
$html='
<link rel="stylesheet" href="css/common.css" rel="external nofollow" rel="external nofollow" >
<link rel="stylesheet" href="css/myCenter.css" rel="external nofollow" rel="external nofollow" >
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />'.$html;
//这儿可以引入生成的Html的样式表 路径可以是绝对路径也可以是相对路径,也可以把样式表文件复制到临时html文件的目录下 即这儿的demo文件目录下(默认) 也可以直接把样式写在html页面中直接传递过来
//$html = ob_get_contents();
//$html=$html1.$html;
$filename = "hld";
//save the html page in tmp folder 保存的html临时文件位置 可以是相对路径也是可以是绝对路径 下面用相对路径
file_put_contents("{$filename}.html", $html);
//Clean the output buffer and turn off output buffering
ob_end_clean();
//convert HTML to PDF
shell_exec("wkhtmltopdf -q {$filename}.html {$filename}.pdf");
if(file_exists("{$filename}.pdf")){
header("Content-type:application/pdf");
header("Content-Disposition:attachment;filename={$filename}.pdf");
echo file_get_contents("{$filename}.pdf");
//echo "{$filename}.pdf";
}else{
exit;
}
?>
点击页面中的下载按钮,

是不是弹出一个下载提示,打开下载的pdf,是不是和网页上的样式一模一样呢,
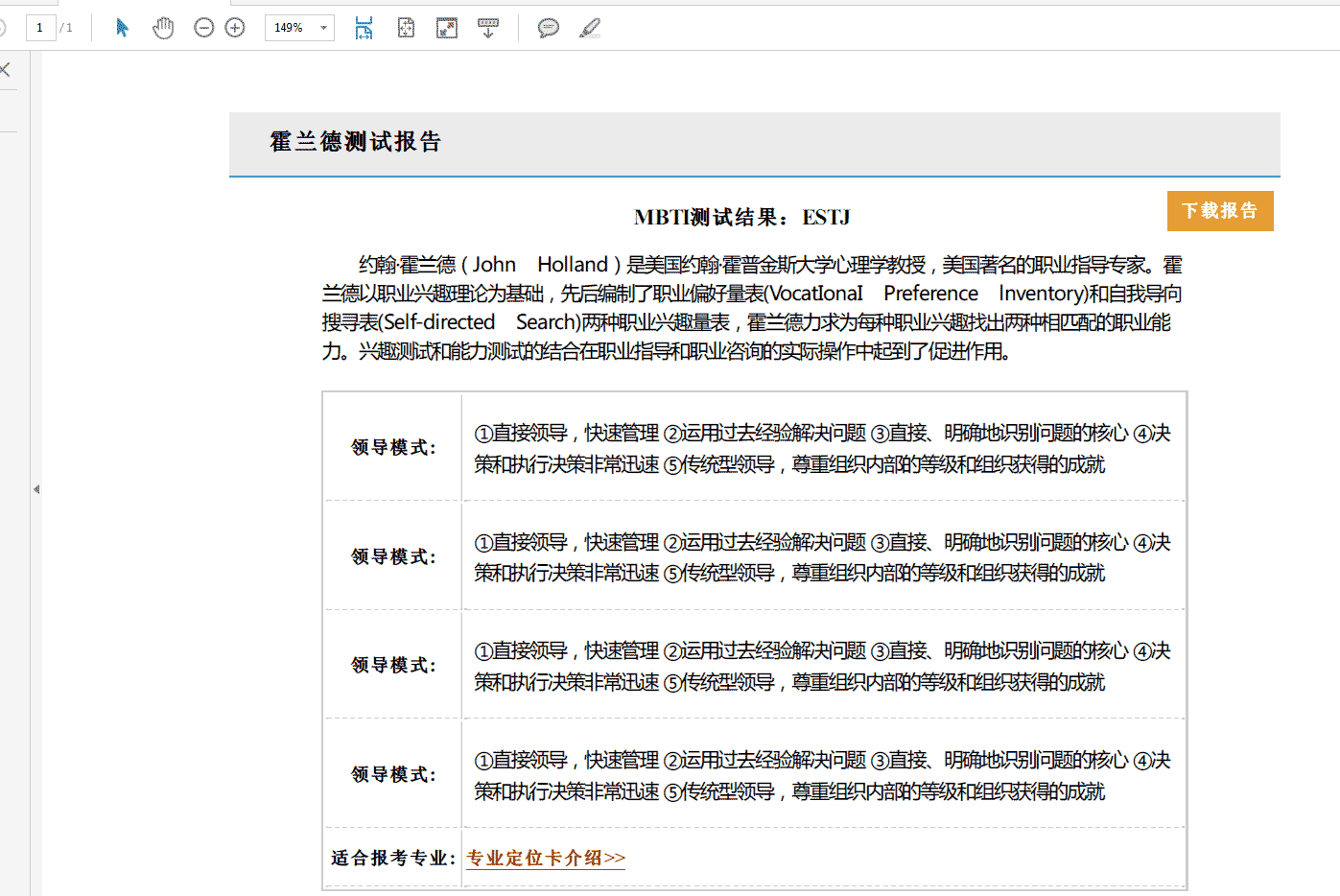
再打开Php文件中的文件保存位置,看看是不是多了两个临时文件呢?
这两个临时文件在哪儿,你的css就得在哪儿,或者你直接使用相对路径,引用其他文件中的css样式也可以的,最简单的就是把css样式直接写在要转成pdf的html页面中。
如果存在样式没有,那就是你的样式路径没有写对,在检查一下就可以了!
四,解决分页问题
wkhtmltopdf 很好用,但也有些不尽人意。就是当一个html页面很长我需要在指定的地方分页那怎么办呢? wkhtmltopdf 开发者在开发的时候并不是没有考虑到这一点,wkhtmltopdf 有个很好的方法,就是在那个div的样式后添加一个:page-break-inside:avoid;就ok了。
例如
div{ width:800px; min-height:1362px;margin:auto;page-break-inside:avoid;}
以上就是个人总结的转pdf的方法,很多地方还可以扩展,小伙伴们开动脑筋动起来吧,不过目前一直没有解决就是没法用中文名称命名文件,如果有能解决的伙伴,麻烦在下面留言告知,谢谢么么哒了!
相关推荐
-

wkhtmltopdf 最好用Html转pdf的工具
实习时公司需要把一些html页面中的部分内容生成pdf文件,然后我就找一些用php把html页面围成pdf文件的类.方法是可谓是找了很多很多,什么html2pdf,pdflib,FPDF这些都试过了,但是都没有达到我要的求(主要是不能解决中文乱码的问题以及样式排版的问题). pdflib,FPDF 这两个方法是需要编写程序去生成pdf的,就也是讲不支持直接把html页面转换成pdf:html2pdf这个虽然可以把html页面转换成pdf文 件,但是它只能转换一般简单的html代码,如果你的htm
-
20行Python代码实现一款永久免费PDF编辑工具的实现
PDF(Portable Document Format),中文名称便携文档格式是我们经常会接触到的一种文件格式,文献.文档...很多都是PDF格式.它以格式稳定的优势,使得我们在打印.分享.传输过程中能够最优的保持原有色彩和格式. PDF是以PostScript语言图像模型为基础的一种文档格式,它在格式的稳定性方面虽然具有很大优势.但是,在可编辑性方面却为使用者引入了另外一个困扰. 例如,在文档的分割.合并.剪切.转换.编辑等方面PDF就有些捉襟见肘了. Adobe Reader.福昕阅读器.
-
Python自动化办公之编写PDF拆分工具
目录 需求 需求解析 代码实现 今天我们继续分享真实的自动化办公案例,希望各位 Python 爱好者能够从中得到些许启发,在自己的工作生活中更多的应用 Python,使得工作事半功倍! 需求 需要从 PDF 中取出几页并将其保存为新的 PDF,为了后期使用方便,这个工具需要做成傻瓜式的带有 GUI 页面的形式 选择源 pdf 文件,再指定下生成的新的 pdf 文件名称及保存位置,和需要拆分的 page 信息,就可以得到新的 pdf 文件了 需求解析 对于 Python GUI,我们有太多种选择了
-
20行Python代码实现一款永久免费PDF编辑工具
目录 PyPDF2 删除PDF页 合并PDF 旋转 添加水印 加密 pdfminer PDF转TxT 总结 PDF是我们经常会接触到的一种文件格式,文献.文档...很多都是PDF格式.它以格式稳定的优势,使得我们在打印.分享.传输过程中能够最优的保持原有色彩和格式. PDF是以PostScript语言图像模型为基础的一种文档格式,它在格式的稳定性方面虽然具有很大优势.但是,在可编辑性方面却为使用者引入了另外一个困扰. 例如,在文档的分割.合并.剪切.转换.编辑等方面PDF就有些捉襟见肘了. Ad
-
Java操作pdf的工具类itext的处理方法
目录 一.什么是iText? 二.引入jar 三.iText常用类 四.生成PDF步骤 五.Java操作pdf的工具类itext 六.更多的Java代码实例 一.什么是iText? 在企业的信息系统中,报表处理一直占比较重要的作用,iText是一种生成PDF报表的Java组件.通过在服务器端使用Jsp或JavaBean生成PDF报表,客户端采用超链接显示或下载得到生成的报表,这样就很好的解决了B/S系统的报表处理问题. 二.引入jar 1.项目要使用iText,必须引入jar包 <depende
-
python包pdfkit(wkhtmltopdf) 将HTML转换为PDF的操作方法
目录 python包-pdfkit 将HTML转换为PDF 什么是pdfkit 安装 使用 将url生成pdf文件 字符串生成pdf[pdfkit.from_string()函数] 报错OSError: No wkhtmltopdf executable found 报错 python包-pdfkit 将HTML转换为PDF 什么是pdfkit pdfkit,把HTML+CSS格式的文件转换成PDF格式文档的一种工具.它就是html转成pdf工具包wkhtmltopdf的Python封装.所以,
-
Python合并pdf文件的工具
如果你需要一个PDF文件合并工具,那么本文章完全可以满足您的要求.哈喽,大家好呀,这里是滑稽研究所.不多废话,本期我们利用Python合并把多个pdf文件合并为一个.我们提前准备了5个pdf文件,来验证代码. 源代码: import os from PyPDF2 import PdfFileReader, PdfFileWriter # 使用os模块的walk函数,搜索出指定目录下的全部PDF文件 # 获取同一目录下的所有PDF文件的绝对路径 def getFileName(filedi
-
Nodejs中使用phantom将html转为pdf或图片格式的方法
最近在项目中遇到需要把html页面转换为pdf的需求,并且转换成的pdf文件要保留原有html的样式和图片.也就是说,html页面的图片.表格.样式等都需要完整的保存下来. 最初找到三种方法来实现这个需求,这三种方法都只是粗浅的看了使用方法,从而找出适合这个需求的方案: html-pdf 模块 wkhtmltopdf 工具 phantom 模块 最终使用了phantom模块,也达到了预期效果.现在简单的记录三种方式的使用方法,以及三者之间主要的不同之处. 1.html-pdf github:ht
-
使用rst2pdf实现将sphinx生成PDF
当初项目文档是用sphinx写的,一套rst下来make html得到一整个漂亮的在线文档.现在想要将文档导出为离线的handbook pdf,于是找到了rst2pdf这个项目,作为sphinx的拓展,然后加上少量配置即可输出中文PDF. rst2pdf 简介 rst2pdf是一个将 reStructuredText 转换为 PDF 的工具,具有下列特性: 自定义页面布局 支持层叠样式表 支持内嵌TTF和Type1字体 支持几乎所有语言的语法高亮 使用reStructuredText作为源文件
-
利用python程序生成word和PDF文档的方法
一.程序导出word文档的方法 将web/html内容导出为world文档,再java中有很多解决方案,比如使用Jacob.Apache POI.Java2Word.iText等各种方式,以及使用freemarker这样的模板引擎这样的方式.php中也有一些相应的方法,但在python中将web/html内容生成world文档的方法是很少的.其中最不好解决的就是如何将使用js代码异步获取填充的数据,图片导出到word文档中. 1. unoconv 功能: 1.支持将本地html文档转换为docx