Vue3 diff算法的简单解刨
目录
- 性能比较
- 前置与后置的预处理
- 节点无序
- 最长递增子序列
上篇我们介绍了vue2中的双端diff算法的优势(相比于简单算法相同场景下移动DOM次数更少)。如今Vue3的势头正盛,在diff算法方面也做了相应的变化,利用到了最长递增子序列把性能又提升了一个档次。对于技术栈使用Vue的同学来说又是必须要学习的一部分。
性能比较

此图借鉴了《Vuejs设计与实现》这本书
ivi和inferno所采用的快速diff算法的性能要稍优于Vue2的双端diff算法。既然快速diff算法这么高效,我们当然有必要了解它咯。
前置与后置的预处理

这里有两组子节点,c1表示老的子节点,c2表示新的子节点。首先将从c1和c2的头部节点开始对比,如果节点相同则通过patch更新节点的内容。e1表示老的子节点的尾部索引,e2表示新的子节点的尾部索引。
while (i <= e1 && i <= e2) {
const n1 = c1[i]
const n2 = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
// 如果节点相同 则进行递归执行patch更新节点
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
null,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
} else {
// 如果节点不相同,则直接退出
break
}
i++
}
然后将索引递增,发现c1中节点B和c2中节点D不是同一节点,则循环退出。接着将从c1和c2的尾部节点开始对比,如果节点相同则通过patch更新节点的内容。

while (i <= e1 && i <= e2) {
const n1 = c1[e1]
const n2 = (c2[e2] = optimized
? cloneIfMounted(c2[e2] as VNode)
: normalizeVNode(c2[e2]))
// 如果是相同节点 则递归执行patch
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
null,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
} else {
// 如果节点不相同 则退出
break
}
e1--
e2--
}
此过程经历了c1的节点C和c2的节点C对比,c1的节点B和c2的节点B对比,节点相同则通过patch更新节点的内容,每次循环e1 e2向前推进。当循环到了c1中节点B和c2中节点D不是同一节点,则循环退出
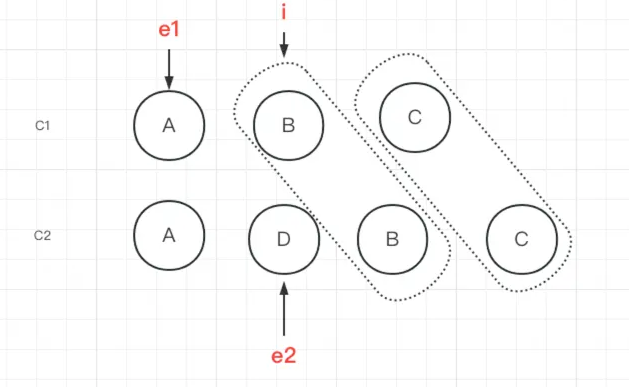
此时当新节点中还有剩余,则需要添加新节点。 相反的,如果旧节点有剩余需要删除旧节点
if (i > e1) {
// 当索引大于老节点的尾部
if (i <= e2) {
// 当索引小于新节点的尾部 需要将剩余的节点添加
const nextPos = e2 + 1
const anchor = nextPos < l2 ? (c2[nextPos] as VNode).el : parentAnchor
while (i <= e2) {
patch(
null,
(c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i])),
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
i++
}
}
}
else if (i > e2) {
// 当索引i大于尾部索引e2 则直接删除旧子树从索引i开始到e1部分的节点
while (i <= e1) {
unmount(c1[i], parentComponent, parentSuspense, true)
i++
}
}
上面的情况是有序的,下面我们看下无序的情况
节点无序
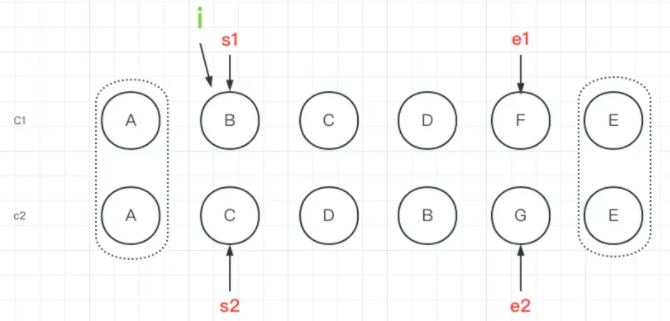
上图是经过上面的两层循环之后的结果。我们首先看下代码,由于节点无序情况的代码比较长,我们一段段的解刨
const s1 = i // prev starting index 旧子序列开始索引 从i开始记录
const s2 = i // next starting index 新子序列开始索引 从i开始记录
// 5.1 build key:index map for newChildren
// 根据key 建立新子序列的索引图
const keyToNewIndexMap: Map<string | number | symbol, number> = new Map()
for (i = s2; i <= e2; i++) {
// 获取新节点
const nextChild = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
if (nextChild.key != null) {
if (__DEV__ && keyToNewIndexMap.has(nextChild.key)) {
warn(
`Duplicate keys found during update:`,
JSON.stringify(nextChild.key),
`Make sure keys are unique.`
)
}
// 根据新节点的key 和 对应的索引做映射关系
// <key, index>
keyToNewIndexMap.set(nextChild.key, i)
}
}
let j
// 新子序列已经更新的节点数量
let patched = 0
// 新子序列待更新节点的数量,等于新子序列的长度
const toBePatched = e2 - s2 + 1
// 是否存在需要移动的节点
let moved = false
// 用于跟踪判断是否有节点需要移动的节点
let maxNewIndexSoFar = 0
// 这个数组存储新子序列中的元素在旧子序列节点出的索引,用于确定最长递增子序列
const newIndexToOldIndexMap = new Array(toBePatched)
// 初始化数组 为0
// 0是一个特殊的值,如果遍历之后仍有元素的值为0,则说明这个新节点没有对应的旧节点
for (i = 0; i < toBePatched; i++) newIndexToOldIndexMap[i] = 0
s1表示旧子节点开始遍历的索引,从i开始记录,s2表示新子节点开始遍历的索引,也从i开始记录。根据新子节点的key建立新子序列的索引图keyToNewIndexMap。patched表示新子序列已经更新的节点数量,toBePatched表示新子序列待更新节点的数量,等于新子序列的长度。moved表示是否存在需要移动的节点。maxNewIndexSoFar用于跟踪判断是否有节点需要移动的节点。newIndexToOldIndexMap存储新子序列中的节点在旧子序列节点的索引,用于确定最长递增子序列,初始化全部为0,0是一个特殊的值,如果遍历之后仍有元素的值为0,则说明这个新节点没有对应的旧节点。我们在图中表示一下
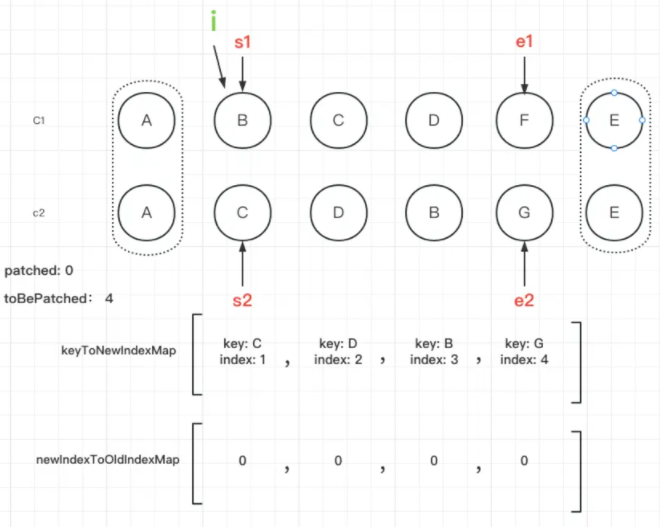
然后正序遍历旧子序列
// 正序遍历旧子序列
for (i = s1; i <= e1; i++) {
const prevChild = c1[i]
if (patched >= toBePatched) {
// 所有新的子序列节点都已经更新,删除剩余的节点
// all new children have been patched so this can only be a removal
unmount(prevChild, parentComponent, parentSuspense, true)
continue
}
let newIndex
if (prevChild.key != null) {
// 查找旧子序列中的节点在新子序列中的索引
newIndex = keyToNewIndexMap.get(prevChild.key)
} else {
// key-less node, try to locate a key-less node of the same type
for (j = s2; j <= e2; j++) {
if (
newIndexToOldIndexMap[j - s2] === 0 &&
isSameVNodeType(prevChild, c2[j] as VNode)
) {
newIndex = j
break
}
}
}
if (newIndex === undefined) {
// 找不到说明旧子序列需要删除
unmount(prevChild, parentComponent, parentSuspense, true)
} else {
// 更新新子序列中的元素在旧子序列中的索引,这里 +1 偏移是为了避免i为0的特殊情况 影响后面最长递增子序列的求解
newIndexToOldIndexMap[newIndex - s2] = i + 1
//maxNewIndexSoFar 存储的是上次旧值的newIndex 如果不是一直递增 则说明有移动
if (newIndex >= maxNewIndexSoFar) {
maxNewIndexSoFar = newIndex
} else {
moved = true
}
patch(
prevChild,
c2[newIndex] as VNode,
container,
null,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized处
)
patched++
}
}
每次遍历拿到旧子节点的值prevChild,如果patched >= toBePatched也就是说新子序列已经更新的节点数量大于等于待更新的节点数量,说明新子序列的所有节点更新完毕,旧子序列中剩余的节点删除即可。
如果每次循环拿到的旧子节点的值的key存在,则查找旧子序列中的节点在新子序列中的索引标记为newIndex。如果key不存在,则遍历新子序列待更新的节点,如果prevChild和遍历新子序列待更新的节点有相同的节点,则将索引赋值给newIndex。接着判断newIndex是否存在,如果不存在,则说明新子序列中找不到旧子序列中的这个节点,则直接删除。如果存在,则更新新子序列中的元素在旧子序列中的索引,这里 ‘+1’ 偏移是为了避免i为0的特殊情况,影响后面最长递增子序列的求解,因为我们现在规定的newIndexToOldIndexMap中的元素为0说明这个元素没有对应的老节点,如果不'+1'我们避免不了i为0的情况,这样就影响了最长递增子序列的求解。我们看下newIndexToOldIndexMap重新赋值之后的结果

maxNewIndexSoFar存储的是上次旧值的newIndex,如果不是一直递增 则说明有移动,则moved设置为ture。然后将newIndex对应的新节点和prevChild老节点进行patch,然后patched++记录更新的次数。
我们继续看下面的代码
const increasingNewIndexSequence = moved
? getSequence(newIndexToOldIndexMap)
: EMPTY_ARR
j = increasingNewIndexSequence.length - 1
// 倒序遍历 以便使用更新的节点作为锚点
for (i = toBePatched - 1; i >= 0; i--) {
const nextIndex = s2 + i
const nextChild = c2[nextIndex] as VNode
// 锚点指向上一个更新的节点, 如果nextIndex超过新节点的长度,则指向parentAnchor
const anchor =
nextIndex + 1 < l2 ? (c2[nextIndex + 1] as VNode).el : parentAnchor
if (newIndexToOldIndexMap[i] === 0) {
// mount new
// 挂载新节点
patch(
null,
nextChild,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
} else if (moved) {
// 没有最长递增子序列或者当前节点索引不在最长递增子序列中, 需要移动
if (j < 0 || i !== increasingNewIndexSequence[j]) {
move(nextChild, container, anchor, MoveType.REORDER)
} else {
j--
}
}
}
首先判断是否需要移动,如果需要移动怎么才能以移动最少的步数完成更新呢?这就需要用到最长递增子序列(getSequence这个方法代码我们贴到文章最后)。我们得到了最长递增子序列的索引值的集合increasingNewIndexSequence,我们看下结果。

根据结果我们发现在newIndexToOldIndexMap中只有索引为0和1的节点是递增的,所以只有这两个对应的旧的子序列的节点是不需要移动的,其他的则需要移动。
倒序遍历。为什么要倒序遍历呢?因为我们将节点插入到已经更新的节点前面(从后往前遍历可以始终保持当前遍历的节点的下一个节点是更新过的)这里使用的是insertBefore。

比如这个例子节点‘G’就要插入到节点‘E’的前面,节点‘E’是已经更新过的了。
继续往前推进,节点‘B’不在最长递增子序列increasingNewIndexSequence中,所以需要移动。然后拿到节点‘B’对应的el插入到节点‘G’的前面。这个节点‘B’的el我们从节点‘B’的Vnode上面就可以获取到了。因为当两个新旧节点进行对比的时候会进行下面的操作
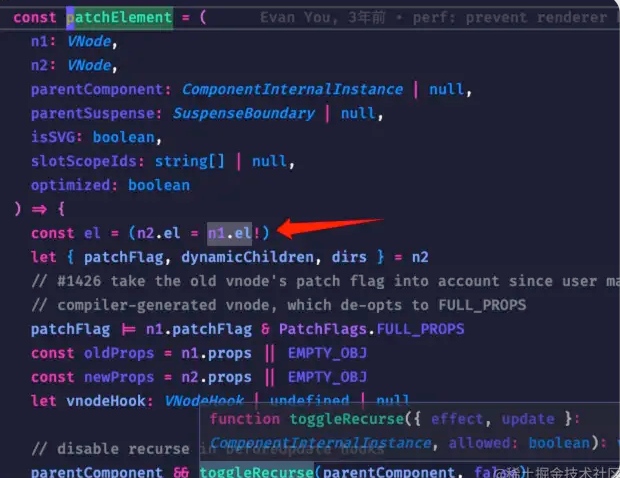
以上就是我们要介绍的Vue3的diff算法的核心内容
总结
有序的情况比较简单,我们就直接说无序的情况。
1.根据key建立新子序列的索引图 keyToNewIndexMap
通过遍历新子序列的节点 将key和index映射
2.根据新子序列中待更新节点的数量toBePatched创建数组newIndexToOldIndexMap数组初始化为0
这个数组就是保存新子序列中的节点在旧子序列中的索引位置。
3.遍历旧子节点 拿旧的子节点去keyToNewIndexMap中找对应新子节点的位置
- 如果找不到 则说明这个节点在新的子节点中没有则删除
- 找到了之后则更新
newIndexToOldIndexMap,数组中的元素被重新赋值为新子序列中的节点在旧子序列中的索引位置,为0的元素说明这个节点是新增的。 - 将新旧子节点对比更新
4.通过最长递增子序列找到那些节点是需要移动的,哪些节点是不需要的移动的
最长递增子序列
// https://en.wikipedia.org/wiki/Longest_increasing_subsequence
function getSequence(arr: number[]): number[] {
const p = arr.slice()
const result = [0]
let i, j, u, v, c
const len = arr.length
for (i = 0; i < len; i++) {
// arrI 为当前顺序取出的元素
const arrI = arr[i]
// 排除0的情况
if (arrI !== 0) {
// result 存储的是长度为i的递增子序列最小末尾值的索引
j = result[result.length - 1]
// arr[j]为末位置,如果满足arr[j]<arrI 那么直接在当前递增子序列后面添加
if (arr[j] < arrI) {
// 存储result更新前的最后一个索引的值
p[i] = j
// 存储元素对应的索引值
result.push(i)
continue
}
// 不满足 则执行二分搜索
u = 0
v = result.length - 1
// 查找第一个比arrI小的节点,更新result的值
while (u < v) {
// c记录中间的位置
c = (u + v) >> 1
if (arr[result[c]] < arrI) {
// 若中间的值小于arrI 则在后边 更新下沿
u = c + 1
} else {
// 更新下沿
v = c
}
}
// 找到第一个比arrI小的位置u,插入它
if (arrI < arr[result[u]]) {
if (u > 0) {
p[i] = result[u - 1]
}
result[u] = i
}
}
}
u = result.length
v = result[u - 1]
while (u-- > 0) {
result[u] = v
v = p[v]
}
return result
}
以上就是Vue3 diff算法的简单解刨的详细内容,更多关于Vue3 diff算法的资料请关注我们其它相关文章!
相关推荐
-
详解vue3.0 diff算法的使用(超详细)
前言:随之vue3.0beta版本的发布,vue3.0正式版本相信不久就会与我们相遇.尤玉溪在直播中也说了vue3.0的新特性typescript强烈支持,proxy响应式原理,重新虚拟dom,优化diff算法性能提升等等.小编在这里仔细研究了vue3.0beta版本diff算法的源码,并希望把其中的细节和奥妙和大家一起分享. 首先我们来思考一些大中厂面试中,很容易问到的问题: 1 什么时候用到diff算法,diff算法作用域在哪里? 2 diff算法是怎么运作的,到底有什么作用? 3 在v-f
-

Vue3组件更新中的DOM diff算法示例详解
目录 同步头部节点 同步尾部节点 添加新的节点 删除多余节点 处理未知子序列 移动子节点 建立索引图 更新和移除旧节点 移动和挂载新节点 最长递增子序列 总结 总结 在vue的组件更新过程中,新子节点数组相对于旧子节点数组的变化,无非是通过更新.删除.添加和移动节点来完成,而核心 diff 算法,就是在已知旧子节点的 DOM 结构.vnode 和新子节点的 vnode 情况下,以较低的成本完成子节点的更新为目的,求解生成新子节点 DOM 的系列操作. 举例来说,假说我们有一个如下的列表 <ul>
-
Vue3 diff算法之双端diff算法详解
目录 双端Diff算法 双端比较的原理 简单Diff的不足 双端Diff介绍 Diff流程 第一次diff 第二次diff 第三次diff 第四次diff 双端Diff的优势 非理想情况的处理方式 添加新元素 移除不存在得节点 双端Diff完整代码 双端Diff算法 双端Diff在可以解决更多简单Diff算法处理不了的场景,且比简单Diff算法性能更好.本篇是以简单Diff算法的案例来展开的,不过没有了解简单Diff算法直接看双端Diff算法也是可以看明白的. 双端比较的原理 引用简单Diff算
-
一文详解Vue3中简单diff算法的实现
目录 简单Diff算法 减少DOM操作 例子 结论 实现 DOM复用与key的作用 例子 虚拟节点的key 实现 找到需要移动的元素 探索节点顺序关系 实现 如何移动元素 例子 实现 添加新元素 例子 实现 移除不存在的元素 例子 实现 总结 简单Diff算法 核心Diff只关心新旧虚拟节点都存在一组子节点的情况 减少DOM操作 例子 // 旧节点 const oldVNode = { type: 'div', children: [ { type: 'p', children: '1' },
-
Vue3 diff算法的简单解刨
目录 性能比较 前置与后置的预处理 节点无序 最长递增子序列 上篇我们介绍了vue2中的双端diff算法的优势(相比于简单算法相同场景下移动DOM次数更少).如今Vue3的势头正盛,在diff算法方面也做了相应的变化,利用到了最长递增子序列把性能又提升了一个档次.对于技术栈使用Vue的同学来说又是必须要学习的一部分. 性能比较 此图借鉴了<Vuejs设计与实现>这本书 ivi和inferno所采用的快速diff算法的性能要稍优于Vue2的双端diff算法.既然快速diff算法这么高效,我们当然
-
vue3 diff 算法示例
目录 一.可能性(常见): 二.找规律 三.算法优化 最长的递增子序列 完整代码 一.可能性(常见): 1. 旧的:a b c新的:a b c d 2. 旧的: a b c新的:d a b c 3. 旧的:a b c d新的:a b c 4. 旧的:d a b c新的: a b c 5. 旧的:a b c d e i f g新的:a b e c d h f g 对应的真实虚拟节点(为方便理解,文中用字母代替): // vnode对象 const a = { type: 'div', // 标
-
vue2从数据变化到视图变化之diff算法图文详解
目录 引言 1.isUndef(oldStartVnode) 2.isUndef(oldEndVnode) 3.sameVnode(oldStartVnode, newStartVnode) 4.sameVnode(oldEndVnode, newEndVnode) 5.sameVnode(oldStartVnode, newEndVnode) 6.sameVnode(oldEndVnode, newStartVnode) 7.如果以上都不满足 小结 引言 vue数据的渲染会引入视图的重新渲染.
-
一文详解Vue 的双端 diff 算法
目录 前言 diff 算法 简单 diff 双端 diff 总结 前言 Vue 和 React 都是基于 vdom 的前端框架,组件渲染会返回 vdom,渲染器再把 vdom 通过增删改的 api 同步到 dom. 当再次渲染时,会产生新的 vdom,渲染器会对比两棵 vdom 树,对有差异的部分通过增删改的 api 更新到 dom. 这里对比两棵 vdom 树,找到有差异的部分的算法,就叫做 diff 算法. diff 算法 我们知道,两棵树做 diff,复杂度是 O(n^3) 的,因为每个节
-
React Diff算法不采用Vue的双端对比原因详解
目录 前言 React 官方的解析 Fiber 的结构 Fiber 链表的生成 React 的 Diff 算法 第一轮,常见情况的比对 第二轮,不常见的情况的比对 重点如何协调更新位置信息 小结 图文解释 React Diff 算法 最简单的 Diff 场景 复杂的 Diff 场景 Vue3 的 Diff 算法 第一轮,常见情况的比对 第二轮,复杂情况的比对 Vue2 的 Diff 算法 第一轮,简单情况的比对 第二轮,不常见的情况的比对 React.Vue3.Vue2 的 Diff 算法对比
-
深入聊一聊虚拟DOM与diff算法
目录 虚拟DOM与diff算法 snabbdom环境搭建 虚拟DOM和h函数 diff算法 patch函数 patchVnode函数 updateChildren函数 v-for中key作用与原理 总结 虚拟DOM与diff算法 在vue.react等技术出现之前,每次修改DOM都需要通过遍历查询DOM树的方式,找到需要更新的DOM,然后修改样式或结构,资源损耗十分严重.而对于虚拟DOM来说,每次DOM的更改就变成了JS对象的属性的更改,能方便的查找JS对象的属性变化,要比查询DOM树的性能开销
-
详解为什么Vue中不要用index作为key(diff算法)
前言 Vue 中的 key 是用来做什么的?为什么不推荐使用 index 作为 key?常常听说这样的问题,本篇文章带你从原理来一探究竟. 另外本文的结论对于性能的毁灭是针对列表子元素顺序会交换.或者子元素被删除的特殊情况,提前说明清楚,喷子绕道. 本篇已经收录在 Github 仓库,欢迎 Star: https://github.com/sl1673495/blogs/issues/39 示例 以这样一个列表为例: <ul> <li>1</li> <li>