Flink JobGraph生成源码解析
目录
- 引言
- 概念
- JobGraph生成
- 生成hash值
- 生成chain
- 总结
引言
在DataStream基础中,由于其中的内容较多,只是介绍了JobGraph的结果,而没有涉及到StreamGraph到JobGraph的转换过程。本篇我们来介绍下JobGraph的生成的详情,重点是Operator可以串联成Chain的条件
概念
首先我们来回顾下JobGraph中的相关概念
- JobVertex:job的顶点,即对应的计算逻辑(这里用的是Vertex, 而前面用的是Node,有点差异),通过inputs记录了所有来源的Edge,而输出是ArrayList来记录
- JobEdge: job的边,记录了源Vertex和目标表Vertex.
- IntermediateDataSet: 定义了一个中间数据集,但并没有存储,只是记录了一个Producer(JobVertex)和一个Consumer(JobEdge)
JobGraph生成
前面我们在介绍部署的时候,有介绍具体是通过PipelineExecutor的execute()方法来提交对应的任务,StreamGraph到JobGraph的转换逻辑就是在该方法中处理的,具体是通过如下方法来进行处理
public static JobGraph getJobGraph(
@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration)
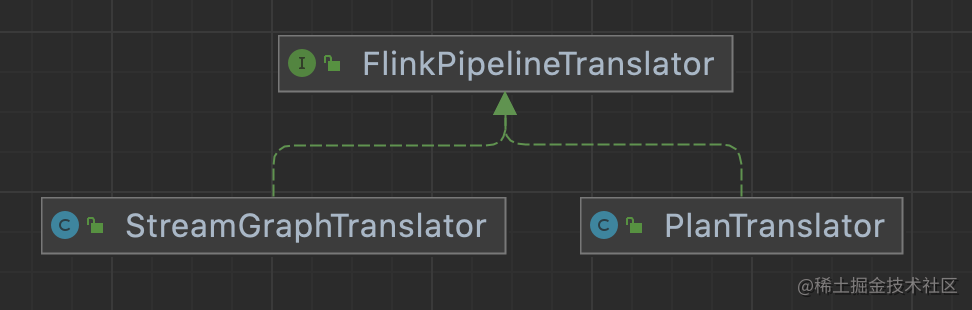
最后执行转换的类为FlinkPipelineTranslator,调用的是其中的translateToJobGraph方法。
JobGraph translateToJobGraph(
Pipeline pipeline, Configuration optimizerConfiguration, int defaultParallelism);

这里有2个不同的实现类
- StreamGraphTranslator:对StreamGraph的Pipeline进行转换处理
- PlanTranslator:对Plan类型的Pipeline进行转换处理,用于SQL场景。 而这2个分别对应到2个不同的类来生成JobGraph,分别如下:
- StreamingJobGraphGenerator
- JobGraphGenerator 本篇我们重点介绍StreamGraph到JobGraph的转换StreamingJobGraphGenerator, JogGraphGenerator这块等到介绍FlinkSQL的时候来介绍。StreamingJobGraphGenerator类中具体转换处理的逻辑如下:
private JobGraph createJobGraph() {
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
setPhysicalEdges();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
addVertexIndexPrefixInVertexName();
setVertexDescription();
return jobGraph;
}
重点我们介绍以下几点
生成hash值
对每个streamNode生成一个hash值,用于来标识节点,用于重新提交任务后涉及恢复作业的场景。具体生成hash值的逻辑如下:
- 如果指定了id信息,如Transformation.getUid(), 就用该值来生成hash值
- 否则使用链上的输出node和节点的输入nodes的hash值来生成一个hash值 对具体的算法细节感兴趣的同学可以深入研究StreamGraphHasherV2的具体内容。
生成chain
如果连接的2个节点满足一定的条件,就会把这2个节点放到一个chain里面,这样可以避免上下游算子间发送数据的网络开销和序列化反序列化的性能开销。判断算子是否可以组成一个chain的判断逻辑如下:
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph);
}
private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
&& arePartitionerAndExchangeModeChainable(
edge.getPartitioner(),
edge.getExchangeMode(),
streamGraph.getExecutionConfig().isDynamicGraph())
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled())) {
return false;
}
// check that we do not have a union operation, because unions currently only work
// through the network/byte-channel stack.
// we check that by testing that each "type" (which means input position) is used only once
for (StreamEdge inEdge : downStreamVertex.getInEdges()) {
if (inEdge != edge && inEdge.getTypeNumber() == edge.getTypeNumber()) {
return false;
}
}
return true;
}
具体解读如下:
- 下游节点只有1个输入边
- 上游节点和下游节点是在同一个SlotSharingGroup,slotSharingGroup在没有设置的情况下,默认为default;
- 上下游节点的算子的chaining策略是支持chain的,上游算子的chaining策略为ALWAYS\HEAD\HEAD_WITH_SOURCES,下游算子的chaining策略为ALWAYS或者(HEAD_WITH_SOURCES且上游算子为source算子,具体这些策略的说明见ChainingStrategy.java
- 边的分区策略是ForwardForConsecutiveHashPartitioner或者分区策略是ForwardPartitioner且数据交换方式(StreamExchangeMode)不是批模式
- 上下游节点的并行度一致
- StreamGraph是允许Chaining的
总结
本篇介绍了StreamGraph到JobGraph的生成流程,重点是在上下游节点是需要满足什么条件才能chain到一起的具体逻辑。
以上就是Flink JobGraph生成源码解析的详细内容,更多关于Flink JobGraph生成的资料请关注我们其它相关文章!
相关推荐
-
Flink部署集群整体架构源码分析
目录 概览 部署模式 Application mode 客户端提交请求 服务端启动&提交Application session mode Cluster架构 Cluster的启动流程 DispatcherResourceManagerComponent Runner代码 HA代码框架 总结 概览 本篇我们来了解Flink的部署模式和Flink集群的整体架构 部署模式 Flink支持如下三种运行模式 运行模式 描述 Application Mode Flink Cluster只执行提交的整个job
-
Flink时间和窗口逻辑处理源码分析
目录 概览 时间 重要类 WatermarkStrategy WatermarkGenerator TimerService 处理逻辑 窗口 重要类 Window WindowAssigner Triger Evictor WindowOperator InternalAppendingState 处理逻辑 总结 概览 计算模型 DataStream基础框架 事件时间和窗口 部署&调度 存储体系 底层支撑 在实时计算处理时,需要跟时间来打交道,如实时风控场景的时间行为序列,实时分析场景下的时间窗
-
Flink状态和容错源码解析
目录 引言 概述 State Keyed State 状态实例管理及数据存储 HeapKeyedStateBackend RocksDBKeyedStateBackend OperatorState 上层封装 总结 引言 计算模型 DataStream基础框架 事件时间和窗口 状态和容错 部署&调度 存储体系 底层支撑 Flink中提供了State(状态)这个概念来保存中间计算结果和缓存数据,按照不同的场景,Flink提供了多种不同类型的State,同时为了实现Exactly once的语义,F
-
详解Flink同步Kafka数据到ClickHouse分布式表
目录 引言 什么是ClickHouse? 创建复制表 通过jdbc写入 引言 业务需要一种OLAP引擎,可以做到实时写入存储和查询计算功能,提供高效.稳健的实时数据服务,最终决定ClickHouse 什么是ClickHouse? ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS). 列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解),图片来源于ClickHouse中文官方文档. 行式 列
-
Flink作业Task运行源码解析
目录 引言 概览 调度框架 JobMaster ScheduleNG TaskExecutor Task 计算框架 算子计算处理 总结 引言 上一篇我们分析了Flink部署集群的过程和作业提交的方式,本篇我们来分析下,具体作业是如何被调度和计算的.具体分为2个部分来介绍 作业运行的整体框架,对相关的重要角色有深入了解 计算流程,重点是如何调度具体的operator机制 概览 首先我们来了解下整体的框架 JobMaster: 计算框架的主节点,负责运行单个JobGraph,包括任务的调度,资源申请
-

Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
Flink DataStream基础框架源码分析
目录 引言 概览 深入DataStream DataStream 属性和方法 类体系 Transformation 属性和方法 类体系 StreamOperator 属性和方法 类体系 Function DataStream生成提交执行的Graph StreamGraph 属性和方法 StreamGraph生成 JobGraph 属性和方法 总结 引言 希望通过对Flink底层源码的学习来更深入了解Flink的相关实现逻辑.这里新开一个Flink源码解析的系列来深入介绍底层源码逻辑.说明:这里默
-
Flink JobGraph生成源码解析
目录 引言 概念 JobGraph生成 生成hash值 生成chain 总结 引言 在DataStream基础中,由于其中的内容较多,只是介绍了JobGraph的结果,而没有涉及到StreamGraph到JobGraph的转换过程.本篇我们来介绍下JobGraph的生成的详情,重点是Operator可以串联成Chain的条件 概念 首先我们来回顾下JobGraph中的相关概念 JobVertex:job的顶点,即对应的计算逻辑(这里用的是Vertex, 而前面用的是Node,有点差异),通过in
-
Flink 侧流输出源码示例解析
目录 Flink 侧流输出源码解析 源码解析 TimestampedCollector#collect CountingOutput#collect BroadcastingOutputCollector#collect RecordWriterOutput#collect ProcessOperator#ContextImpl#output CountingOutput#collect BroadcastingOutputCollector#collect RecordWriterOutput
-
AngularJS动态生成div的ID源码解析
1.问题背景 给定一个数组对象,里面是div的id:循环生成div元素,并给id赋值 2.实现源码 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>AngularJS动态生成div的ID</title> <script src="http://apps.bdimg.com/libs/angular.js/1.4.6/angula
-
Java源码解析之object类
在源码的阅读过程中,可以了解别人实现某个功能的涉及思路,看看他们是怎么想,怎么做的.接下来,我们看看这篇Java源码解析之object的详细内容. Java基类Object java.lang.Object,Java所有类的父类,在你编写一个类的时候,若无指定父类(没有显式extends一个父类)编译器(一般编译器完成该步骤)会默认的添加Object为该类的父类(可以将该类反编译看其字节码,不过貌似Java7自带的反编译javap现在看不到了). 再说的详细点:假如类A,没有显式继承其他类,编译
-
Android图片加载利器之Picasso源码解析
看到了这里,相信大家对Picasso的使用已经比较熟悉了,本篇博客中将从基本的用法着手,逐步的深入了解其设计原理. Picasso的代码量在众多的开源框架中算得上非常少的一个了,一共只有35个class文件,但是麻雀虽小,五脏俱全.好了下面跟随我的脚步,出发了. 基本用法 Picasso.with(this).load(imageUrl).into(imageView); with(this)方法 public static Picasso with(Context context) { if
-
BootStrap Tooltip插件源码解析
Tooltip插件可以让你把要显示的内容以弹出框的形式来展示,如: 因为自己在工作的过程中,用到了Tooltip这个插件,并且当时正想学习一下元素定位的问题,如:提示框显示的位置就是触发提示框元素的位置,可以配置在上.下.左.右等位置,所以就去看了源码.对于整个插件源码没有看全,但也学到了许多的知识点.能力有限,可能其中有认识错误的地方,以后再补充吧 1 使用方法不介绍 ,可以参照 Bootstrap 提示工具(Tooltip)插件 2 源码解析 +function ($) { 'use str
-
ClassLoader类加载源码解析
Java类加载器 1.BootClassLoader: 用于加载Android Framework层class文件. 2.PathClassLoader: 用于Android应用程序类加载器.可以加载指定的dex,jar.zip.zpk中的classes.dex 3.DexClassLoader:加载指定的dex,以及jar.zip.apk中的classes.dex 源码解析 1.ClassLoader中提供loadClass用于加载指定类 //ClassLoader.java public C
-
Python优秀开源项目Rich源码解析的流程分析
这篇文章对优秀的开源项目Rich的源码进行解析,OMG,盘他.为什么建议阅读源码,有两个原因,第一,单纯学语言很难在实践中灵活应用,通过阅读源码可以看到每个知识点的运用场景,印象会更深,以后写代码的时候就能应用起来:第二,通过阅读优秀的开源代码,可以学习比人的代码规范.设计思路:第三,参与到开源社区,获得更广阔的的发展前景:第四,面试加分项.所以,有时间的话还是建议大家多读读优秀开源项目的源码. 下面进入今天的主题,这个开源项目的名字叫Rich,地址:https://github.com/wil