一文彻底掌握RocketMQ 的存储模型
目录
- RocketMQ简介
- 1 整体概览
- 2 数据文件
- 3 消费文件
- 4 索引文件
- 5 写到最后
RocketMQ简介
RocketMQ有Producer、Consumer、NameSrv、Broker四个部分。其中Broker用于存储消息,维护消息队列和订阅关系,是RocketMQ四个部分中最重要的一个部分,并且RocketMQ的高性能就是依赖于Broker模块的底层存储模型实现的。所以搞清楚Broker的存储模型是学习RocketMQ最重要的一步。
RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型 。
这篇文章,笔者按照自己的理解 , 尝试分析 RocketMQ 的存储模型,希望对大家有所启发。

1 整体概览
首先温习下 RocketMQ 架构。
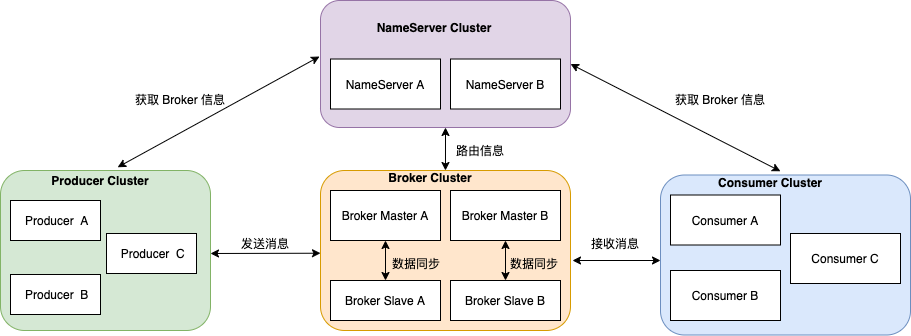
整体架构中包含四种角色 :
- Producer :消息发布的角色,Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
- Consumer :消息消费的角色,支持以 push 推,pull 拉两种模式对消息进行消费。
- NameServer :名字服务是一个非常简单的 Topic 路由注册中心,其角色类似 Dubbo 中的 zookeeper ,支持 Broker 的动态注册与发现。
- BrokerServer :Broker 主要负责消息的存储、投递和查询以及服务高可用保证 。
本文的重点在于分析 BrokerServer 的消息存储模型。我们先进入 broker 的文件存储目录 。

消息存储和下面三个文件关系非常紧密:
- 数据文件 commitlog
消息主体以及元数据的存储主体 ;
- 消费文件 consumequeue
消息消费队列,引入的目的主要是提高消息消费的性能 ;
- 索引文件 index
索引文件,提供了一种可以通过 key 或时间区间来查询消息。
RocketMQ 采用的是混合型的存储结构,Broker 单个实例下所有的队列共用一个数据文件(commitlog)来存储。
生产者发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 commitlog 文件中。只要消息被刷盘持久化至磁盘文件 commitlog 中,那么生产者发送的消息就不会丢失。
Broker 端的后台服务线程会不停地分发请求并异步构建 consumequeue(消费文件)和 indexFile(索引文件)。
2 数据文件
RocketMQ 的消息数据都会写入到数据文件中, 我们称之为 commitlog 。
所有的消息都会顺序写入数据文件,当文件写满了,会写入下一个文件。

如上图所示,单个文件大小默认 1G , 文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0 ,文件大小为1 G = 1073741824。
当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。

从上图中,我们可以看到消息是一条一条写入到文件,每条消息的格式是固定的。
这样设计有三点优势:
- 顺序写
磁盘的存取速度相对内存来讲并不快,一次磁盘 IO 的耗时主要取决于:寻道时间和盘片旋转时间,提高磁盘 IO 性能最有效的方法就是:减少随机 IO,增加顺序 IO 。

《 The Pathologies of Big Data 》这篇文章指出:内存随机读写的速度远远低于磁盘顺序读写的速度。磁盘顺序写入速度可以达到几百兆/s,而随机写入速度只有几百 KB /s,相差上千倍。
- 快速定位
因为消息是一条一条写入到 commitlog 文件 ,写入完成后,我们可以得到这条消息的物理偏移量。
每条消息的物理偏移量是唯一的, commitlog 文件名是递增的,可以根据消息的物理偏移量通过二分查找,定位消息位于那个文件中,并获取到消息实体数据。
- 通过消息 offsetMsgId 查询消息数据

消息 offsetMsgId 是由 Broker 服务端在写入消息时生成的 ,该消息包含两个部分:
- Broker 服务端 ip + port 8个字节;
- commitlog 物理偏移量 8个字节 。
我们可以通过消息 offsetMsgId ,定位到 Broker 的 ip 地址 + 端口 ,传递物理偏移量参数 ,即可定位该消息实体数据。
3 消费文件
在介绍 consumequeue 文件之前, 我们先温习下消息队列的传输模型-发布订阅模型 , 这也是 RocketMQ 当前的传输模型。

发布订阅模型具有如下特点:
- 消费独立:相比队列模型的匿名消费方式,发布订阅模型中消费方都会具备的身份,一般叫做订阅组(订阅关系),不同订阅组之间相互独立不会相互影响。
- 一对多通信:基于独立身份的设计,同一个主题内的消息可以被多个订阅组处理,每个订阅组都可以拿到全量消息。因此发布订阅模型可以实现一对多通信。
因此,rocketmq 的文件设计必须满足发布订阅模型的需求。
那么仅仅 commitlog 文件是否可以满足需求吗 ?
假如有一个 consumerGroup 消费者,订阅主题 my-mac-topic ,因为 commitlog 包含所有的消息数据,查询该主题下的消息数据,需要遍历数据文件 commitlog , 这样的效率是极其低下的。
进入 rocketmq 存储目录,显示见下图:

- 消费文件按照主题存储,每个主题下有不同的队列,图中 my-mac-topic 有 16 个队列 ;
- 每个队列目录下 ,存储 consumequeue 文件,每个 consumequeue 文件也是顺序写入,数据格式见下图。

每个 consumequeue 包含 30 万个条目,每个条目大小是 20 个字节,每个文件的大小是 30 万 * 20 = 60万字节,每个文件大小约5.72M 。和 commitlog 文件类似,consumequeue 文件的名称也是以偏移量来命名的,可以通过消息的逻辑偏移量定位消息位于哪一个文件里。
消费文件按照主题-队列来保存 ,这种方式特别适配发布订阅模型。
消费者从 broker 获取订阅消息数据时,不用遍历整个 commitlog 文件,只需要根据逻辑偏移量从 consumequeue 文件查询消息偏移量 , 最后通过定位到 commitlog 文件, 获取真正的消息数据。
这样就可以简化消费查询逻辑,同时因为同一主题下,消费者可以订阅不同的队列或者 tag ,同时提高了系统的可扩展性。
4 索引文件
每个消息在业务层面的唯一标识码要设置到 keys 字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过 topic、key 来查询这条消息内容,以及消息被谁消费。
由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
//订单Id String orderId = "1234567890"; message.setKeys(orderId);
从开源的控制台中根据主题和 key 查询消息列表:

进入索引文件目录 ,如下图所以:

索引文件名 fileName 是以创建时的时间戳命名的,固定的单个 IndexFile 文件大小约为 400 M 。
IndexFile 的文件逻辑结构类似于 JDK 的 HashMap 的数组加链表结构。

索引文件主要由 Header、Slot Table (默认 500 万个条目)、Index Linked List(默认最多包含 2000万个条目)三部分组成 。

假如订单系统发送两条消息 A 和 B , 他们的 key 都是 "1234567890" ,我们依次存储消息 A , 消息 B 。
因为这两个消息的 key 的 hash 值相同,它们对应的哈希槽(深黄色)也会相同,哈希槽会保存的最新的消息 B 的索引条目序号 , 序号值是 4 ,也就是第二个深绿色条目。
而消息 B 的索引条目信息的最后 4 个字节会保存上一条消息对应的索引条目序号,索引序号值是 3 , 也就是消息 A 。
5 写到最后
Databases are specializing – the “one size fits all” approach no longer applies ------ MongoDB设计哲学
RocketMQ 存储模型设计得非常精巧,笔者觉得每种设计都有其底层思考,这里总结了三点 :
- 完美适配消息队列发布订阅模型 ;
- 数据文件,消费文件,索引文件各司其职 ,同时以数据文件为核心,异步构建消费文件 + 索引文件这种模式非常容易扩展到主从复制的架构;
- 充分考虑业务的查询场景,支持消息 key ,消息 offsetMsgId 查询消息数据。也支持消费者通过 tag 来订阅主题下的不同消息,提升了消费者的灵活性。
到此这篇关于终于弄明白了 RocketMQ 的存储模型的文章就介绍到这了,更多相关 RocketMQ 存储模型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
RocketMQ特性Broker存储事务消息实现
目录 引言 TransactionalMessageService 处理事务消息 第一处: 第二处: 引言 在Broker中,事务消息的初始化是通过BrokerController.initialTransaction()方法执行的. private void initialTransaction() { this.transactionalMessageService = ServiceProvider.loadClass(ServiceProvider.TRANSACTION_SERVICE
-

RocketMQ存储文件的实现
RocketMQ存储路径默认是${ROCKRTMQ_HOME}/store,主要存储消息.主题对应的消息队列的索引等. 1.概述 查看其目录文件 commitlog:消息的存储目录 config:运行期间一些配置信息 consumequeue:消息消费队列存储目录 index:消息索引文件存储目录 abort:如果存在abort文件说明Broker非正常关闭,该文件默认启动时创建,正常退出时删除 checkpoint:文件检测点.存储commitlog文件最后一次刷盘时间戳.consumeque
-
rocketmq如何修改存储路径
一.下载rocketmq对应版本源码 修改消息存储路径需要修改rocketmq源码,因为rocketmq取的默认路径是user.home路径,也就是用户的根目录,如下所示 直接修改用户的user.home比较麻烦,我们打算直接修改源码里写死的路径,然后重新打包 下载rocketmq源码可以去GitHub,路径为https://github.com/apache/rocketmq 如果要下4.7.1版本的源码包可以选择对应release包 例如使用的rocketmq版本为4.7.1,则下载路径为h
-
一文彻底掌握RocketMQ 的存储模型
目录 RocketMQ简介 1 整体概览 2 数据文件 3 消费文件 4 索引文件 5 写到最后 RocketMQ简介 RocketMQ有Producer.Consumer.NameSrv.Broker四个部分.其中Broker用于存储消息,维护消息队列和订阅关系,是RocketMQ四个部分中最重要的一个部分,并且RocketMQ的高性能就是依赖于Broker模块的底层存储模型实现的.所以搞清楚Broker的存储模型是学习RocketMQ最重要的一步. RocketMQ 优异的性能表现,必然绕不
-
RocketMQ Push 消费模型示例详解
目录 使用 DefaultMQPushConsumer 消费消息 基于长轮询机制的伪 push 实现 客户端侧发起的长轮询请求 服务端阻塞请求 客户端回调处理 客户端发起请求的底层逻辑 PullCallback 回调 总结 Push 模式是指由 Server 端来控制消息的推送,即当有消息到 Server 之后,会将消息主动投递给 client(Consumer 端). 使用 DefaultMQPushConsumer 消费消息 下面是使用 DefaultMQPushConsumer 消费消息的
-
Java 存储模型和共享对象详解
Java 存储模型和共享对象详解 很多程序员对一个共享变量初始化要注意可见性和安全发布(安全地构建一个对象,并其他线程能正确访问)等问题不是很理解,认为Java是一个屏蔽内存细节的平台,连对象回收都不需要关心,因此谈到可见性和安全发布大多不知所云.其实关键在于对Java存储模型,可见性和安全发布的问题是起源于Java的存储结构. Java存储模型原理 有很多书和文章都讲解过Java存储模型,其中一个图很清晰地说明了其存储结构: 由上图可知, jvm系统中存在一个主内存(Main Memory或J
-
laravel学习教程之关联模型
Eloquent: 关联模型 简介 数据库中的表经常性的关联其它的表.比如,一个博客文章可以有很多的评论,或者一个订单会关联一个用户.Eloquent 使管理和协作这些关系变的非常的容易,并且支持多种不同类型的关联: 一对一 一对多 多对多 远程一对多 多态关联 多态多对多关联 定义关联 Eloquent 关联可以像定义方法一样在 Eloquent 模型类中进行定义.同时,它就像 Eloquent 模型自身一样也提供了强大的查询生成器.这允许关联模
-
深入了解MongoDB是如何存储数据的
前言 本文主要介绍了关于MongoDB存储数据的相关内容,分享出来供大家参考学习,下面来一起看看详细的介绍: 想要深入了解MongoDB如何存储数据之前,有一个概念必须清楚,那就是Memeory-Mapped Files. Memeory-Mapped Files 下图展示了数据库是如何跟底层系统打交道的. 内存映射文件是OS通过mmap在内存中创建一个数据文件,这样就把文件映射到一个虚拟内存的区域. 虚拟内存对于进程来说,是一个物理内存的抽象,寻址空间大小为2^64 操作系统通过mmap来把进
-
RocketMQ消息丢失场景以及解决方法
既然使用在项目中使用了MQ,那么就不可避免的需要考虑消息丢失问题.在一些涉及到了金钱交易的场景下,消息丢失还是很致命的.那么在RocketMQ中存在哪几种消息丢失的场景呢? 先来一张最简单的消费流程图: 上图中大致包含了这么几种场景: 生产者产生消息发送给RocketMQRocketMQ接收到了消息之后,必然需要存到磁盘中,否则断电或宕机之后会造成数据的丢失消费者从RocketMQ中获取消息消费,消费成功之后,整个流程结束 这三种场景都可能会产生消息的丢失,如下图所示: 场景1中生产者将消息发送
-
VGG16模型的复现及其详解(包含如何预测)
目录 神经网络学习小记录16——VGG16模型的复现详解 学习前言什么是VGG16模型VGG网络部分实现代码图片预测 学习前言 学一些比较知名的模型对身体有好处噢! 什么是VGG16模型 VGG是由Simonyan 和Zisserman在文献<Very Deep Convolutional Networks for Large Scale Image Recognition>中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写.该
-
iOS中的应用启动原理以及嵌套模型开发示例详解
程序启动原理和UIApplication 一.UIApplication 1.简单介绍 (1)UIApplication对象是应用程序的象征,一个UIApplication对象就代表一个应用程序. (2)每一个应用都有自己的UIApplication对象,而且是单例的,如果试图在程序中新建一个UIApplication对象,那么将报错提示. (3)通过[UIApplicationsharedApplication]可以获得这个单例对象 (4) 一个iOS程序启动后创建的第一个对象就是UIAp
-
MongoDB系列教程(八):GridFS存储详解
GridFS简介 mongoDB的文档以BSON格式存储,支持二进制的数据类型,当我们把二进制格式的数据直接保存到mongoDB的文档中.但是当文件太大时,例如图片和视频等文件,每个文档的长度是有限的,于是mongoDb会提供了一种处理大文件的规范--GridFS. GridFS实现原理 在GridFS数据库中,默认使用fs.chunks 和fs.files来存储文件,其中fs.files集合存放文件的信息,fs.chunks存放文件的数据,一个fs.files集合中的一条记录内容如下,即一个f