create vite 实例源码解析
目录
- 代码结构
- init()
- projectName:项目名称
- overwrite:是否覆盖已存在的目录
- overwriteChecker:检测覆盖的目录是否为空
- framework:框架
- variant:语言
- 获取用户输入
- 清空目录
- 生成项目
- 确定项目模板
- 确定包管理器
- 正式生成项目
- 创建package.json
- 完成
- 总结
代码结构
create-vite的源码很简单,只有一个文件,代码总行数400左右,但是实际需要阅读的代码大约只有200行左右,废话不多说,直接开始吧。
create-vite的代码结构非常简单,直接将index.ts拉到最底下,发现只执行了一个函数init():
init().catch((e) => {
console.error(e)
})
我们的故事将从这里开始。
init()
init()函数的代码有点长,但是实际上也不复杂,我们先来看看它最开头的两行代码:
async function init() {
const argTargetDir = formatTargetDir(argv._[0])
const argTemplate = argv.template || argv.t
}
首先可以看到init函数是一个异步函数,最开始的两行代码分别获取了argv._[0]和argv.template或者argv.t;
这个argv是怎么来的,当然是通过一个解析包来解析的,在顶部有这样的一段代码:
const argv = minimist(process.argv.slice(2), { string: ['_'] })
就是这个minimist包,它的作用就是解析命令行参数,感兴趣的可以自行了解,据说这个包也是百来行代码。
继续往下,这两个参数就是我们在执行create-vite命令时传入的参数,比如:
create-vite my-vite-app
那么argv._[0]就是my-vite-app;
如果我们执行的是:
create-vite my-vite-app --template vue
那么argv.template就是vue。
argv.t就是argv.template的简写,相当于:
create-vite my-vite-app --t vue # 等价于 create-vite my-vite-app --template vue

通过打断点的方式,可以看到结果和我们预想的一样。
formatTargetDir(argv._[0])就是格式化我们传入的目录,它会去掉目录前后的空格和最后的/,比如:
formatTargetDir(' my-vite-app ') // my-vite-app
formatTargetDir(' my-vite-app/') // my-vite-app
这个代码很简单,就不贴出来了,继续往下:
let targetDir = argTargetDir || defaultTargetDir
targetDir是我们最终要创建的目录,defaultTargetDir的值是vite-project,如果我们没有传将会用这个值来兜底。
紧接着后面跟着一个getProjectName的函数,通常来讲这种代码可以跳过先不看,但是这里的getProjectName函数有点特殊;
const getProjectName = () => targetDir === '.' ? path.basename(path.resolve()) : targetDir
它会根据targetDir的值来判断我们的项目是不是在当前目录下创建的,如果是的话,就会返回当前目录的名字,比如:
create-vite .
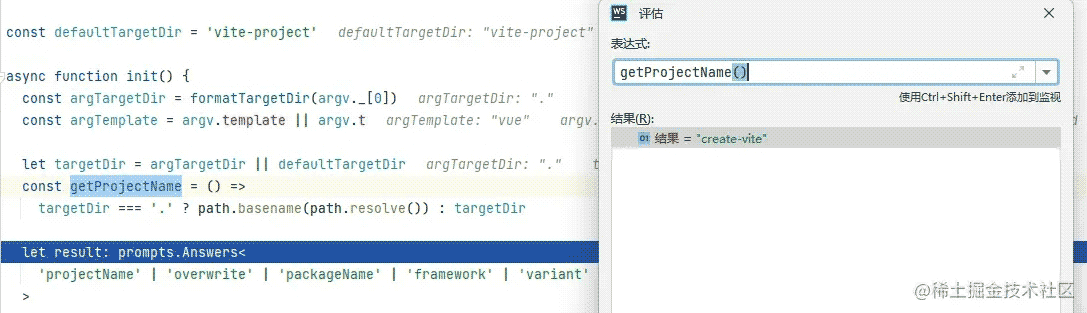
可以看到如果项目名称传的是.,那么getProjectName函数就会返回当前目录的名字,也就是create-vite(根据自己的情况而定);
不看源码还真不知道这里还可以这么用,继续往下,就是定义了一个问题数组:
result = await prompts([])
这个prompts函数是一个交互式命令行工具,它会根据我们传入的问题数组来进行交互,就比如源码中,一共列出了6个问题:
projectName:项目名称overwrite:是否覆盖已存在的目录overwriteChecker:检测覆盖的目录是否为空packageName:包名framework:框架variant:语言
当执行create-vite命令时,后面不跟着任何参数,而且我们一切操作都是合规的,那么只会经历三个问题:
projectName:项目名称framework:框架variant:语言
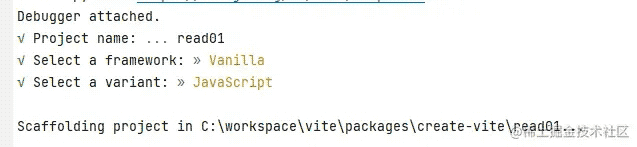
projectName:项目名称
配置项如下:
var projectName = {
type: argTargetDir ? null : 'text',
name: 'projectName',
message: reset('Project name:'),
initial: defaultTargetDir,
onState: (state) => {
targetDir = formatTargetDir(state.value) || defaultTargetDir
}
}
先来简单介绍一个每一个配置项的含义:
type:问题的类型,这里的null表示不需要用户输入,直接跳过这个问题,这个配置项的值可以是text、select、confirm等,具体可以看这里;name:问题的名称,这里的projectName是用来在prompts函数的返回值中获取这个问题的答案的;message:问题的描述,这里的Project name:是用来在命令行中显示的;initial:问题的默认值,这里的defaultTargetDir是用来在命令行中显示的;onState:问题的回调函数,每次用户输入的时候都会触发这个函数,这里的state就是用户输入的值;
可以看到这里的type配置是根据argTargetDir的值来决定的,如果argTargetDir有值,那么就会跳过这个问题,直接使用argTargetDir的值作为项目名称;
如果在使用create-vite命令时,后面跟着了项目名称,那么argTargetDir就有值了,也就是会跳过这个问题,后面的属性就没什么好分析了,接着往下。
overwrite:是否覆盖已存在的目录
配置项如下:
var overwrite = {
type: () =>
!fs.existsSync(targetDir) || isEmpty(targetDir) ? null : 'confirm',
name: 'overwrite',
message: () =>
(targetDir === '.'
? 'Current directory'
: `Target directory "${targetDir}"`) +
` is not empty. Remove existing files and continue?`
}
这里的type配置项是一个函数,这个函数的返回值是null或者confirm;
如果targetDir目录不存在,或者targetDir目录下面没有东西,那么就会跳过这个问题,直接使用null作为type的值;
message配置项也是一个函数,这个函数的返回值是一个字符串,这个字符串就是在命令行中显示的内容;
同样因为人性化的考虑,会显示不同的提示语来帮助用户做出选择;
overwriteChecker:检测覆盖的目录是否为空
配置项如下:
var overwriteChecker = {
type: (_, {overwrite}: { overwrite?: boolean }) => {
if (overwrite === false) {
throw new Error(red('') + ' Operation cancelled')
}
return null
},
name: 'overwriteChecker'
}
overwriteChecker会在overwrite问题之后执行,这里的type配置项是一个函数,里面接收了两个参数;
第一个参数名为_,通常这种行为是占位的,表示这个参数没有用到,但是又不能省略;
第二个参数是一个对象,这个对象里面有一个overwrite属性,这个属性就是overwrite问题的答案;
他通过overwrite的值来判断用户是否选择了覆盖,如果选择了覆盖,就会跳过这个问题;
否则的话就证明这个目录下面存在文件,那么就会抛出一个错误,这里抛出错误是会终止整个命令的执行的;
这一部分,在定义问题数组的时候有做处理,使用try...catch来捕获错误,如果有错误,就会使用return来终止整个命令的执行;
try {
result = await prompts([])
} catch (cancelled: any) {
console.log(cancelled.message)
return
}
packageName:包名
配置项如下:
var packageName = {
type: () => (isValidPackageName(getProjectName()) ? null : 'text'),
name: 'packageName',
message: reset('Package name:'),
initial: () => toValidPackageName(getProjectName()),
validate: (dir) =>
isValidPackageName(dir) || 'Invalid package.json name'
}
这里的type配置项是一个函数,里面通过isValidPackageName来判断项目名称是否是一个合法的包名;
getProjectName在上面已经介绍过了,这里就不再赘述;
isValidPackageName是用来判断包名是否合法的,这个函数的实现如下:
function isValidPackageName(projectName: string) {
return /^(?:@[a-z\d-*~][a-z\d-*._~]*/)?[a-z\d-~][a-z\d-._~]*$/.test(
projectName
)
}
validate用来验证用户输入的内容是否合法,如果不合法,就会显示Invalid package.json name;
framework:框架
配置项如下:
var framework = {
type:
argTemplate && TEMPLATES.includes(argTemplate) ? null : 'select',
name: 'framework',
message:
typeof argTemplate === 'string' && !TEMPLATES.includes(argTemplate)
? reset(
`"${argTemplate}" isn't a valid template. Please choose from below: `
)
: reset('Select a framework:'),
initial: 0,
choices: FRAMEWORKS.map((framework) => {
const frameworkColor = framework.color
return {
title: frameworkColor(framework.display || framework.name),
value: framework
}
})
}
这里的就相对来说复杂了点,首先判断了argTemplate是否存在,如果存在,就会判断argTemplate是否是一个合法的模板;
TEMPLATES的定义是通过FRAMEWORKS来生成的:
const TEMPLATES = FRAMEWORKS.map((f) => {
const variants = f.variants || [];
const names = variants.map((v) => v.name);
return names.length ? names : [f.name];
}).reduce((a, b) => a.concat(b), [])
这里我将代码拆分了一下,这样看着会更清晰一点,最后的reduce的作用应该是对值进行一个拷贝处理;
源码里面的map返回的都是引用值,所以需要进行拷贝(这是我猜测的),源码如下:
const TEMPLATES = FRAMEWORKS.map( (f) => (f.variants && f.variants.map((v) => v.name)) || [f.name] ).reduce((a, b) => a.concat(b), [])
FRAMEWORKS是写死的一个数组,代码很长,就不贴出来了,这里就贴一下type的定义:
type Framework = {
name: string
display: string
color: ColorFunc
variants: FrameworkVariant[]
}
type FrameworkVariant = {
name: string
display: string
color: ColorFunc
customCommand?: string
}
name是框架的名称;display是显示的名称;color是颜色;variants是框架的语言,比如react有typescript和javascript两种语言;customCommand是自定义的命令,比如vue的vue-cli就是自定义的命令;
分析到这里,再回头看看framework的配置项,就很好理解了,这里的choices就是通过FRAMEWORKS来生成的:
var framework = {
choices: FRAMEWORKS.map((framework) => {
const frameworkColor = framework.color
return {
title: frameworkColor(framework.display || framework.name),
value: framework
}
})
}
choices是一个数组,用于表示type为select时的选项,数组的每一项都是一个对象,对象的title是显示的名称,value是选中的值;
上面的代码就是用来生成choices的,frameworkColor是一个颜色函数,用来给framework.display或者framework.name上色;
variant:语言
配置项如下:
var variant = {
type: (framework: Framework) =>
framework && framework.variants ? 'select' : null,
name: 'variant',
message: reset('Select a variant:'),
choices: (framework: Framework) =>
framework.variants.map((variant) => {
const variantColor = variant.color
return {
title: variantColor(variant.display || variant.name),
value: variant.name
}
})
}
这里的type是一个函数,函数的第一个参数就是framework,这里的type是根据framework来判断的,如果framework存在并且framework.variants存在,就让用户继续这一个问题。
通过之前的分析,这一块应该都能看明白,就继续往下走;
获取用户输入
接着往下走就是获取用户输入了,用户回答完所有问题后,结果会返回到result中,可以用过解构的方式来获取:
const { framework, overwrite, packageName, variant } = result
清空目录
接着就是对生成项目的位置进行处理,根据上面分析的逻辑,会有目录下有文件的情况,所以需要先清空目录:
// 确定项目生成的目录
const root = path.join(cwd, targetDir)
// 清空目录
if (overwrite) {
emptyDir(root)
} else if (!fs.existsSync(root)) {
fs.mkdirSync(root, {recursive: true})
}
emptyDir是一个清空目录的方法,fs.existsSync是用来判断目录是否存在的,如果不存在就创建一个;
function emptyDir(dir: string) {
// 如果目录不存在,啥也不管
if (!fs.existsSync(dir)) {
return
}
// 读取目录下的所有文件
for (const file of fs.readdirSync(dir)) {
// 忽略 .git 的目录
if (file === '.git') {
continue
}
// 删除文件,如果是目录就递归删除
fs.rmSync(path.resolve(dir, file), { recursive: true, force: true })
}
}
existsSync第二个参数是一个对象,recursive表示是否递归创建目录,如果目录不存在,就会创建目录,如果目录存在,就会报错;
生成项目
继续往下走,就是生成项目相关的,最开始肯定是确定项目的内容。
确定项目模板
// 确定项目模板 const template: string = variant || framework?.name || argTemplate
这里的template就是项目的模板,如果用户选择了variant,那么就用variant,如果没有选择,就用framework,如果framework不存在,就用argTemplate;
这些变量代表什么,从哪来的上面都有分析。
确定包管理器
const pkgInfo = pkgFromUserAgent(process.env.npm_config_user_agent)
这里的process.env.npm_config_user_agent并不是我们自己定义的,是npm自己定义的;
这个变量值是指的当前运行环境的包管理器,比如npm,yarn等等,当然这个值肯定没我写的这么简单;
通过debug可以看到我的值是pnpm/7.17.0 npm/? node/v14.19.2 win32 x64,每个人的值根据环境的不同而不同;
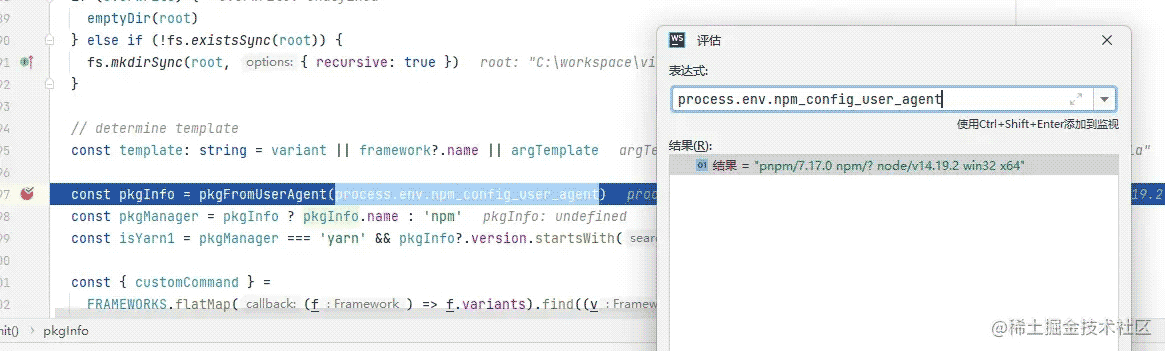
pkgFromUserAgent是一个解析userAgent的方法,大白话就是解析包管理器的名称和版本号;
例如{name: 'npm', version: '7.17.0'},代码如下:
function pkgFromUserAgent(userAgent: string | undefined) {
if (!userAgent) return undefined
const pkgSpec = userAgent.split(' ')[0]
const pkgSpecArr = pkgSpec.split('/')
return {
name: pkgSpecArr[0],
version: pkgSpecArr[1]
}
}
这个代码也没那么高深,就是解析字符串,然后返回一个对象,给你写也一定可以写出来的;
后面两段代码就是正式确定包管理器的名称和版本号了,代码如下:
const pkgManager = pkgInfo ? pkgInfo.name : 'npm'
const isYarn1 = pkgManager === 'yarn' && pkgInfo?.version.startsWith('1.')
yarn的版本如果是1.x后面会有一些特殊处理,所以会有isYarn1这个变量;
接着就是确定包管理器的命令了,代码如下:
const { customCommand } =
FRAMEWORKS.flatMap((f) => f.variants).find((v) => v.name === template) ?? {}
这一段是用来确定部分模板的包管理器命令的,比如vue-cli,vue-cli的包管理器命令是vue,会有不一样的命令;
if (customCommand) {
const fullCustomCommand = customCommand
.replace('TARGET_DIR', targetDir)
.replace(/^npm create/, `${pkgManager} create`)
// Only Yarn 1.x doesn't support `@version` in the `create` command
.replace('@latest', () => (isYarn1 ? '' : '@latest'))
.replace(/^npm exec/, () => {
// Prefer `pnpm dlx` or `yarn dlx`
if (pkgManager === 'pnpm') {
return 'pnpm dlx'
}
if (pkgManager === 'yarn' && !isYarn1) {
return 'yarn dlx'
}
// Use `npm exec` in all other cases,
// including Yarn 1.x and other custom npm clients.
return 'npm exec'
})
const [command, ...args] = fullCustomCommand.split(' ')
const {status} = spawn.sync(command, args, {
stdio: 'inherit'
})
process.exit(status ?? 0)
}
这里的处理代码比较多,但是也没什么好看的,就是各种替换字符串,然后生成最终的命令;
正式生成项目
接下来就是重点了,首先确定模板的位置,代码如下:
const templateDir = path.resolve(
fileURLToPath(import.meta.url),
'../..',
`template-${template}`
)
这里的import.meta.url是当前ES模块的绝对路径,这里是一个知识点。
import大家都知道是用来导入模块的,但是import.meta是什么呢?
import.meta是一个对象,它的属性和方法提供了有关模块的信息,比如url就是当前模块的绝对路径;
同时他还允许在模块中添加自定义的属性,比如import.meta.foo = 'bar',这样就可以在模块中使用import.meta.foo了;
所以我们在vite项目中可以使用import.meta.env来获取环境变量,比如import.meta.env.MODE就是当前的模式;
点到为止,我们继续看代码,这一段就是确定模板的位置,应该都看的懂;
后面就是读取模板文件,然后生成项目了,代码如下:
const files = fs.readdirSync(templateDir)
// package.json 不需要写进去
for (const file of files.filter((f) => f !== 'package.json')) {
write(file)
}
这里的write函数就是用来生成项目的,代码如下:
const write = (file: string, content?: string) => {
const targetPath = path.join(root, renameFiles[file] ?? file)
if (content) {
fs.writeFileSync(targetPath, content)
} else {
copy(path.join(templateDir, file), targetPath)
}
}
根据上面的逻辑这个分析直接简化为:
const write = (file: string) => {
const targetPath = path.join(root, file)
copy(path.join(templateDir, file), targetPath)
}
这个没啥好说的,然后就到了copy函数的分析了,代码如下:
function copy(src: string, dest: string) {
const stat = fs.statSync(src)
if (stat.isDirectory()) {
copyDir(src, dest)
} else {
fs.copyFileSync(src, dest)
}
}
这里的copy函数就是用来复制文件的,如果是文件夹就调用copyDir函数,代码如下:
function copyDir(srcDir: string, destDir: string) {
fs.mkdirSync(destDir, { recursive: true })
for (const file of fs.readdirSync(srcDir)) {
const srcFile = path.resolve(srcDir, file)
const destFile = path.resolve(destDir, file)
copy(srcFile, destFile)
}
}
这里的fs.mkdirSync函数就是用来创建文件夹的,recursive参数表示如果父级文件夹不存在就创建父级文件夹;
这里的fs.readdirSync函数就是用来读取文件夹的,返回一个数组,数组中的每一项就是文件夹中的文件名;
最后通过递归调用copy函数来复制文件夹中的文件;
创建package.json
接下来是对package.json文件的单独处理,代码如下:
// 获取模板中的 package.json
const pkg = JSON.parse(
fs.readFileSync(path.join(templateDir, `package.json`), 'utf-8')
)
// 修改 package.json 中的 name 值
pkg.name = packageName || getProjectName()
// 写入 package.json
write('package.json', JSON.stringify(pkg, null, 2))
这里的pkg就是模板中的package.json文件,然后修改name字段,最后写入到项目中;
之前不复制package.json是因为这里会修改name字段,如果复制了你的项目的name属性就不正确。
完成
console.log(`\nDone. Now run:\n`)
if (root !== cwd) {
console.log(` cd ${path.relative(cwd, root)}`)
}
switch (pkgManager) {
case 'yarn':
console.log(' yarn')
console.log(' yarn dev')
break
default:
console.log(` ${pkgManager} install`)
console.log(` ${pkgManager} run dev`)
break
}
console.log()
最后就是一些提示信息,如果你的项目不在当前目录下,就会提示你cd到项目目录下,然后根据你的包管理器来提示你安装依赖和启动项目。
总结
整体下来这个脚手架的实现还是比较简单的,整体非常清晰:
- 通过
minimist来解析命令行参数; - 通过
prompts来交互式的获取用户输入; - 确认用户输入的信息,整合项目信息;
- 通过
node的fs模块来创建项目; - 最后提示用户如何启动项目。
代码不多,但是整体走下来还是有很多细节的,例如:
- 以后写
node项目的时候知道怎么获取命令行参数; - 用户命令行的交互式输入,里面用户体验是非常好的,这个可以在很多地方是做为参考;
fs模块的使用,这个模块是node中非常重要的模块;node中的path模块,这个模块也是非常重要的,很多地方都会用到;import的知识点,真的学到了。
以上就是create vite 实例源码解析的详细内容,更多关于create vite源码解析的资料请关注我们其它相关文章!
相关推荐
-
Create vite理解Vite项目创建流程及代码实现
目录 前言 monorepo 主流程 入口文件 主要结构 扩展插件 模板配置 getProjectName formatTargetDir npm包名验证和转化 取得模板目录 得到npm包管理器相关信息 文件操作相关的函数 write函数 写入文件 copy函数 复制文件 copyDir 复制目录 emptyDir 清空目录 isEmpty 判断目录为空 核心代码 总结 前言 继上次阅读create-vue后 ,本次接着来解析 create-vite, 得益于之前的阅读经验, 本篇笔记将会着重讲
-

Vite的createServer启动源码解析
目录 启动Vite的createServer 通过vite3安装一个vue的工程 添加断点并开启调试 边调试边理解代码 启动Vite的createServer 为了能够了解vite里面运行了什么,通过执行单步调试能够更加直观的知道Vite具体内容.所以这次我们来试着启动Vite的createServer,并进行调试. 通过vite3安装一个vue的工程 进入工作目录,运行下面的代码,项目名称随意,语言用Vue. npm create vite 进入工程目录安装依赖 添加断点并开启调试 通过vsc
-
创建项目及包管理yarn create vite源码学习
目录 1.引言 2.走进“yarn create vite”的源码 2.1 Vite 创建项目的方式: 2.1.1 终端交互方式创建项目: 2.1.2 终端指定模版创建项目: 2.2 源码分析: 2.2.1 终端参数解析: 2.2.2 交互收集数据: 2.2.3 目录初始化: 2.2.4 拷贝模板文件夹: 2.2.5 重写 gitignore 名称: 2.2.6 重写 package 字段: 2.2.7 后续操作提示: 3. 总结 1.引言 我们在编程学习的过程中也会写一些项目的模板,这样的模板
-
vite+element-plus项目基础搭建的全过程
目录 1.引言 2.为什么是Vite? 3.为什么是Element-plus? 4.项目搭建 5.参考文献 总结 1.引言 其实本来不应该写这种CSDN比较多的博文的,主要是因为比较多,然后想解决问题的时候有很多各种各样的文章,然后这些文章有各自的解决思路,甚至拿过来又不能解决问题,本着分享和方便以后使用的目的,记录这次使用过程. 2.为什么是Vite? 其实我最开始用的是vue-cli,但是使用的时候发现这个每次运行的时候都需要打包,导致运行的比较慢,得等个10几秒.加上看到Element-p
-
webpack项目中使用vite加速的兼容模式详解
目录 前言 目的 要处理的问题 动手 共用 index.html 共用配置 兼容环境变量 自动导入 资源引入 svg-sprite-loader 替代方案 其他 效果 前言 随着公司前端工程越来越大,启动是无尽的等待,修改是焦急的等待. vite 到现在生态也起来了,就有了把项目改造成 vite 的想法,但是项目后面可能要依赖 qiankun 改造成微前端项目,现在 qiankun 对 vite 还没有好的解决方法,我就想采取一个折中的办法,保留 webpack,再兼容 vite,两条路都留着.
-
vite前端构建Turborepo高性能monorepo方案
目录 引言 什么是monorepo ? 引言 之前的一篇文章我选择了go做前端的cli工具链,现在出现了新的项目构建神器Turborepo用于Monorepo 方案. 什么是monorepo ? Monorepo是一种项目管理方式,在Monorepo之前,代码仓库管理方式是 MultiRepo,即每个项目都对应着一个单独的代码仓库每个项目进行分散管理 这就会导致许多弊端,例如可能每个项目的基建以及工具库都是差不多的,基础代码的重复复用问题等等... TurboRepo 是构建Javascript
-
create vite 实例源码解析
目录 代码结构 init() projectName:项目名称 overwrite:是否覆盖已存在的目录 overwriteChecker:检测覆盖的目录是否为空 framework:框架 variant:语言 获取用户输入 清空目录 生成项目 确定项目模板 确定包管理器 正式生成项目 创建package.json 完成 总结 代码结构 create-vite的源码很简单,只有一个文件,代码总行数400左右,但是实际需要阅读的代码大约只有200行左右,废话不多说,直接开始吧. create-vi
-
jq源码解析之绑在$,jQuery上面的方法(实例讲解)
1.当我们用$符号直接调用的方法.在jQuery内部是如何封装的呢?有没有好奇心? // jQuery.extend 的方法 是绑定在 $ 上面的. jQuery.extend( { //expando 用于决定当前页面的唯一性. /\D/ 非数字.其实就是去掉小数点. expando: "jQuery" + ( version + Math.random() ).replace( /\D/g, "" ), // Assume jQuery is ready wit
-
Vue3源码解析watch函数实例
目录 引言 一.watch参数类型 1. 选项options 2. 回调cb 3. 数据源source 二.watch函数 三.watch的核心:doWatch 函数 引言 想起上次面试,问了个古老的问题:watch和computed的区别.多少有点感慨,现在已经很少见这种耳熟能详的问题了,网络上八股文不少.今天,我更想分享一下从源码的层面来区别这八竿子打不着的两者.本篇针对watch做分析,下一篇分析computed. 一.watch参数类型 我们知道,vue3里的watch接收三个参数:侦听
-
Laravel源码解析之路由的使用和示例详解
前言 我的解析文章并非深层次多领域的解析攻略.但是参考着开发文档看此类文章会让你在日常开发中更上一层楼. 废话不多说,我们开始本章的讲解. 入口 Laravel启动后,会先加载服务提供者.中间件等组件,在查找路由之前因为我们使用的是门面,所以先要查到Route的实体类. 注册 第一步当然还是通过服务提供者,因为这是laravel启动的关键,在 RouteServiceProvider 内加载路由文件. protected function mapApiRoutes() { Route::pref
-
Vue源码解析之数组变异的实现
力有不逮的对象 众所周知,在 Vue 中,直接修改对象属性的值无法触发响应式.当你直接修改了对象属性的值,你会发现,只有数据改了,但是页面内容并没有改变. 这是什么原因? 原因在于: Vue 的响应式系统是基于Object.defineProperty这个方法的,该方法可以监听对象中某个元素的获取或修改,经过了该方法处理的数据,我们称其为响应式数据.但是,该方法有一个很大的缺点,新增属性或者删除属性不会触发监听,举个栗子: var vm = new Vue({ data () { return
-
SpringCloud Netflix Ribbon源码解析(推荐)
SpringCloud Netflix Ribbon源码解析 首先会介绍Ribbon 相关的配置和实例的初始化过程,然后讲解Ribbon 是如何与OpenFeign 集成的,接着讲解负载均衡器LoadBalancerCli ent , 最后依次讲解ILoadB alancer的实现和负载均衡策略Rule 的实现. 配置和实例初始化 @RibbonClient 注解可以声明Ribbon 客户端,设置Ribbon 客户端的名称和配置类,configuration 属性可以指定@Configurati
-
spring获取bean的源码解析
介绍 前面一章说了AbstractApplicationContext中的refresh方法中的invokeBeanFactoryPostProcessors.主要是调用BeanFactoryPostProcessor.其中也有获取bean的过程,就是beanFactory.getBean的方法.这一章就说下getBean这个方法.由于spring中获取bean的方法比较复杂,涉及到的流程也非常多,这一章就先说下整个大体的流程.其中的细节会在后面也会慢慢说. 源码 直接看源码吧 @Overrid
-
Tomcat源码解析之Web请求与处理
前言 Tomcat最全UML类图 Tomcat请求处理过程: Connector对象创建的时候,会创建Http11NioProtocol的ProtocolHandler,在Connector的startInteral方法中,会启动AbstractProtocol,AbstractProtocol启动NioEndPoint进行监听客户端的请求,EndPoint接受到客户端的请求之后,会交给Container去处理请求.请求从Engine开始经过的所有容器都含有责任链模式,每经过一个容器都会调用该容
-
Spring源码解析之Bean的生命周期
一.Bean的实例化概述 前一篇分析了BeanDefinition的封装过程,最终将beanName与BeanDefinition以一对一映射关系放到beanDefinitionMap容器中,这一篇重点分析如何利用bean的定义信息BeanDefinition实例化bean. 二.流程概览 其实bean的实例化过程比较复杂,中间细节很多,为了抓住重点,先将核心流程梳理出来,主要包含以下几个流程: step1: 通过反射创建实例: step2:给实例属性赋初始值: step3:如果Bean类实现B