正则表达式(?=)正向先行断言实战案例
最近在练习正则表达式,遇到了一道很有意思的题,题目如下

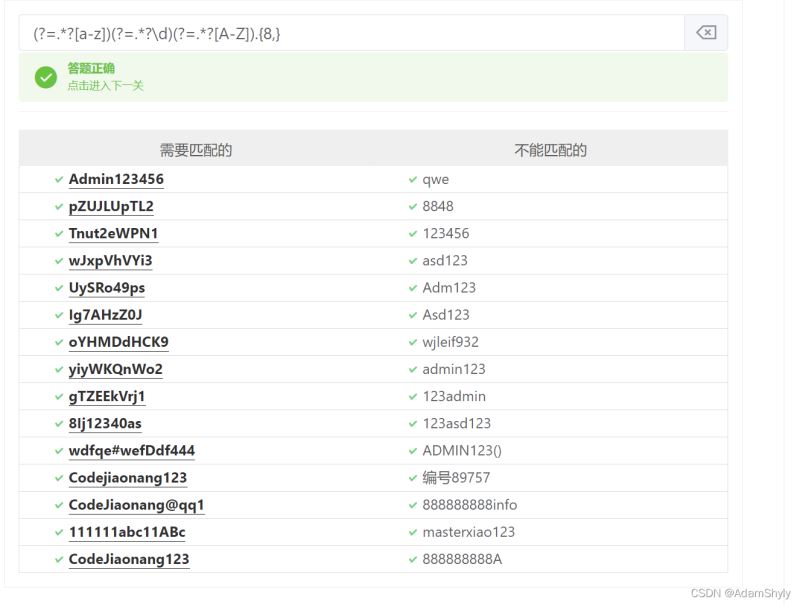
我的答案如下
(?=.*?[A-Z])(?=.*?\d)(?=.*?[a-z]).{8,}
对于这个答案的理解得先从正向先行断言的语法开始说起。
正向先行断言的语法格式如下
expression1(?=expression2) # 查找expression2前面的expression1
当然这个expression1也可以不写(也就是为空白符)
例子如下
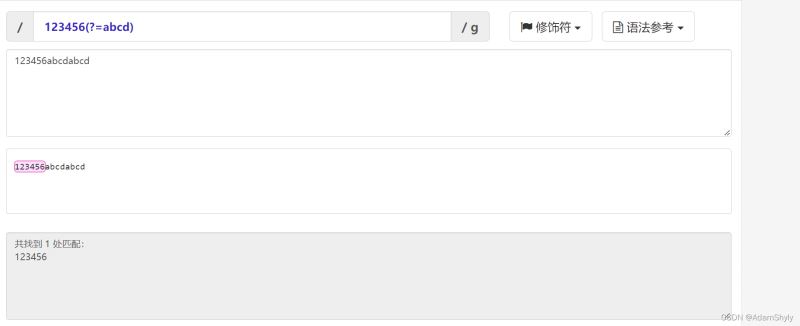
该正则表达式的意思为:寻找abcd字符串前的123456字符串。
这里也提一个有意思的地方
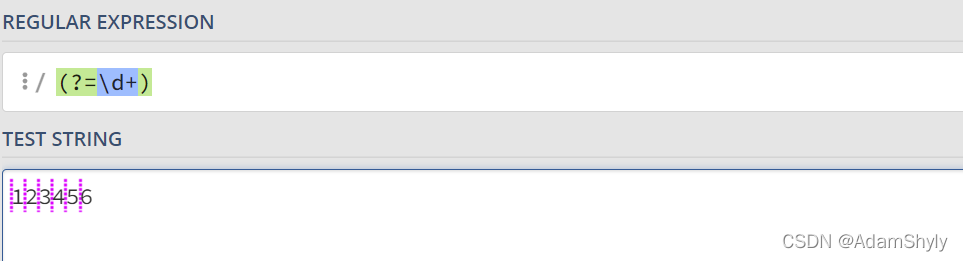
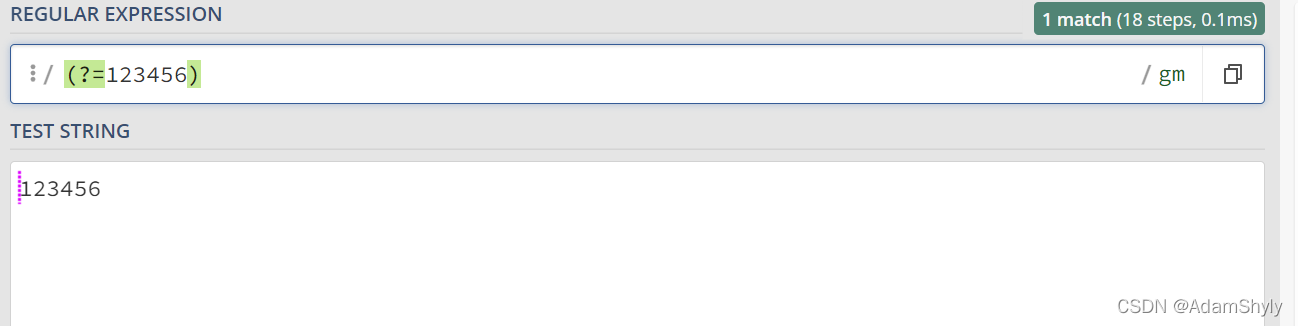
以上两个正则表达式中的/\d+/gm和/123456/gm其实都能匹配123456这个字符串,但在正向先行断言中,前者会匹配每个数字前面的空白符,后者将123456字符串当成一个整体,只匹配这个整体前面的空白符。
这里面的原理还需要等我研究一下,估计是跟底层代码的实现有关,我猜测是(?=\d+)在匹配的时候会将每个数字单独提取出然后向前比较。
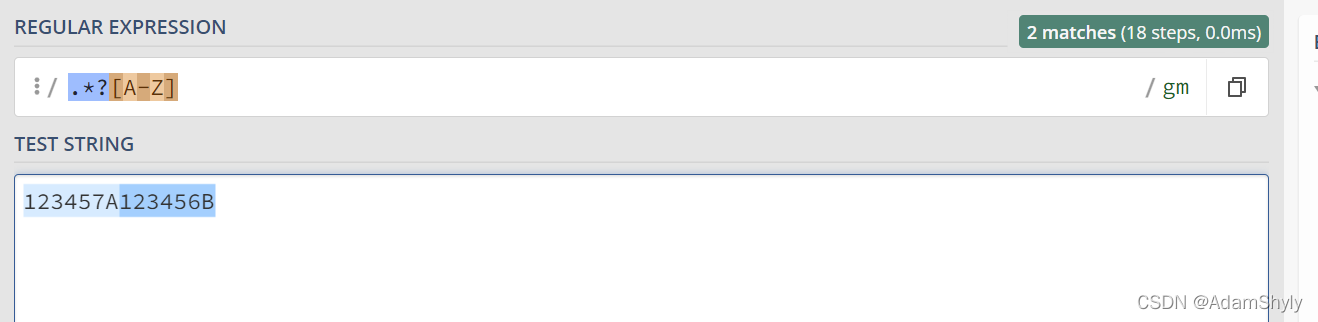
那么回到该题的答案中,先让我们看看 (?=.*?[A-z]) 是什么意思。
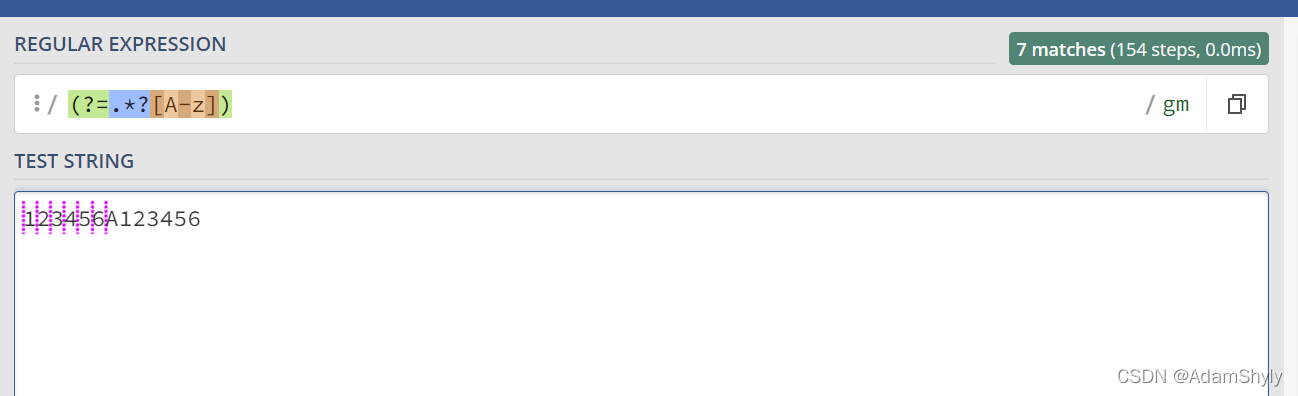
很明显上图匹配了大写字母A前面的所有空白符
其中的.*?[A-Z]代表大写字母及其前面的字符串且为懒惰匹配
那么(?=.*?[A-Z])(?=.*?\d)的意思就有点套娃了,按我的理解就是对于(?=.*?\d)而言把(?=.*?[A-Z])当成expression1,对于(?=.*?[A-Z])而言就是把空白符当成expression1。
那么这个正则表达式就表示为:在寻找到每个大写字母前面的所有空白符的基础上还要满足:这些空白符都在每个数字前面的所有空白符这个匹配集合中。相当于是两个空白符集合的交集。
所以(?=.*?[A-Z])(?=.*?\d)(?=.*?[a-z])相当于是每个大写字母、小写字母、数字前面的所有空白字符的交集。

而后面的.{8,}则匹配这些空白字符后面至少八位字符(贪婪匹配)。
附:先行否定断言
x(?!y)称为先行否定断言(Negative look-ahead),x只有不在y前面才匹配,y不会被计入返回结果。比如,要匹配后面跟的不是百
分号的数字,就要写成/\d+(?!%)/。
/\d+(?!\.)/.exec('3.14') // ["14"]
// ["14"]
上面代码中,正则表达式指定,只有不在小数点前面的数字才会被匹配,因此返回的结果就是14。
“先行否定断言”中,括号里的部分是不会返回的。
var m = 'abd'.match(/b(?!c)/); m // ['b']
上面的代码使用了先行否定断言,b不在c前面所以被匹配,而且括号对应的d不会被返回。
总结
到此这篇关于正则表达式(?=)正向先行断言的文章就介绍到这了,更多相关正则表达式正向先行断言内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

正则表达式断言、巡视(Assertions)、正向断言、反向断言介绍
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置.详细可以看看,正则表达式匹配解析过程探讨分析(正则表达式匹配原理),里面提到"零宽度"很多元字符,只是对特殊位置进行匹配,它们可以理解为断言. 断言元字符 常见断言元字符有: \b, \B, \A, \Z, \z, ^ ,$ 它们只是表示特殊位置,各自作用如有字符串AB,带位置表示为:0A1B2 元字符
-
正则表达式零宽断言详解
正则表达式零宽断言: 零宽断言是正则表达式中的难点,所以本章节重点从匹配原理方面进行一下分析.零宽断言还有其他的名称,例如"环视"或者"预搜索"等等,不过这些都不是我们关注的重点. 一.基本概念: 零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已. 作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功. 注意:这里所说的子表达式并非只有用小括号
-
javascript 正则表达式分组、断言详解
javascript 正则表达式分组.断言详解 提示:阅读本文需要有一定的正则表达式基础. 正则表达式中的断言,作为高级应用出现,倒不是因为它有多难,而是概念比较抽象,不容易理解而已,今天就让小菜通俗的讲解一下. 如果不用断言,以往用过的那些表达式,仅仅能获取到有规律的字符串,而不能获取无规律的字符串. 举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的.因
-
正则表达式(?=)正向先行断言实战案例
最近在练习正则表达式,遇到了一道很有意思的题,题目如下 我的答案如下 (?=.*?[A-Z])(?=.*?\d)(?=.*?[a-z]).{8,} 对于这个答案的理解得先从正向先行断言的语法开始说起. 正向先行断言的语法格式如下 expression1(?=expression2) # 查找expression2前面的expression1 当然这个expression1也可以不写(也就是为空白符) 例子如下 该正则表达式的意思为:寻找abcd字符串前的123456字符串. 这里也提一个有意思的
-
正则表达式从原理到实战全面学习小结
目录 正则是啥? 简单字符 转义字符 字符集和 量词 字符边界 选择表达式 分组与引用 预搜索 修饰符 图形化工具 JavaScript中的正则 RegExp#test RegExp#exec String#search String#match String#split String#replace RegExp 实例属性 实战实例 总结 正则表达式,名字听上去就没有吸引力,我发现很多前端对正则表达式了解不深,甚至有些惧怕,每次能够运行全凭运气,更有甚者完全靠复制粘贴. 正则表达式其实并不难,
-
Swift中闭包实战案例详解
前言 无论苹果的官方文档还是由官方文档衍生出来的一些文章和书籍都比较重视基础语法知识的讲解,对于实战中的应用提及的都很少,所以当我们想使用"闭包"解决一些问题的时候,会忽然出现看着一堆理论知识却不知从何下手的尴尬感,这就是理论和时实战的区别了. 本文不赘述Swift闭包的的基本语法了,百度或者Google下有很多资料.如题所示本文着重讲述Swift闭包的一些实战案例,有需要的小伙伴可以参考下,经验丰富的大神也请指教. 关于如何理解闭包 学习闭包的第一个难点就是理解闭包,可能很多人用了很
-
Linux磁盘分区实战案例(必看篇)
一.查看新添加磁盘 [root@localhost /]# fdisk -l 磁盘 /dev/sda:53.7 GB, 53687091200 字节,104857600 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节 磁盘标签类型:dos 磁盘标识符:0x0009f1d1 设备 Boot Start End Blocks Id System /dev/s
-
Spring Boot连接超时导致502错误的实战案例
1.问题描述 内部系统之间通过Nginx来实现路由转发. 但最近发现有一个系统,经常报502错误,每天达到上百次,完全无法忍受. 2. 原因排查 于是进行排查, 发现配置人员把连接超时时间(server.tomcat.connection-timeout)的单位,理解为秒,实际上是毫秒. SpringBoot的部分配置如下: # Tomcat server: tomcat: uri-encoding: UTF-8 max-threads: 1000 min-spare-threads: 30 c
-
SpringBoot @RequestParam、@PathVaribale、@RequestBody实战案例
实例User package com.iflytek.odeon.shipper.model.rx; import io.swagger.annotations.ApiModelProperty; public class Student { @ApiModelProperty(value = "名称", example = "zhangsan", required = true) private String name; private Integer call;
-
java正则表达式匹配所有数字的案例
用于匹配的正则表达式为 :([1-9]\d*\.?\d*)|(0\.\d*[1-9]) ( [1-9] :匹配1~9的数字: \d :匹配数字,包括0~9: * :紧跟在 \d 之后,表明可以匹配零个及多个数字: \. :匹配小数点: ? :紧跟在 \. 之后,表明可以匹配零个或一个小数点: 0 :匹配一个数字0: ) 其中的 [1-9]\d*\.?\d* 用以匹配诸如:1.23.34.0.56.78 之类的非负的整数和浮点数: 其中的 0\.\d*[1-9] 用以匹配诸如:0.1.0.23.0
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境