Python爬取奶茶店数据分析哪家最好喝以及性价比
目录
- 序篇
- 数据获取
- 数据清洗
- 数据可视化
- 热门城市奶茶店铺数量情况
- 特色奶茶分布情况
- 大众奶茶分布情况
- 总结
序篇
天气真的很热啊… 很想有一杯冰冰凉凉的奶茶来解渴~
但是现在奶茶店这么多, 到底哪一家最好喝、性价比最高呢?
数据获取
本文抓取了12个热门城市的奶茶店名单,
城市包括:北京、上海、广州、深圳、天津、西安、重庆、杭州、南京、武汉、成都和长沙。
共计68614家奶茶店,3万多个奶茶品牌。
在构建抓取URL时,
需要注意将城市的维度具体到城市商圈,
因为每个URL最多只显示32页内容,
保证抓取每个城市时的数据量是准确的。

# 构建抓取URL
def get_url_1():
for city,city_code in city_dict.items():
for block_dict in area_dict[city]:
for children in block_dict['children']:
for page in range(1,33):
block_code = children['id']
offset = 32 * (page-1)
# print(city, area, block, block_code)
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/{}?uuid=6ddabcb37fdd4a8e9cdf.1599125825.1.0.0&userid=280531290&limit=32&offset={}&cateId=-1&q=奶茶果汁&areaId={}&sort=solds'.format(city_code,offset,block_code)
redis_db.sadd('meituan_milk', url)
数据清洗
数据清洗部分,主要清洗了奶茶店铺名称,
但是同一个奶茶品牌会有多种格式,如1点点和1點點,
大卡司和大卡司DAKASI。
由于奶茶品牌数量众多,
并且真假难辨,所以只能进行针对性清洗,
对部分名气高的奶茶品牌名称要保证其统一。
# 清洗字段
def clean(x):
title = re.sub(u"(.*?)", "", x['title'])
title = title.replace('點點','点点').replace('(','').replace(')','')
title = title.replace('一点点','1点点')
if '一杯会说话的茶' in title:
title = '1314一杯会说话的茶'
elif '大卡司' in title:
title = '大卡司DAKASI'
elif '1点点' in title:
title = '1点点'
elif '都可' in title:
title = 'CoCo都可'
elif '书亦烧仙草' in title:
title = '书亦烧仙草'
elif '蜜雪冰城' in title:
title = '蜜雪冰城'
elif 'royal' in title or 'Royal' in title or 'ROYAL' in title:
title = 'Royaltea皇茶'
elif 'ALS' in title:
title = 'ALS GONG CHA贡茶'
elif 'GONG' in title:
title = '贡茶'
elif '茶百道' in title:
title = '茶百道'
elif '吾饮良品' in title:
title = '吾饮良品'
elif '悸动烧仙草' in title:
title = '悸动烧仙草'
elif '沪上阿姨' in title:
title = '沪上阿姨'
elif '7分甜' in title:
title = '7分甜'
elif '古茗' in title:
title = '古茗'
elif '奈雪' in title:
title = '奈雪の茶'
elif '悦色' in title:
title = '茶颜悦色'
else:
pass
return title
df['title'] = df.apply(clean, axis=1)
数据可视化
当小编在制作可视化图表的时候,
会发现有些奶茶品牌的名称极为相似,
让人有一种傻傻分不清楚的感觉。
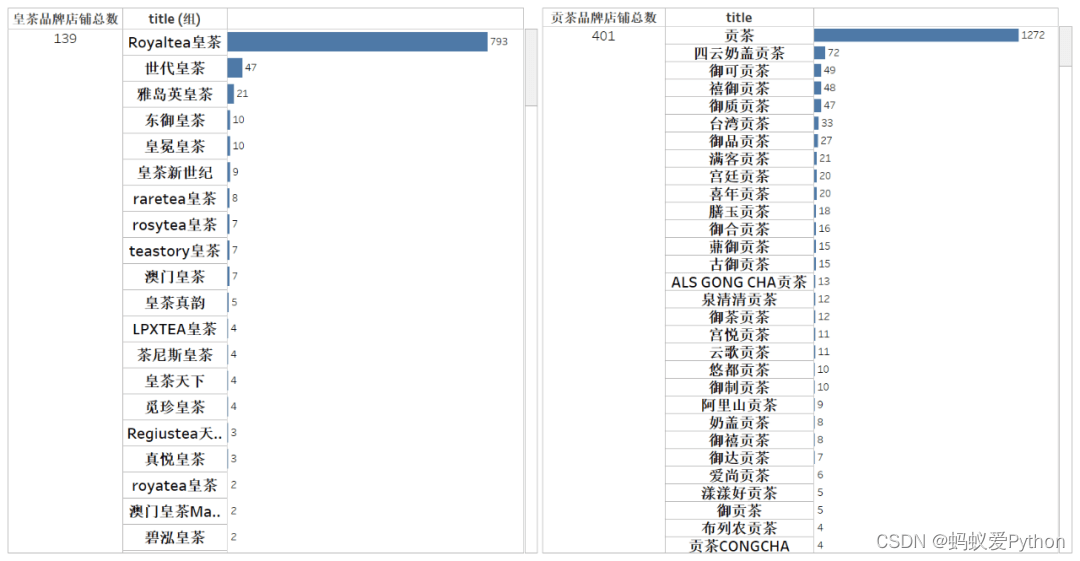
热门城市奶茶店铺数量情况
从全国12个热门城市来看奶茶店铺数量分布情况,
广州的店铺数量是最多的,拥有11419家,
之后是深圳(9367家)、上海(7940家)、成都(7361家)。
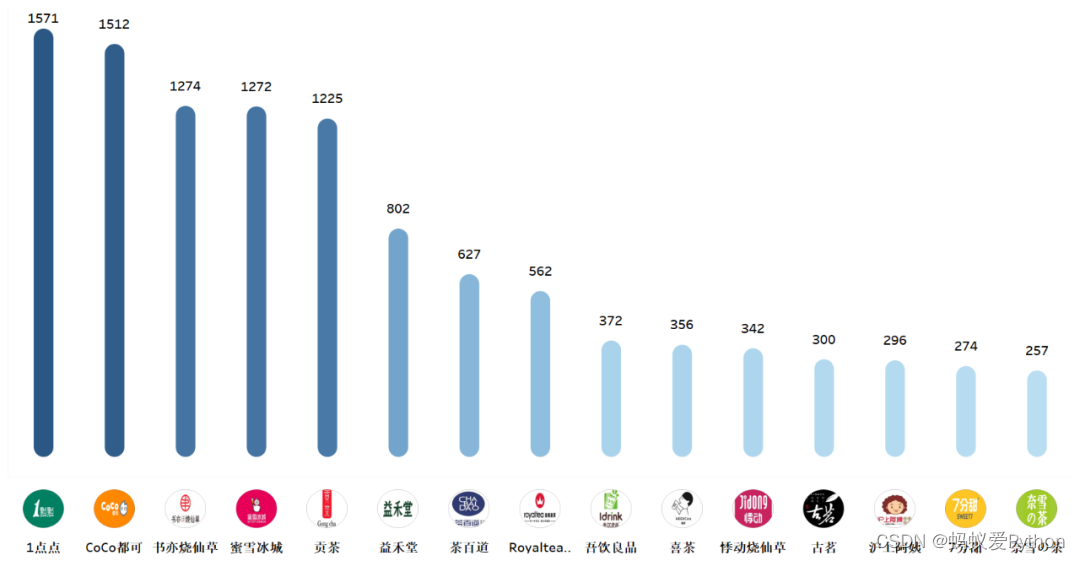
特色奶茶分布情况
有些奶茶店很有自己的地域特色,
如果你想品尝它们的原版奶茶,
就可能需要跑到别的城市才能喝到,
因为它们大部分分店都只开在本土城市。
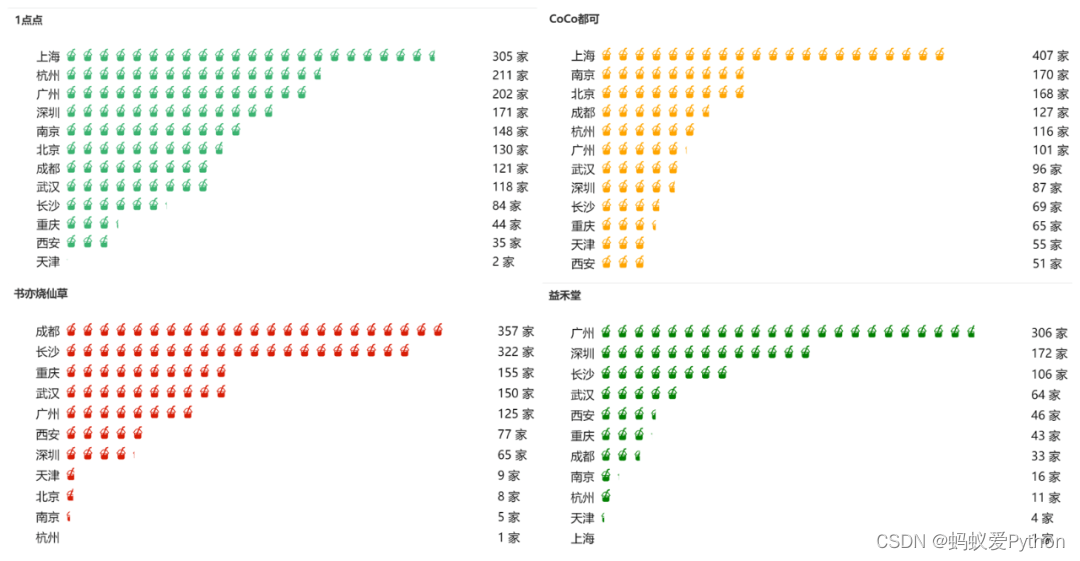
大众奶茶分布情况
接下来介绍一下大众奶茶中的1点点,CoCo,书亦烧仙草和益禾堂的热门城市分布情况,
1点点和CoCo在上海的分店数量都是最多的,而书亦烧仙草在成都和长沙比较普遍,益禾堂则是在广州和深圳。
这4家奶茶品牌在广州分店数量均有上百家,也难怪走到哪都能看到这几家奶茶店。
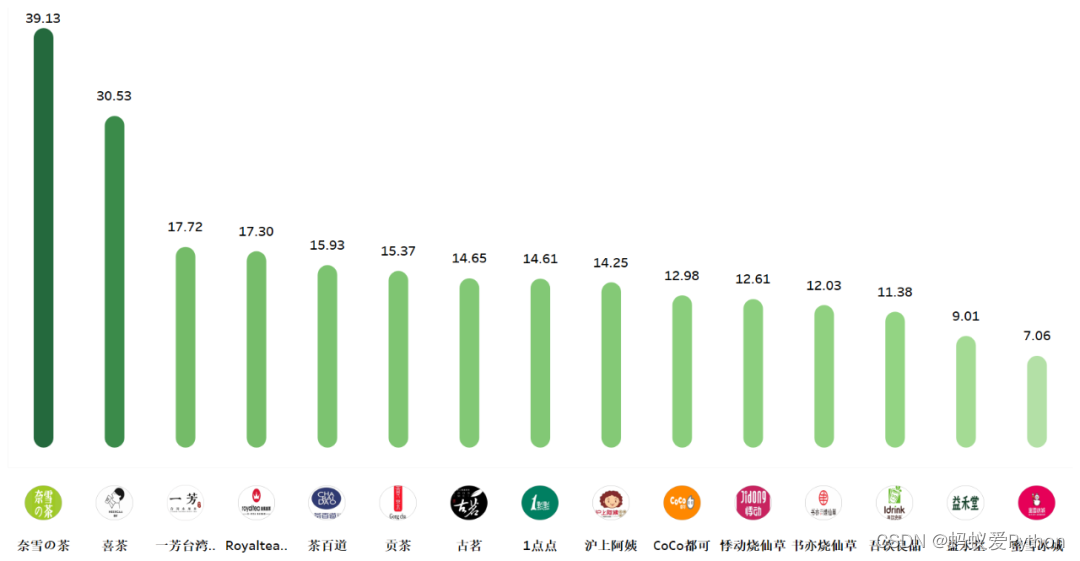
总结
此次小编只分析了12个热门城市的奶茶门店数据,
如果将范围扩展到全国进行分析,
或许能得到更多有意思的结果。
到此这篇关于Python爬取奶茶店数据分析哪家最好喝以及性价比的文章就介绍到这了,更多相关Python爬取奶茶店内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫之代理ip正确使用方法实例
目录 代理ip原理 输入网址后发生了什么呢? 代理ip做了什么呢? 为什么要用代理呢? 爬虫代码中使用代理ip 检验代理ip是否生效 未生效问题排查 1.请求协议不匹配 2.代理失效 总结 主要内容:代理ip使用原理,怎么在自己的爬虫里设置代理ip,怎么知道代理ip是否生效,没生效的话哪里出了问题,个人使用的代理ip(付费). 代理ip原理 输入网址后发生了什么呢? 1.浏览器获取域名 2.通过DNS协议获取域名对应服务器的ip地址 3.浏览器和对应的服务器通过三次握手建立TCP连接 4.浏览器
-
使用python爬虫实现子域名探测问题
目录 前言 一.爬虫 1.ip138 2.bing 二.通过字典进行子域名爆破 三.python爬虫操作步骤 1.写出请求头headers与目标网站url 2.生成请求 3.抓取数据 4.分析源码,截取标签中内容 四.爬虫一些总结 前言 意义:子域名枚举是为一个或多个域查找子域的过程,它是信息收集阶段的重要组成部分.实现方法:使用爬虫与字典爆破. 一.爬虫 1.ip138 def search_2(domain): res_list = [] headers = { 'Accept': '*/*
-
如何实现python爬虫爬取视频时实现实时进度条显示
目录 一.全部代码展示 二.解释 1.with closing with用法(实现上下文管理) closing用法(完美解决上述问题) 2.文件流stream 3.response.headers['content-length'] 4.response.iter_content() 5.\r和% 三.结果展示 四.总结 前言: 在爬取并下载网页上的视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度. 一.全部代码展示 from contextlib import clos
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
python爬虫爬取指定内容的解决方法
目录 解决办法: 实列代码如下:(以我们学校为例) 爬取一些网站下指定的内容,一般来说可以用xpath来直接从网页上来获取,但是当我们获取的内容不唯一的时候我们无法选择,我们所需要的.所指定的内容. 解决办法: 可以使用for In 语句来判断如果我们所指定的内容在这段语句中我们就把这段内容爬取下来,反之就丢弃 实列代码如下:(以我们学校为例) import urllib.request from lxml import etree def creat_url(page): if(page==1
-
盘点Python 爬虫中的常见加密算法
目录 前言 1. 基础常识 2. Base64伪加密 3. MD5加密 4. AES/DES对称加密 1.密钥 2.填充 3.模式 前言 今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征.加密的方式有哪些等等,知道了这些之后对于我们逆向破解这些加密的参数会起到不少的帮助! 相信大家在数据抓取的时候,会碰到很多加密的参数,例如像是"token"."sign"等等,今天小编就带着大家来盘点一下数据抓取过程中这些主流的加密算法,它们有什么特征.
-
Python爬虫实现搭建代理ip池
目录 前言 一.User-Agent 二.发送请求 三.解析数据 四.构建ip代理池,检测ip是否可用 五.完整代码 总结 前言 在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip来继续爬虫测试.下面就开始来简单地介绍一下爬取免费的代理ip来搭建自己的代理ip池: 本次爬取免费ip代理的网址:http://www.ip3366.net/free/ 提示:以下是本篇文章正文内容,下面案例可供参考
-
Python爬取奶茶店数据分析哪家最好喝以及性价比
目录 序篇 数据获取 数据清洗 数据可视化 热门城市奶茶店铺数量情况 特色奶茶分布情况 大众奶茶分布情况 总结 序篇 天气真的很热啊… 很想有一杯冰冰凉凉的奶茶来解渴~ 但是现在奶茶店这么多, 到底哪一家最好喝.性价比最高呢? 数据获取 本文抓取了12个热门城市的奶茶店名单, 城市包括:北京.上海.广州.深圳.天津.西安.重庆.杭州.南京.武汉.成都和长沙. 共计68614家奶茶店,3万多个奶茶品牌. 在构建抓取URL时, 需要注意将城市的维度具体到城市商圈, 因为每个URL最多只显示32页内容
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.
-
Python爬取新型冠状病毒“谣言”新闻进行数据分析
一.爬取数据 话不多说了,直接上代码( copy即可用 ) import requests import pandas as pd class SpiderRumor(object): def __init__(self): self.url = "https://vp.fact.qq.com/loadmore?artnum=0&page=%s" self.header = { "User-Agent": "Mozilla/5.0 (iPhone;
-
python爬取全国火锅店数量并可视化展示
目录 一.网页分析 二.获取数据 1.导入相关库 2.请求数据 3.保存到excel 三.数据可视化 1.全国火锅店数量分布 2.四川火锅店数量分布 四.小结 前言: 今天教大家如何获取全国不同城市火锅店数量情况,并将这些数据进行可视化展示,以更加直观的方式去浏览全国不同省份.不同城市的火锅店分布情况. 本文数据来自于某度地图,通过python技术知识去获取数据并进行可视化. 一.网页分析 首先先看一下数据源,在某度地图里面按照下方操作,就可以请求到全国的火锅店情况(从下图来看没有显示出来,但是
-
Python爬取附近餐馆信息代码示例
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): # 模拟使用浏览器浏览大众点评的方式浏览大众点评 headers = {'User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} ope
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
python爬取天气数据的实例详解
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了.之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观.那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢? 使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal bar = pygal.Line() # 创建折线图 bar.add('最低气温', lows) #添加两线的数据序列 b