Kubernetes上使用Jaeger分布式追踪基础设施详解
目录
- 正文
- 微服务架构中的可观察性
- 分布式追踪
- Jaeger组件
- 架构图
- Jaeger客户端
- Jaeger代理
- Jaeger SideCar 代理
- Jaeger Daemonset 代理
- Jaeger Collector 服务
- Jaeger Query 查询服务
- Storage Configuration 存储配置
- 监控
正文
作为分布式系统(或任何系统)的一个组成部分,监测基础设施的重要性怎么强调都不过分。监控不仅要跟踪二进制的 "上升 "和 "下降 "模式,还要参与到复杂的系统行为中。监测基础设施的设置可以让人们深入了解性能、系统健康和长期的行为模式。
这篇文章介绍了监控基础设施的一个方面--分布式跟踪。
微服务架构中的可观察性
Kubernetes已经成为微服务基础设施和部署的事实上的协调器。这个生态系统非常丰富,是开源社区中发展最快的系统之一。带有Prometheus、ElasticSearch、Grafana、Envoy/Consul、Jaeger/Zipkin的监控基础设施构成了一个坚实的基础,以实现整个堆栈的指标、日志、仪表盘、服务发现和分布式跟踪。
分布式追踪
分布式跟踪能够捕获请求,并建立一个从用户请求到数百个服务之间互动的整个调用链的视图。它还能对应用程序的延迟(每个请求花了多长时间)进行检测,跟踪网络调用的生命周期(HTTP、RPC等),并通过获得瓶颈的可见性来确定性能问题。
下面的章节将介绍在Kubernetes设置中使用Jaeger对gRPC服务进行分布式跟踪。Jaeger Github Org有专门的Repo,用于Kubernetes中Jaeger的各种部署配置。这些都是很好的例子,我将尝试分解每个Jaeger组件和它的Kubernetes部署。
Jaeger组件
Jaeger是一个开源的分布式跟踪系统,实现了OpenTracing规范。Jaeger包括存储、可视化和过滤跟踪的组件。
架构图
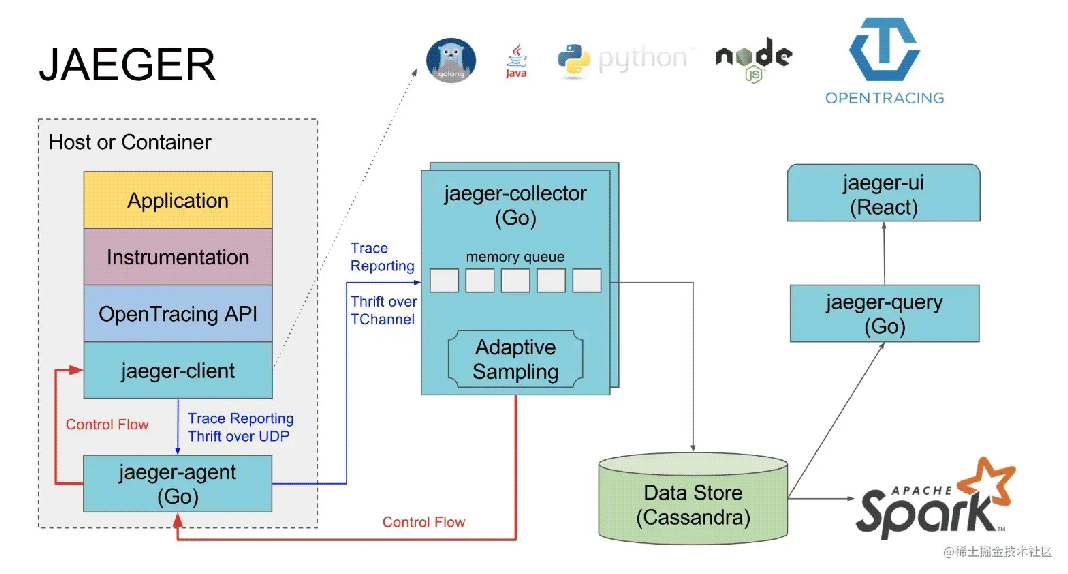
Jaeger客户端
应用程序跟踪仪表从Jaeger客户端开始。下面的例子使用Jaeger Go库从环境变量初始化追 踪 器配置,并启用客户端指标。
package tracer
import (
"io"
"github.com/uber/jaeger-client-go/config"
jprom "github.com/uber/jaeger-lib/metrics/prometheus"
)
func NewTracer() (opentracing.Tracer, io.Closer, error) {
// load config from environment variables
cfg, _ := jaegercfg.FromEnv()
// 博客原来:janrs.com
// create tracer from config
return cfg.NewTracer(
config.Metrics(jprom.New()),
)
}
Go客户端使通过环境变量初始化Jaeger配置变得简单。一些需要设置的重要环境变量包括JAEGER_SERVICE_NAME、JAEGER_AGENT_HOST和JAEGER_AGENT_PORT。Jaeger Go客户端支持的环境变量的完整列表列在这里。
为了给你的gRPC微服务添加追踪功能,我们将使用gRPC中间件来启用gRPC服务器和客户端的追踪功能。 grpc-ecosystem/go-grpc-middleware有一个很棒的拦截器集合,包括支持OpenTracing提供者的服务器端和客户端的拦截器。
grpc_opentracing包暴露了opentracing拦截器,可以用任何opentracing.Tracer实现来初始化。在这里,我们用连锁的单项和流拦截器初始化了一个gRPC服务器。启用它将创建一个根serverSpan,对于每个服务器端的gRPC请求,追 踪 器将为服务中定义的每个RPC调用附加一个Span。
package grpc_server
import (
"github.com/opentracing/opentracing-go"
"github.com/grpc-ecosystem/go-grpc-middleware/tracing/opentracing"
"github.com/grpc-ecosystem/go-grpc-middleware"
"google.golang.org/grpc"
"github.com/masroorhasan/myapp/tracer"
)
func NewServer() (*grpc.Server, error) {
// initialize tracer
tracer, closer, err := tracer.NewTracer()
defer closer.Close()
if err != nil {
return &grpc.Server{}, err
}
opentracing.SetGlobalTracer(tracer)
// initialize grpc server with chained interceptors # janrs.com
s := grpc.NewServer(
grpc.StreamInterceptor(grpc_middleware.ChainStreamServer(
// add opentracing stream interceptor to chain
grpc_opentracing.StreamServerInterceptor(grpc_opentracing.WithTracer(tracer)),
)),
grpc.UnaryInterceptor(grpc_middleware.ChainUnaryServer(
// add opentracing unary interceptor to chain
grpc_opentracing.UnaryServerInterceptor(grpc_opentracing.WithTracer(tracer)),
)),
)
return s, nil
}
为了实现对gRPC服务的上游和下游请求的追踪,gRPC客户端也必须用客户端开放追踪拦截器进行初始化,如下例所示。
package grpc_client
import (
"github.com/opentracing/opentracing-go"
"github.com/grpc-ecosystem/go-grpc-middleware/tracing/opentracing"
"github.com/grpc-ecosystem/go-grpc-middleware"
"google.golang.org/grpc"
"github.com/masroorhasan/myapp/tracer"
)
func NewClientConn(address string) (*grpc.ClientConn, error) {
// initialize tracer #博文来源:janrs.com
tracer, closer, err := tracer.NewTracer()
defer closer.Close()
if err != nil {
return &grpc.ClientConn{}, err
}
// initialize client with tracing interceptor [#博文来源:janrs.com#] using grpc client side chaining
return grpc.Dial(
address,
grpc.WithStreamInterceptor(grpc_middleware.ChainStreamClient(
grpc_opentracing.StreamClientInterceptor(grpc_opentracing.WithTracer(tracer)),
)),
grpc.WithUnaryInterceptor(grpc_middleware.ChainUnaryClient(
grpc_opentracing.UnaryClientInterceptor(grpc_opentracing.WithTracer(tracer)),
)),
)
}
由gRPC中间件创建的父跨度被注入到go上下文中,从而实现强大的跟踪支持。opentracing go客户端可以用来将子跨度附加到父跨度上,以实现更精细的追踪,以及控制每个跨度的寿命,为追踪添加自定义标签等。
Jaeger代理
Jaeger代理是一个守护进程,它通过UDP接收来自Jaeger客户端的跨度,并将它们分批转发给收集器。该代理作为一个缓冲器,从客户那里抽象出批处理和路由。
尽管代理是作为一个守护程序建立的,但在Kubernetes设置中,代理可以被配置为在应用Pod中作为一个sidecar容器运行,或作为一个独立的DaemonSet。
下文讨论了每种部署策略的优点和缺点。
Jaeger SideCar 代理
Jaeger Sidecar 代理是一个容器,与你的应用容器放在同一个舱中。表示为Jaeger服务的应用程序myapp将通过localhost向代理发送Jaeger跨度到6381端口。[#博文来源:janrs.com#]如前所述,这些配置是通过客户端的环境变量JAEGER_SERVICE_NAME、JAEGER_AGENT_HOST和JAEGER_AGENT_PORT设置的。
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
namespace: default
labels:
app: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: masroorhasan/myapp
ports:
- containerPort: 80
env:
- name: JAEGER_SERVICE_NAME
value: myapp
- name: JAEGER_AGENT_HOST
value: localhost # default
- name: JAEGER_AGENT_PORT
value: "6831"
resources:
limits:
memory: 500M
cpu: 250m
requests:
memory: 500M
cpu: 250m
# sidecar agent
- name: jaeger-agent
image: jaegertracing/jaeger-agent:1.6.0
ports:
- containerPort: 5775
protocol: UDP
- containerPort: 5778
protocol: TCP
- containerPort: 6831
protocol: UDP
- containerPort: 6832
protocol: UDP
command:
- "/go/bin/agent-linux"
- "--collector.host-port=jaeger-collector.monitoring:14267"
resources:
limits:
memory: 50M
cpu: 100m
requests:
memory: 50M
cpu: 100m
通过这种方法,每个代理(也就是每个应用)都可以被配置为向不同的收集器(也就是不同的后端存储)发送痕迹。
然而,这种方法最大的缺点之一是将代理的生命周期和应用程序紧密结合在一起。追踪的目的是在应用程序的生命周期内提供对其的洞察力。更有可能的是,代理侧车容器在主应用容器之前被杀死,在应用服务关闭期间,任何/所有重要的追踪都会丢失。这些痕迹的丢失对于理解复杂服务交互的应用生命周期行为可能是非常重要的。这个GitHub问题验证了在关机期间正确处理SIGTERM的必要性。
Jaeger Daemonset 代理
另一种方法是通过Kubernetes中的DaemonSet工作负载,将代理作为集群中每个节点的守护程序运行。DaemonSet工作负载可以确保当节点被扩展时,DaemonSet Pod的副本也随之扩展。
在这种情况下,每个代理守护程序负责从其节点中安排的所有运行中的应用程序(配置了Jaeger客户端)中获取追踪信息。这是通过在客户端设置JAEGER_AGENT_HOST指向节点中代理的IP来配置的。代理DaemonSet被配置为hostNetwork: true和适当的DNS策略,以便Pod使用与主机相同的IP。由于代理的6831端口是通过UDP接受jaeger.thrift消息的,所以守护的Pod配置端口也与hostPort: 6831绑定。
# Auth : janrs.com
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
namespace: default
labels:
app: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: masroorhasan/myapp
ports:
- containerPort: 80
env:
- name: JAEGER_SERVICE_NAME
value: myapp
- name: JAEGER_AGENT_HOST # NOTE: Point to the Agent daemon on the Node
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: JAEGER_AGENT_PORT
value: "6831"
resources:
limits:
memory: 500M
cpu: 250m
requests:
memory: 500M
cpu: 250m
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: jaeger-agent
namespace: monitoring
labels:
app: jaeger
jaeger-infra: agent-daemonset
spec:
template:
metadata:
labels:
app: jaeger
jaeger-infra: agent-instance
spec:
hostNetwork: true # NOTE: Agent is configured to have same IP as the host/node
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: agent-instance
image: jaegertracing/jaeger-agent:1.6.0
command:
- "/go/bin/agent-linux"
- "--collector.host-port=jaeger-collector.monitoring:14267"
- "--processor.jaeger-binary.server-queue-size=2000"
- "--discovery.conn-check-timeout=500ms"
ports:
- containerPort: 5775
protocol: UDP
- containerPort: 6831
protocol: UDP
hostPort: 6831
- containerPort: 6832
protocol: UDP
- containerPort: 5778
protocol: TCP
resources:
requests:
memory: 200M
cpu: 200m
limits:
memory: 200M
cpu: 200m
人们可能会被诱 惑(就像我一样),用Kubernetes服务来引导DaemonSet。这背后的想法是,不要把应用程序的痕迹绑定到当前节点的单一代理上。使用服务可以将工作负载(跨度)分散到集群中的所有代理。这在理论上减少了在受影响节点的单个代理荚发生故障的情况下,应用实例丢失跨度的机会。
然而,当你的应用程序扩展时,这将不起作用,高负载会在需要处理的痕迹数量上产生巨大的峰值。使用Kubernetes服务意味着通过网络从客户端向代理发送追踪信息。很快,我就开始注意到大量的掉线现象。客户端通过UDP thrift协议向代理发送跨度,大量的峰值导致超过UDP最大数据包大小,从而导致丢包。
解决办法是适当地分配资源,使Kubernetes在整个集群中更均匀地调度pod。[#博文来源:janrs.com#]我们可以增加客户端的队列大小(设置JAEGER_REPORTER_MAX_QUEUE_SIZE环境变量),以便在代理失效时有足够的缓冲空间。增加代理的内部队列大小也是有益的(设置处理器.jaeger-binary.server-queue-size值),这样他们就不太可能开始丢弃跨度。
Jaeger Collector 服务
Jaeger收集器负责从Jaeger代理那里接收成批的跨度,通过处理管道运行它们,并将它们存储在指定的存储后端。跨度以jaeger.thrift格式从Jaeger代理处通过TChannel(TCP)协议发送,端口为14267。
Jaeger收集器是无状态的,可以根据需要扩展到任何数量的实例。因此,收集器可以由Kubernetes内部服务(ClusterIP)前置,可以从代理到不同收集器实例的内部流量进行负载平衡。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: jaeger-collector
namespace: monitoring
labels:
app: jaeger
jaeger-infra: collector-deployment
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: jaeger
jaeger-infra: collector-pod
spec:
containers:
- image: jaegertracing/jaeger-collector:1.6.0
name: jaeger-collector
args: ["--config-file=/conf/collector.yaml"]
ports:
- containerPort: 14267
protocol: TCP
- containerPort: 14268
protocol: TCP
- containerPort: 9411
protocol: TCP
readinessProbe:
httpGet:
path: "/"
port: 14269
volumeMounts:
- name: jaeger-configuration-volume
mountPath: /conf
env:
- name: SPAN_STORAGE_TYPE
valueFrom:
configMapKeyRef:
name: jaeger-configuration
key: span-storage-type
volumes:
- configMap:
name: jaeger-configuration
items:
- key: collector
path: collector.yaml
name: jaeger-configuration-volume
resources:
requests:
memory: 300M
cpu: 250m
limits:
memory: 300M
cpu: 250m
---
apiVersion: v1
kind: Service
metadata:
name: jaeger-collector
namespace: monitoring
labels:
app: jaeger
jaeger-infra: collector-service
spec:
ports:
- name: jaeger-collector-tchannel
port: 14267
protocol: TCP
targetPort: 14267
selector:
jaeger-infra: collector-pod
type: ClusterIP
view raw
Jaeger Query 查询服务
查询服务是支持用户界面的Jaeger服务器。它负责从存储器中检索痕迹,并将其格式化以显示在用户界面上。根据查询服务的使用情况,它的资源占用率非常小。
设置一个内部Jaeger用户界面的入口,指向后端查询服务。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: jaeger-query
namespace: monitoring
labels:
app: jaeger
jaeger-infra: query-deployment
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: jaeger
jaeger-infra: query-pod
spec:
containers:
- image: jaegertracing/jaeger-query:1.6.0
name: jaeger-query
args: ["--config-file=/conf/query.yaml"]
ports:
- containerPort: 16686
protocol: TCP
readinessProbe:
httpGet:
path: "/"
port: 16687
volumeMounts:
- name: jaeger-configuration-volume
mountPath: /conf
env:
- name: SPAN_STORAGE_TYPE
valueFrom:
configMapKeyRef:
name: jaeger-configuration
key: span-storage-type
resources:
requests:
memory: 100M
cpu: 100m
limits:
memory: 100M
cpu: 100m
volumes:
- configMap:
name: jaeger-configuration
items:
- key: query
path: query.yaml
name: jaeger-configuration-volume
---
apiVersion: v1
kind: Service
metadata:
name: jaeger-query
namespace: monitoring
labels:
app: jaeger
jaeger-infra: query-service
spec:
ports:
- name: jaeger-query
port: 16686
targetPort: 16686
selector:
jaeger-infra: query-pod
type: ClusterIP
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: jaeger-ui
namespace: monitoring
annotations:
kubernetes.io/ingress.class: traefik # or nginx or whatever ingress controller
spec:
rules:
- host: jaeger.internal-host # your jaeger internal endpoint
http:
paths:
- backend:
serviceName: jaeger-query
servicePort: 16686
Storage Configuration 存储配置
Jaeger同时支持ElasticSearch和Cassandra作为存储后端。使用ElasticSearch作为存储,可以拥有一个强大的监控基础设施,将跟踪和日志记录联系在一起。采集器处理管道的一部分是为其存储后端索引跟踪--这将使跟踪显示在你的日志UI(例如Kibana)中,也将跟踪ID与你的结构化日志标签绑定。你可以通过SPAN_STORAGE_TYPE的环境变量将存储类型设置为ElasticSearch,并通过配置配置存储端点。
Kubernetes ConfigMap用于设置一些Jaeger组件的存储配置。例如,Jaeger收集器和查询服务的存储后端类型和端点。
apiVersion: v1
kind: ConfigMap
metadata:
name: jaeger-configuration
namespace: monitoring
labels:
app: jaeger
jaeger-infra: configuration
data:
span-storage-type: elasticsearch
collector: |
es:
server-urls: http://elasticsearch:9200
collector:
zipkin:
http-port: 9411
query: |
es:
server-urls: http://elasticsearch:9200
监控
如前所述,追踪是监控基础设施的一个重要组成部分。这意味着,甚至你的追踪基础设施的组件也需要被监控。
Jaeger在每个组件的特定端口上以Prometheus格式暴露指标。如果有正在运行的Prometheus节点导出器(它绝对应该是)在特定的端口上刮取指标 - 然后将你的Jaeger组件的指标端口映射到节点导出器正在刮取指标的端口。
这可以通过更新Jaeger服务(代理、收集器、查询)来完成,将它们的指标端口(5778、14628或16686)映射到节点出口商期望搜刮指标的端口(例如8888/8080)。
一些需要跟踪的重要指标。
Health of each component — memory usage: sum(rate(container_memory_usage_bytes{container_name=~”^jaeger-.+”}[1m])) by (pod_name)
Health of each component — CPU usage: sum(rate(container_cpu_usage_seconds_total{container_name=~"^jaeger-.+"}[1m])) by (pod_name)
Batch failures by Jaeger Agent: sum(rate(jaeger_agent_tc_reporter_jaeger_batches_failures[1m])) by (pod)
Spans dropped by Collector: sum(rate(jaeger_collector_spans_dropped[1m])) by (pod)
Queue latency (p95) of Collector: histogram_quantile(0.95, sum(rate(jaeger_collector_in_queue_latency_bucket[1m])) by (le, pod))
这些指标为了解每个组件的性能提供了重要的见解,历史数据应被用来进行最佳设置。
以上就是Kubernetes上使用Jaeger分布式追踪基础设施详解的详细内容,更多关于Kubernetes Jaeger分布式追踪的资料请关注我们其它相关文章!
相关推荐
-
一文详解基于Kubescape进行Kubernetes安全加固
目录 正文 Kubernetes 加固概述 通用性的安全建议 Kubescape 概述 Kubescape 基本原理 Kubescape 安装部署 Linux 安装 Kubescape macOS 安装 Kubescape Kubescape 实践 扫描结果分析 常用扫描技巧 正文 Hello folks! 今天我们介绍一款开源容器平台安全扫描工具 - Kubescape.作为第一个用于测试 Kubernetes 集群是否遵循 NSA-CISA 和 MITREATT&CK 等多个框架安全部署规范
-
kubernetes数据持久化StorageClass动态供给实现详解
目录 正文 基于NFS实现动态供应 准备NFS服务端的共享目录 安装NFS-Server驱动. 部署NFS-Provisioner 创建StorageClass 创建PVC,自动关联PV 创建Pod,测试数据是否持久. 正文 存储类的好处之一便是支持PV的动态供给,它甚至可以直接被视作为PV的创建模版,用户用到持久性存储时,需要通过创建PVC来绑定匹配的PV,此类操作需求较大,或者当管理员手动创建的PV无法满足PVC的所有需求时,系统按PVC的需求标准动态创建适配的PV会为存储管理带来极大的灵活
-
Kubernetes controller manager运行机制源码解析
目录 Run StartControllers ReplicaSet ReplicaSetController syncReplicaSet Summary Run 确立目标 理解 kube-controller-manager 的运行机制 从主函数找到run函数,代码较长,这里精简了一下 func Run(c *config.CompletedConfig, stopCh <-chan struct{}) error { // configz 模块,在kube-scheduler分析中已经了解
-
kubernetes数据持久化PV PVC深入分析详解
目录 1. 什么是PV,PVC? 1.1 什么是PV 1.2 什么是PVC? 2. PV资源实践 2.1 PV配置字段详解 2.2 HostPath PV示例 2.3 NFS PV示例 3. PVC资源实践 3.1 PVC配置清单详解 3.2 hostPath-PVC示例 3.3 NFS-PV-PVC实践之准备NFS共享存储 3.4 准备NFS-PVC 3.4.1准备Pod并使用PVC 3.4.2 测试数据持久性 1. 什么是PV,PVC? 1.1 什么是PV 官方文档地址: https://k
-
IoT 边缘集群Kubernetes Events告警通知进一步配置详解
目录 目标 配置 告警内容显示资源名称 屏蔽特定的节点和工作负载 最终效果 目标 上一篇文章 IoT 边缘集群基于 Kubernetes Events 的告警通知实现 告警恢复通知 - 经过评估无法实现 原因: 告警和恢复是单独完全不相关的事件, 告警是 Warning 级别, 恢复是 Normal 级别, 要开启恢复, 就会导致所有 Normal Events 都会被发送, 这个数量是很恐怖的; 而且, 除非特别有经验和耐心, 否则无法看出哪条 Normal 对应的是 告警的恢复. 未恢复进行
-
Kubernetes上使用Jaeger分布式追踪基础设施详解
目录 正文 微服务架构中的可观察性 分布式追踪 Jaeger组件 架构图 Jaeger客户端 Jaeger代理 Jaeger SideCar 代理 Jaeger Daemonset 代理 Jaeger Collector 服务 Jaeger Query 查询服务 Storage Configuration 存储配置 监控 正文 作为分布式系统(或任何系统)的一个组成部分,监测基础设施的重要性怎么强调都不过分.监控不仅要跟踪二进制的 "上升 "和 "下降 "模式,还要
-
分布式Hibernate search详解
分布式Hibernate Search与Apache Tomcat6,ActiveMQ 和Spring.今天我将跟大家分享我的经验,以master/slave(s)方式配置分布式Hibernate Search并整合Apache ActiveMQ,Spring,应用程序额容器是Apache Tomcat 6. 怎么工作: -Hibernate Search 支持使用JMS back-end 和 master/slave(s) 索引进行分布式配置 - mater通过网络共享暴露索引 (例如通过NF
-
python从内存地址上加载python对象过程详解
这篇文章主要介绍了python从内存地址上加载pythn对象过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在python中我们可以通过id函数来获取某个python对象的内存地址,或者可以通过调用对象的__repr__魔术函数来获取对象的详细信息 def tt(): print(111) print(tt.__repr__()) print(id(tt)) 但是不知大家是否想过,其实这个内存地址可以直接加载python对象的.有两种方
-
php基于redis的分布式锁实例详解
在使用分布式锁进行互斥资源访问时候,我们很多方案是采用redis的实现. 固然,redis的单节点锁在极端情况也是有问题的,假设你的业务允许偶尔的失效,使用单节点的redis锁方案就足够了,简单而且效率高. redis锁失效的情况: 客户端1从master节点获取了锁 master宕机了,存储锁的key还没来得及同步到slave节点上 slave升级为master 客户端2从新的master上获取到同一个资源的锁 于是,客户端1和客户端2同事持有了同一个资源的锁,锁的安全性被打破. 如果我们不考
-
TypeScript前端上传文件到MinIO示例详解
目录 什么是MinIO? 本地Docker部署测试服务器 上传的API TypeScript实现 1. XMLHttpRequest 2. Fetch API 3. Axios 从后端获取临时上传链接 上传文件 踩过的坑 1. presignedPutObject方式上传提交的方法必须得是PUT 2. 直接发送File即可 3. 使用Axios上传的时候,需要自己把Content-Type填写成为file.type 示例代码 什么是MinIO? MinIO 是一款高性能.分布式的对象存储系统.
-
Kubernetes集群模拟删除k8s重装详解
目录 一.系统环境 二.前言 三.重装Kubernetes集群 3.1 环境介绍 3.2 删除k8s所有节点(node) 3.3 kubeadm初始化 3.4 添加worker节点到k8s集群 3.5 安装calico 一.系统环境 服务器版本 docker软件版本 CPU架构 CentOS Linux release 7.4.1708 (Core) Docker version 20.10.12 x86_64 二.前言 当我们安装部署好一套Kubernetes集群,使用一段时间之后可能会有重新
-
mui上拉加载功能实例详解
最近在做移动端的项目,用到了mui的上拉加载,整理如下: 1.需要引入的css.js <link rel="stylesheet" href="common/mui/css/mui.min.css" rel="external nofollow" > <script src="js/jquery-3.2.0.min.js"></script> <script src="com
-
Linux上的文件搜索命令实例详解
locate 基础了解 在centos7上默认没有locate命令,需要先手动安装.安装步骤:http://www.cnblogs.com/feanmy/p/7676717.html locate命令搜索的后台数据库路径:/var/lib/mlocate/mlocate.db ls -hl /var/lib/mlocate total 1.2M -rw-r----- 1 root slocate 1.2M Oct 16 14:36 mlocate.db 更新数据库使用updatedb,配置文件为
-
ThinkPHP 在阿里云上的nginx.config配置实例详解
具体代码如下所示: # For more information on configuration, see: # * Official English Documentation: http://nginx.org/en/docs/ # * Official Russian Documentation: http://nginx.org/ru/docs/ user nginx; worker_processes auto; error_log /var/log/nginx/error.log;
-

Android开发之机顶盒上gridview和ScrollView的使用详解
最近在机顶盒上做一个gridview, 其焦点需要在item的子控件上,但gridview的焦点默认在item上,通过 android:descendantFocusability="afterDescendants" <ScrollView android:id="@+id/scroll_content" android:layout_width="1740.0px" android:layout_height="600.0px