pytorch + visdom 处理简单分类问题的示例
环境
系统 : win 10
显卡:gtx965m
cpu :i7-6700HQ
python 3.61
pytorch 0.3
包引用
import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim
数据准备
use_gpu = True ones = np.ones((500,2)) x1 = torch.normal(6*torch.from_numpy(ones),2) y1 = torch.zeros(500) x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2) y2 = y1 +1 x3 = torch.normal(-6*torch.from_numpy(ones),2) y3 = y1 +2 x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2) y4 = y1 +3 x = torch.cat((x1, x2, x3 ,x4), 0).float() y = torch.cat((y1, y2, y3, y4), ).long()
可视化如下看一下:
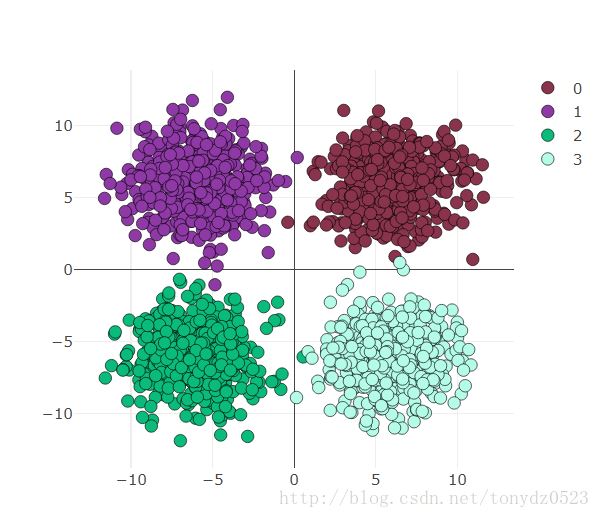
visdom可视化准备
先建立需要观察的windows
viz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)
效果如下:
逻辑回归处理
输入2,输出4
logstic = nn.Sequential( nn.Linear(2,4) )
gpu还是cpu选择:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")
优化器和loss函数:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
训练2000次:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()
训练过成观察及可视化:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
.format(accuracy,loss.data[0],time.time()-start_time),win =text)
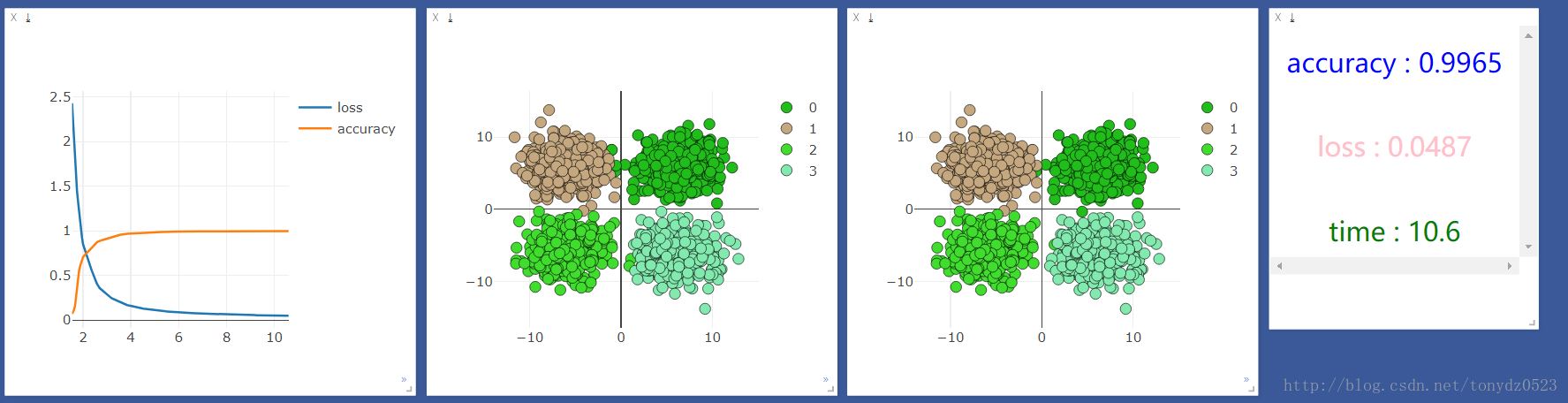
我们先用cpu运行一次,结果如下:
然后用gpu运行一下,结果如下:
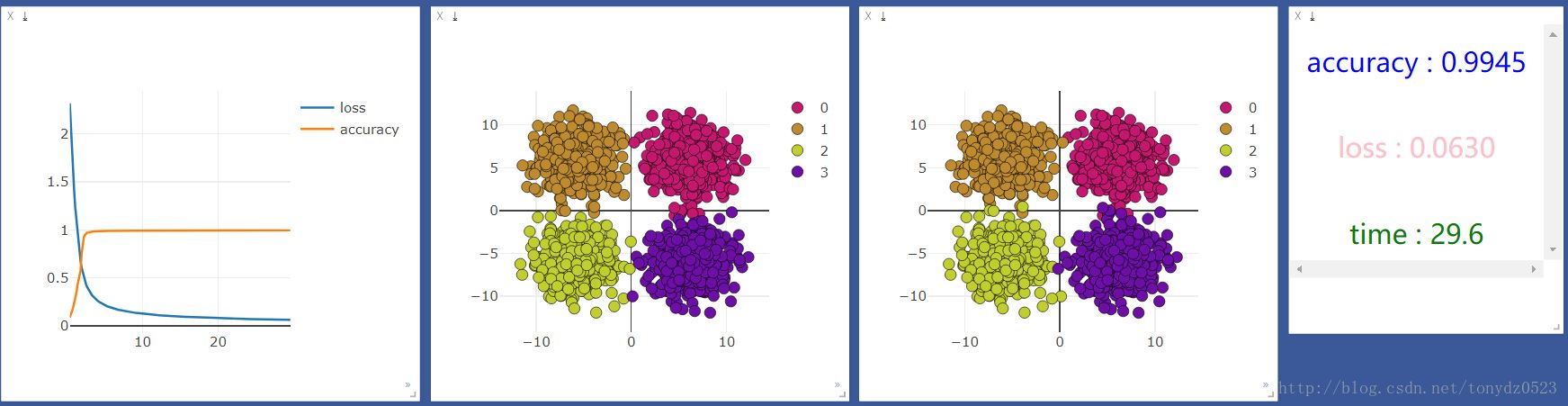
发现cpu的速度比gpu快很多,但是我听说机器学习应该是gpu更快啊,百度了一下,知乎上的答案是:

我的理解就是gpu在处理图片识别大量矩阵运算等方面运算能力远高于cpu,在处理一些输入和输出都很少的,还是cpu更具优势。
添加神经层:
net = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), #激活函数 nn.Linear(10, 4) )
添加一层10单元神经层,看看效果是否会有所提升:
使用cpu:
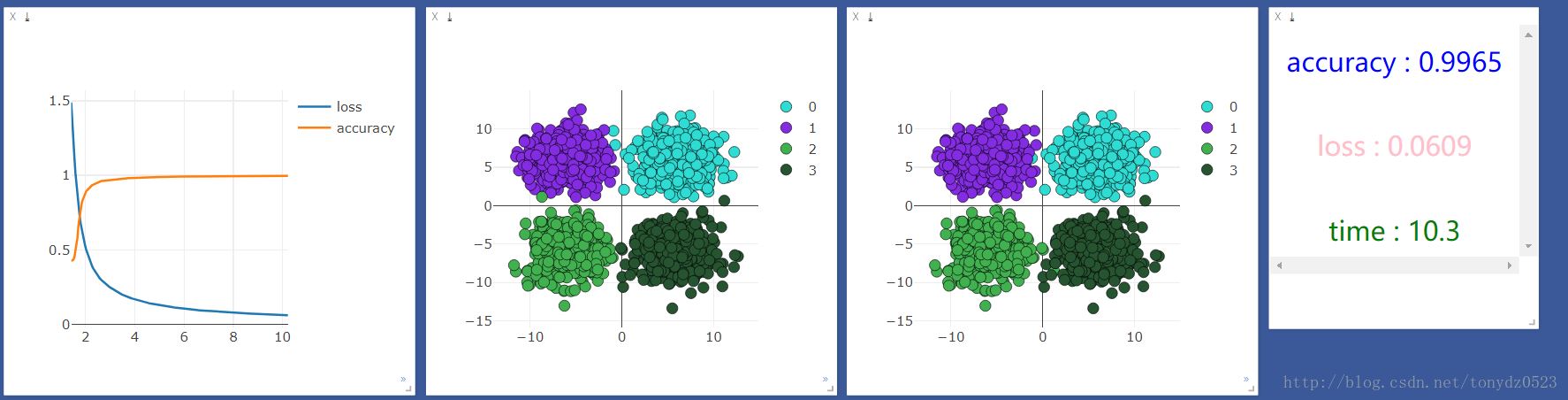
使用gpu:
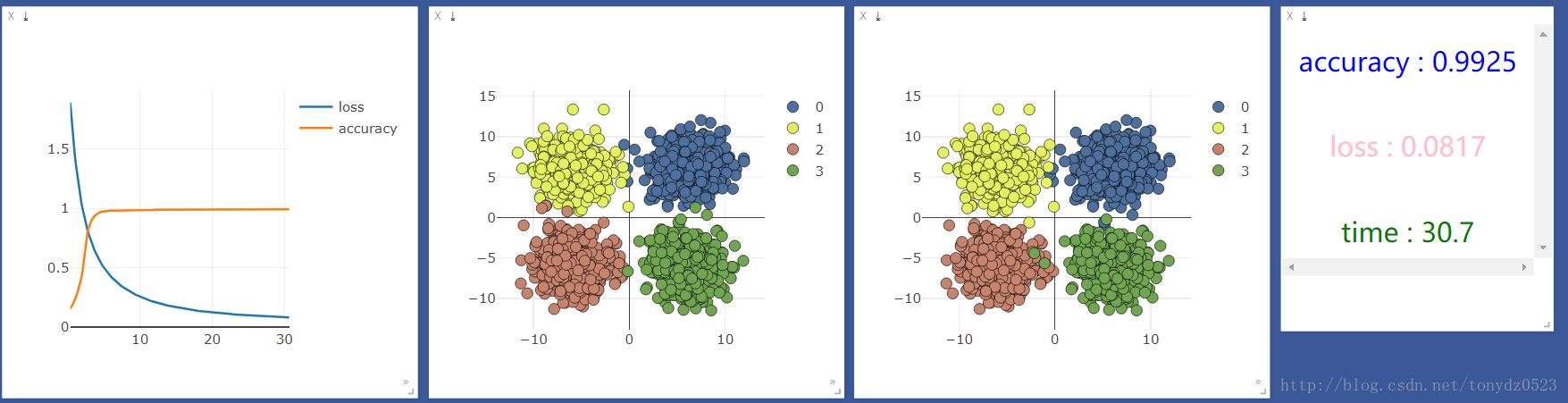
比较观察,似乎并没有什么区别,看来处理简单分类问题(输入,输出少)的问题,神经层和gpu不会对机器学习加持。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

pytorch + visdom CNN处理自建图片数据集的方法
环境 系统:win10 cpu:i7-6700HQ gpu:gtx965m python : 3.6 pytorch :0.3 数据下载 来源自Sasank Chilamkurthy 的教程: 数据:下载链接. 下载后解压放到项目根目录: 数据集为用来分类 蚂蚁和蜜蜂.有大约120个训练图像,每个类有75个验证图像. 数据导入 可以使用 torchvision.datasets.ImageFolder(root,transforms) 模块 可以将 图片转换为 tensor. 先定义transf
-
pytorch + visdom 处理简单分类问题的示例
环境 系统 : win 10 显卡:gtx965m cpu :i7-6700HQ python 3.61 pytorch 0.3 包引用 import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim 数据准备 use_gpu = True ones = n
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
Pytorch实现基于CharRNN的文本分类与生成示例
1 简介 本篇主要介绍使用pytorch实现基于CharRNN来进行文本分类与内容生成所需要的相关知识,并最终给出完整的实现代码. 2 相关API的说明 pytorch框架中每种网络模型都有构造函数,在构造函数中定义模型的静态参数,这些参数将对模型所包含weights参数的维度进行设置.在运行时,模型的实例将接收动态的tensor数据并调用forword,在得到模型输出之后便可以和真实的标签数据进行误差计算,并通过优化器进行反向传播以调整模型的参数.下面重点介绍NLP常用到的模型和相关方法. 2
-
pytorch visdom安装开启及使用方法
安装 conda activate ps pip install visdom 激活ps的环境,在指定的ps环境中安装visdom 开启 python -m visdom.server 浏览器输入红框内的网址 使用 1. 简单示例:一条线 from visdom import Visdom # 创建一个实例 viz=Visdom() # 创建一个直线,再把最新数据添加到直线上 # y x二维两个轴,win 创建一个小窗口,不指定就默认为大窗口,opts其他信息比如名称 viz.line([1,2
-
超详细PyTorch实现手写数字识别器的示例代码
前言 深度学习中有很多玩具数据,mnist就是其中一个,一个人能否入门深度学习往往就是以能否玩转mnist数据来判断的,在前面很多基础介绍后我们就可以来实现一个简单的手写数字识别的网络了 数据的处理 我们使用pytorch自带的包进行数据的预处理 import torch import torchvision import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt
-
基于PyTorch实现一个简单的CNN图像分类器
pytorch中文网:https://www.pytorchtutorial.com/ pytorch官方文档:https://pytorch.org/docs/stable/index.html 一. 加载数据 Pytorch的数据加载一般是用torch.utils.data.Dataset与torch.utils.data.Dataloader两个类联合进行.我们需要继承Dataset来定义自己的数据集类,然后在训练时用Dataloader加载自定义的数据集类. 1. 继承Dataset类并
-
Python机器学习之基于Pytorch实现猫狗分类
一.环境配置 安装Anaconda 具体安装过程,请点击本文 配置Pytorch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision 二.数据集的准备 1.数据集的下载 kaggle网站的数据集下载地址: https://www.kaggle.com/lizhensheng/-2000 2.
-
PyTorch实现手写数字识别的示例代码
目录 加载手写数字的数据 数据加载器(分批加载) 建立模型 模型训练 测试集抽取数据,查看预测结果 计算模型精度 自己手写数字进行预测 加载手写数字的数据 组成训练集和测试集,这里已经下载好了,所以download为False import torchvision # 是否支持gpu运算 # device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # print(device) # print(torch.cud
-
SpringMVC简单整合Angular2的示例
本文介绍了SpringMVC简单整合Angular2的示例,分享给大家,具体如下: angular使用的是官方的快速开始的例子 将文件全部拷贝到springmvc的项目中,拷贝过程中可能出现文件路径太长而失败,那就先对整个文件压缩,然后拷贝压缩过后的文件,然后解压缩即可.目录结构如下,我是拷贝到angular目录下的 spring配置文件设置路径 然后再html页面中如angular官方所示,引入文件 这里面需要对这些文件的路径进行配置 主要是systemjs.config文件中需要修改两个地方
-
原生js实现简单的模态框示例
html部分: <img src="images/8.jpg" alt=""> <button class="btn" id="showMax">显示大图</button> <div id="modalBox" class="modalBox"> <div class="modalBox-matter"> &