基于一个简单定长内存池的实现方法详解
主要分为 3 个部分,memoryPool 是管理内存池类,block 表示内存块,chunk 表示每个存储小块。它们之间的关系为,memoryPool 中有一个指针指向某一起始 block,block 之前通过 next 指针构成链表结构的连接,每个 block 包含指定数量的 chunk。每次分配内存的时候,分配 chunk 中的数据地址。

主要数据结构设计:
struct block {
block * next;//指向下一个block指针
unsigned int numofChunks;
unsigned int numofFreeChunks;//剩余free的chunk数量
unsigned int blockNum;//该block的编号
char * data;
queue<int> freepos; //记录可用chunk序号
};
class memoryPool {
unsigned int initNumofChunks; //每个block的chunk数量
unsigned int chunkSize;//每个chunk的数据大小
unsigned int steps;//每次扩展的chunk数量
unsigned int numofBlocks;//当前管理多少个blocks
block * blocksPtr;//指向起始block
block * blocksPtrTail;//指向末尾block
block * firstHasFreeChunksBlock;//指向第一个不为空的block
};
Chunk:
ChunkNum:该 chunk 所在 block 里的编号
blockAddress: 该 chunk 所对应的 block,主要用于 free 这个 chunk 的时候,能够快速找到所属 block,并进行相应更新
data:实际供使用的数据起始位置
关键操作说明:
内存分配:
从 firstHasFreeChunksBlock 开始查找第一个有 free 位置的 block,如果找到,则则获取该 block 的 freepos 的队首元素,返回该元素序号对应的 chunk 的数据地址,并将 freepos 的队首元素弹出,其他相关属性更新。如果找不到,则新增 steps 个 chunk,再重复上面的过程。
内存释放:
传入待释放的地址指针p,通过对p的地址移动可以找到chunk中的 ChunkNum 和 blockAddress 两个数据,通过 blockAddress 可以找到该 chunk 所属的 block,然后将ChunkNum 添加到该 block 的 freepos 中,其他相应属性更新。
memoryPool * mp = new memoryPool (256);
char * s = (char *)mp->allocate();
// 一些操作
mp->freeMemory(s);
delete mp;
不足:
没考虑线程安全问题,该实现方案在单线程下可以正常运行。
#include <iostream>
#include <queue>
#include <string.h>
#include <ctime>
using namespace std;
struct block {
block * next;
unsigned int numofChunks;//指向下一个block指针
unsigned int numofFreeChunks;//剩余free的chunk数量
unsigned int blockNum;//该block的编号
char * data;
//记录可用chunk序号
queue<int> freepos;
block(unsigned int _numofChunks ,unsigned int _chunkSize, unsigned int _blockNum){
numofChunks = _numofChunks;
numofFreeChunks = _numofChunks;
blockNum = _blockNum;
next = NULL;
data = new char [numofChunks * (sizeof(unsigned int) + sizeof(void *) + _chunkSize)];
char * p = data;
//每个chunk的结构:4byte的chunk序号 + 4byte的所属block地址 + 真正的数据
for(int i=0;i<numofChunks;i++){
char * ptr = p + i * (_chunkSize + sizeof(unsigned int) + sizeof(void *));
unsigned int * num = (unsigned int *)(ptr);
*num = i;
ptr += sizeof(void *);
int * blockpos = (int *) ptr;
*blockpos = (int)this;
freepos.push(i);
}
}
~block(){
delete [] data;
}
};
class memoryPool {
public :
memoryPool(unsigned int _chunkSize = 256, unsigned int _initNumofChunks = 4096, unsigned int _steps = 64){
initNumofChunks = _initNumofChunks;
chunkSize = _chunkSize;
steps = _steps;
numofBlocks = steps;
//创建内存池时,初始化一定数量的内存空间
block * p = new block(initNumofChunks, chunkSize, 0);
blocksPtr = p;
for(int i=1;i<steps;i++){
p->next = new block(initNumofChunks, chunkSize, i);
p = p->next;
blocksPtrTail = p;
}
firstHasFreeChunksBlock = blocksPtr;
}
~memoryPool(){
block * p = blocksPtr;
while(blocksPtr!=NULL){
p = blocksPtr->next;
delete blocksPtr;
blocksPtr = p;
}
}
/*
从firstHasFreeChunksBlock开始查找第一个有free位置的block,
如果找到,则则获取该block的freepos的对首元素,
返回该元素序号对应的chunk的数据地址,并将freepos的队首元素弹出,
其他相关属性更新。如果找不到,则新增steps个chunk,再重复上面的过程。
*/
void * allocate(){
block * p = firstHasFreeChunksBlock;
while(p != NULL && p->numofFreeChunks <= 0) p = p->next;
if(p == NULL){
p = blocksPtrTail;
increaseBlocks();
p = p->next;
firstHasFreeChunksBlock = p;
}
unsigned int pos = p->freepos.front();
void * chunkStart = (void *)(p->data + pos * (chunkSize + sizeof(unsigned int) + sizeof(void *)));
void * res = chunkStart + sizeof(unsigned int) + sizeof(void *);
p->freepos.pop();
p->numofFreeChunks --;
return res;
}
void increaseBlocks(){
block * p = blocksPtrTail;
for(int i=0; i<steps; i++){
p->next = new block(initNumofChunks, chunkSize, numofBlocks);
numofBlocks++;
p = p->next;
blocksPtrTail = p;
}
}
/*
传入待释放的地址指针_data,
通过对_data的地址移动可以找到chunk中的ChunkNum和blockAddress两个数据,
通过blockAddress可以找到该chunk所属的block,
然后将ChunkNum添加到该block的freepos中,其他相应属性更新。
*/
void freeMemory(void * _data){
void * p = _data;
p -= sizeof(void *);
int * blockpos = (int *) p;
block * b = (block *) (*blockpos);
p -= sizeof(unsigned int);
int * num = (int *) p;
b->freepos.push(*num);
b->numofFreeChunks ++;
if (b->numofFreeChunks > 0 && b->blockNum < firstHasFreeChunksBlock->blockNum)
firstHasFreeChunksBlock = b;
}
private :
unsigned int initNumofChunks; //每个block的chunk数量
unsigned int chunkSize;//每个chunk的数据大小
unsigned int steps;//每次扩展的chunk数量
unsigned int numofBlocks;//当前管理多少个blocks
block * blocksPtr;//指向起始block
block * blocksPtrTail;//指向末尾block
block * firstHasFreeChunksBlock;//指向第一个不为空的block
};
//test
void echoPositionNum(char * p){
p -= (sizeof(void *) + sizeof(unsigned int));
int * num = (int *) p;
cout<<*num<<endl;
}
//测试
void test0(){
memoryPool mp;
char * s1 = (char *)mp.allocate();
char * s2 = (char *)mp.allocate();
char str [256];
char str2 [256];
char str3 [256];
for(int i=0; i<255; i++) {
str[i] = 'a';str2[i] = 'b';str3[i] = 'c';
}
str[255] = '\0';
str2[255] = '\0';
strcpy(s1,str);
strcpy(s2,str2);
str3[255] = '\0';
echoPositionNum(s1);
cout<<s1<<endl;
mp.freeMemory(s1);
echoPositionNum(s2);
cout<<s2<<endl;
char * s3 = (char *)mp.allocate();
strcpy(s3,str3);
echoPositionNum(s3);
cout<<s3<<endl;
}
void test1(){
clock_t clock_begin = clock();
const int N = 50000;
char * s[N];
int round = 100;
while(round>=0){
round --;
for(int i=0;i<N;i++){
s[i] = new char[256];
}
for(int i=0;i<N;i++){
delete [] s[i];
}
}
clock_t clock_end = clock();
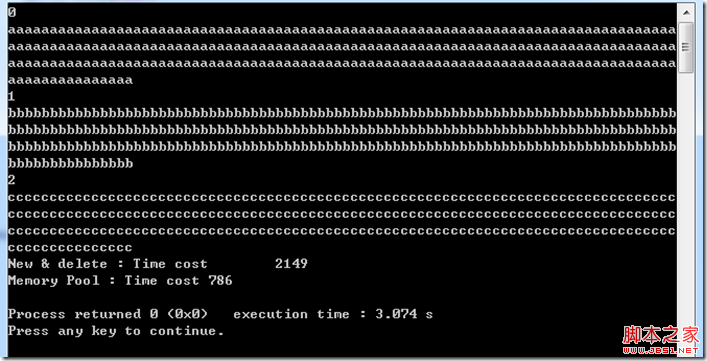
cout<<"Time cost\t"<<clock_end - clock_begin<<endl;
}
void test2(){
memoryPool mp(256);
clock_t clock_begin = clock();
const int N = 50000;
char * s[N];
int round = 100;
while(round>=0){
round --;
for(int i=0;i<N;i++){
s[i] = (char *)mp.allocate();
}
for(int i=0;i<N;i++){
mp.freeMemory(s[i]);
}
}
clock_t clock_end = clock();
cout<<"Time cost\t"<<clock_end - clock_begin<<endl;
}
int main()
{
test0();
test1();
test2();
return 0;
}
运行结果:
相关推荐
-

详解Nginx中基本的内存池初始化配置
ngx_cycle 的初始化 整个初始化过程中,最重要的就是全局变量 nginx_cycle 的初始化,很多变量都是在这个过程中初始化的 nginx_cycle 又是通过两个局部变量 init_cycle 和 cycle 实现初始化的 事实上,日志初始化也可以算是对 nginx_cyle 的初始化,因为在代码中接下来马上要发生的就是一个赋值 ngx_memzero(&init_cycle, sizeof(ngx_cycle_t)); init_cycle.log = log; ngx_cycle
-
实现一个内存池管理的类方法
模拟STL中的freelist,有这个思想在内. union obj { union obj* next; char p[1]; }; class MemoryPool { public: MemoryPool() { union obj* temp; m_memory.assign(5,(union obj*)NULL); for(int i=0;i<m_memory.size();i++) { for(int j=0;j<m_memory.size();j++) { temp = (obj
-
基于一个简单定长内存池的实现方法详解
主要分为 3 个部分,memoryPool 是管理内存池类,block 表示内存块,chunk 表示每个存储小块.它们之间的关系为,memoryPool 中有一个指针指向某一起始 block,block 之前通过 next 指针构成链表结构的连接,每个 block 包含指定数量的 chunk.每次分配内存的时候,分配 chunk 中的数据地址. 主要数据结构设计: Block: 复制代码 代码如下: struct block { block * next;//指向下一个block指针
-
C++如何实现定长内存池详解
目录 1. 池化技术 2. 内存池概念 2.1 内存碎片 3. 实现定长内存池 3.1 定位new表达式(placement-new) 3.2 完整实现 总结 1. 池化技术 池是在计算机技术中经常使用的一种设计模式,其内涵在于:将程序中需要经常使用的核心资源先申请出来,放到一个池内,由程序自己管理,这样可以提高资源的使用效率,也可以保证本程序占有的资源数量. 经常使用的池技术包括内存池.线程池和连接池(数据库经常使用到)等,其中尤以内存池和线程池使用最多. 2. 内存池概念 内存池(Memor
-
java并发编程_线程池的使用方法(详解)
一.任务和执行策略之间的隐性耦合 Executor可以将任务的提交和任务的执行策略解耦 只有任务是同类型的且执行时间差别不大,才能发挥最大性能,否则,如将一些耗时长的任务和耗时短的任务放在一个线程池,除非线程池很大,否则会造成死锁等问题 1.线程饥饿死锁 类似于:将两个任务提交给一个单线程池,且两个任务之间相互依赖,一个任务等待另一个任务,则会发生死锁:表现为池不够 定义:某个任务必须等待池中其他任务的运行结果,有可能发生饥饿死锁 2.线程池大小 注意:线程池的大小还受其他的限制,如其他资源池:
-
LyScript实现对内存堆栈扫描的方法详解
LyScript插件中提供了三种基本的堆栈操作方法,其中push_stack用于入栈,pop_stack用于出栈,而最有用的是peek_stack函数,该函数可用于检查指定堆栈位置处的内存参数,利用这个特性就可以实现,对堆栈地址的检测,或对堆栈的扫描等. LyScript项目地址:https://github.com/lyshark/LyScript peek_stack命令传入的是堆栈下标位置默认从0开始,并输出一个十进制有符号长整数,首先实现有符号与无符号数之间的转换操作,为后续堆栈扫描做准
-
基于Python的Post请求数据爬取的方法详解
为什么做这个 和同学聊天,他想爬取一个网站的post请求 观察 该网站的post请求参数有两种类型:(1)参数体放在了query中,即url拼接参数(2)body中要加入一个空的json对象,关于为什么要加入空的json对象,猜测原因为反爬虫.既有query参数又有空对象体的body参数是一件脑洞很大的事情. 一开始先在apizza网站 上了做了相关实验才发现上面这个规律的,并发现该网站的请求参数要为raw形式,要是直接写代码找规律不是一件容易的事情. 源码 import requests im
-
jmeter在linux系统下运行及本地内存调优的方法详解
1.在linux系统下安装跨系统传输文件工具 root用户下 根目录输入 yum -y install lrzsz 2.把apache-jmeter-4.0zip包 用rz命令上传到linux系统的根目录下 解压 3.配置jmeter环境变量 vim /etc/profile 添加 export PATH=/apache-jmeter-4.0/bin/:$PATH 注意路径 4.使用 rz命令上传jdk1.8 linux 64位版本 解压到 usr/local 目录下 下载jdk安装包 下载地址
-
PHP内存溢出的解决方法详解
目录 1.处理数组时出现内存溢出 2.使用sql查询数据,查出来很多,导致内存溢出 3.假定日志中存放的记录数为500000条,那么解决方案如下 4.上传excel文件时,出现内存溢出的情况 什么是内存溢出 内存溢出是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于虚拟机能提供的最大内存. 引起内存溢出的原因有很多种,常见的有以下几种: 1 内存中加载的数据量过于庞大,如一次从数据库取出过多数据: 2 集合类中有对对象的引用,使用完后未清空: 3 代码中存在死循环
-
PHP长连接实现与使用方法详解
本文实例讲述了PHP长连接实现与使用方法.分享给大家供大家参考,具体如下: 长连接技术(Long Polling) 在服务器端hold住一个连接, 不立即返回, 直到有数据才返回, 这就是长连接技术的原理 长连接技术的关键在于hold住一个HTTP请求, 直到有新数据时才响应请求, 然后客户端再次自动发起长连接请求. 那怎么样hold住一个请求呢?服务器端的代码可能看起来像这样的 set_time_limit(0); //这句很重要, 不至于运行超时 while (true) { if (has
-
golang sql连接池的实现方法详解
前言 golang的"database/sql"是操作数据库时常用的包,这个包定义了一些sql操作的接口,具体的实现还需要不同数据库的实现,mysql比较优秀的一个驱动是:github.com/go-sql-driver/mysql,在接口.驱动的设计上"database/sql"的实现非常优秀,对于类似设计有很多值得我们借鉴的地方,比如beego框架cache的实现模式就是借鉴了这个包的实现:"database/sql"除了定义接口外还有一个重
-
利用 Docker 构建简单的 java 开发编译环境的方法详解
目前 Java 语言的版本很多,除了常用的 Java 8,有一些遗留项目可能使用了 Java 7,也可能有一些比较新的的项目使用了 Java 10 以上的版本.如果想切换自己本地的 Java 开发环境,折腾起来还是需要花费一些时间的,并且日后在不同版本间切换每次都要折腾一次. Docker 的出现让我们维护不同版本的开发编译环境变得简单,如果你还不知道什么是 Docker 可以看看 Docker 入门介绍.我们可以采用两种方式来构建 java 的开发环境,一种是在容器内编译运行,一种是在容器外编