SQL Server统计信息更新时采样百分比对数据预估准确性的影响详解
为什么要写统计信息
最近看到园子里有人写统计信息,楼主也来凑热闹。
话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯。
当然解决办法也并非一成不变,“一招鲜吃遍天”的做法已经行不通了(题外话:整个时代不都是这样子吗)
当然,还是那句话,既然写了就不能太俗套,写点不一样的,本文通过分析一个类似实际案例来解读统计信息的更新的相关问题。
对于实际问题,不但要解决问题,更重要的是要从理论上深入分析,才能更好地驾驭数据库。
何时更新统计信息
(1)查询执行缓慢,或者查询语句突然执行缓慢。这种场景很可能是由于统计信息没有及时更新而遭遇了参数嗅探的问题。
(2)当大量数据更新(INSERT/DELETE/UPDATE)到升序或者降序的列时,这种情况下,统计信息直方图可能没有及时更新。
(3)建议在除索引维护(当你重建、整理碎片或者重组索引时,数据分布不会改变)外的维护工作之后更新统计信息。
(4)数据库的数据更改频繁,建议最低限度每天更新一次统计信息。数据仓库可以适当降低更新统计信息的频率。
(5)当执行计划出现统计信息缺失警告时,需要手动建立统计信息
统计信息基础
首先说一个老掉牙的话题,统计信息的更新阈值:
1,表格从没有数据变成有大于等于1条数据。
2,对于数据量小于500行的表格,当统计信息的第一个字段数据累计变化量大于500以后。
3,对于数据量大于500行的表格,当统计信息的第一个字段数据累计变化量大于500 + (20%×表格数据总量)以后。
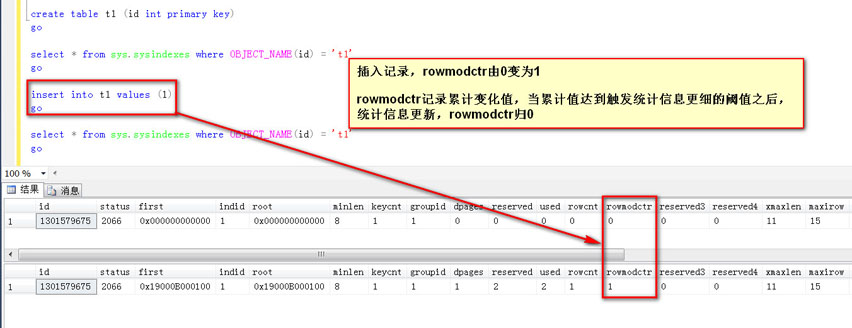
做个查询,触发统计信息更新,rowmodct归0(继续累积直到下一个触发的阈值,触发更新之后再次归0)
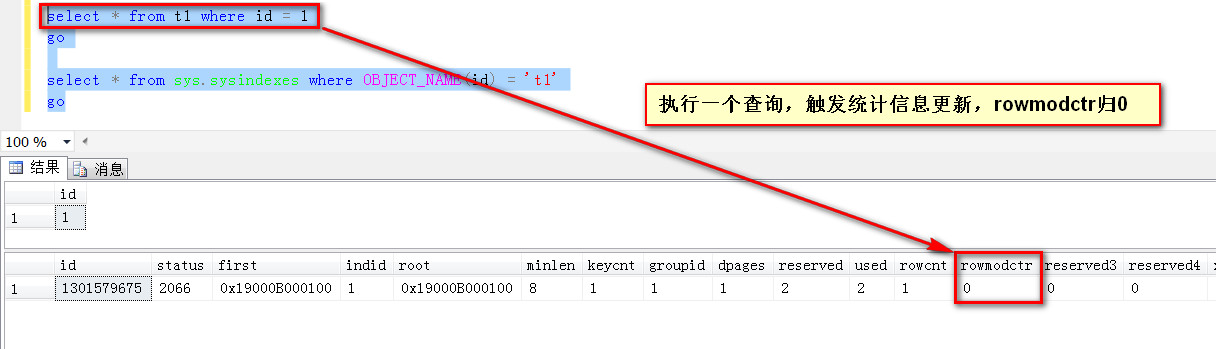
关于统计信息“过期”的问题
下面开始正文,网络上很多关于统计信息的文章,提到统计信息,很多都是统计信息过期的问题,然后跟新之后怎么怎么样
尤其在触发统计信息自动更新阈值的第三个区间:也就是说数据累计变化超过20%之后才能自动触发统计信息的更新
这一点对于大表来说通常影响是比较大的,比如1000W的表,变化超过20%也+500也就是200W+500行之后才触发统计信息更新,这个阈值区间的自动触发阈值,绝大多数情况是不能接受的,于是对于统计信息的诊断就变成了是否“过期”
判断统计信息是否过期,然后通过更新统计信息来促使执行计划更加准确地预估行数,这一点本无可厚非
但是,问题也就出在这里了:那么怎么更新统计信息?一成不变的做法是否可行,这才是问题的重点。
当然肯定有人说,我就是按照默认方式更新的,更新完之后SQL也变得更加优化了什么的
通过update statistics TableName StatisticName更新某一个索引的统计信息,
或者update statistics TableName更新全表的统计信息
这种情况下往往是小表上可以这么做,当然对于大表或者小表没有一个标准值,一切要结合事实来说明问题
下面开始本文的主题:
抽象并简化出业务中的一个实际案例,创建这么一张表,类似于订单和订单明细表(主子表),
这里你可以想象成是一个订单表的子表,Id字段是唯一的,有一个ParentID字段,是非唯一的,
ParentID类似于主表的Id,测试数据按照一个主表Id对应50条子表明细的规律插入数据
CREATE TABLE [dbo].[TestStaitisticsSample]( [Id] [int] IDENTITY(1,1) NOT NULL, [ParentId] [int] NULL, [OtherColumn] [varchar](50) NULL ) declare @i int=0 while(@i<100000000) begin insert into [TestStaitisticsSample](ParentId,OtherColumn)values(@i,NEWID()) /* 中间插入50条,也即一个主表Id对应50条子表明细 */ insert into [TestStaitisticsSample](ParentId,OtherColumn)values(@i,NEWID()) set @i=@i+1 end go create nonclustered index [idx_ParentId] ON [dbo].[TestStaitisticsSample] ( [ParentId] ) go
本来打算插入1亿条的,中间我让他执行我睡午觉去了,醒来之后发现SSMS挂掉了,挂掉了算了,数据也接近1亿了,能说明问题就够了
现在数据分布的非常明确,就是一个ParentId有50条数据,这一点首先要澄清。
测试数据写入,以及所创建完成之后来更新idx_ParentId 索引上的统计信息,就按照默认的方式来更新,然后来观察统计信息
默认方式更新统计信息(未指定采样密度)
表里现在是8000W多一点记录,默认更新统计信息时取样行数是462239行,那么这个统计信息靠谱吗?
上面说了,造数据的时候,我一个ParentId对应的是50行记录,这一点非常明确,他这里统计出来的多少?
1,对于取样的RANG_HI_Key值,比如51632,预估了862.212行
2,对于AVG_RANG_ROW,比如45189到51632之间的每个Id的数据对应的数据行,预估是6682.490行
之前造数据的时候每个Id都是50行,这里的预估靠谱吗,这个误差是无法接受的,
很多时候,对于大表,采用默认(未指定采样密度)的情况下,默认的采样密度并不足以准确地描述数据分布情况
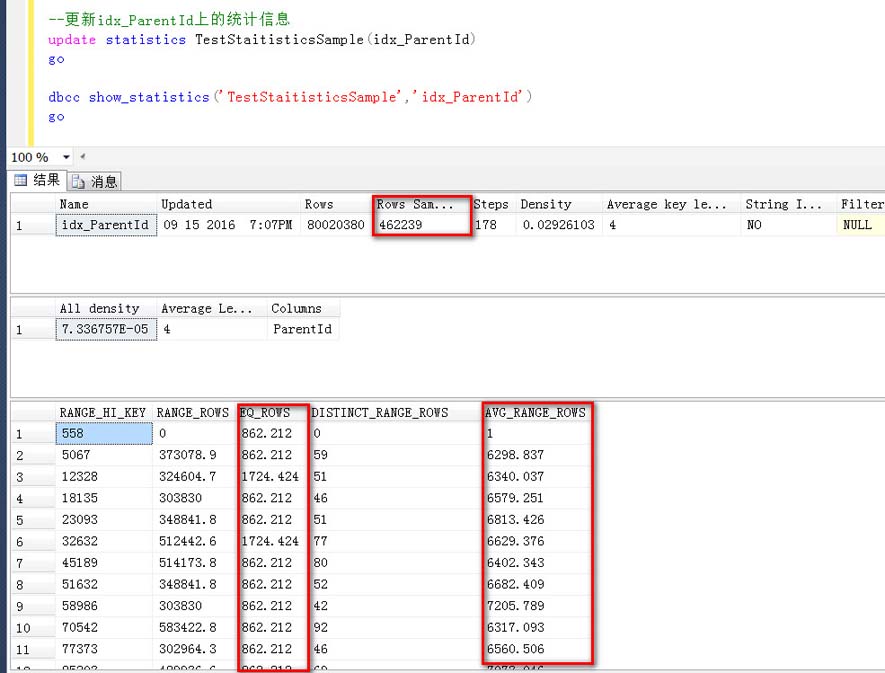
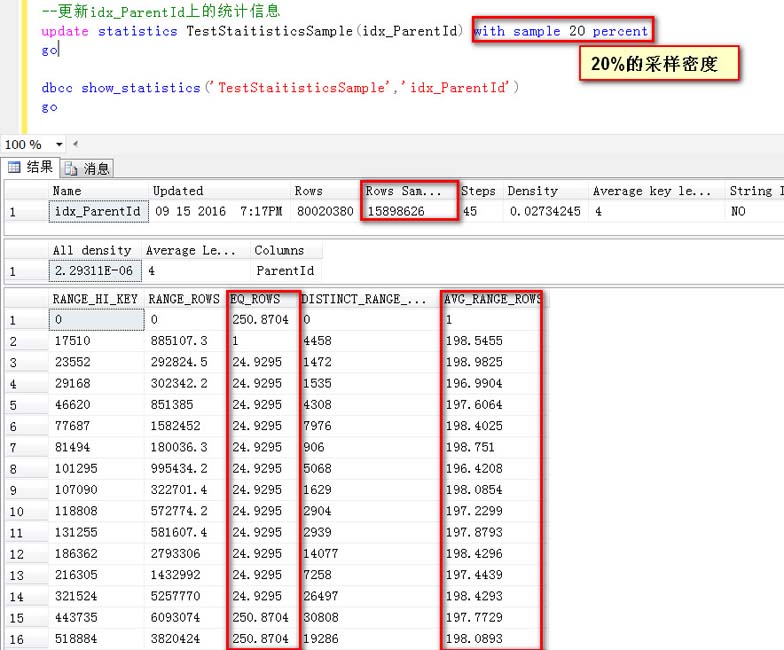
指定一个采样密度的方式更新统计信息(20%采样)
这一次用20%的采样密度,可以看到取样的行数是15898626行
1,对于取样的RANG_HI_Key值,比如216305,他给我预估了24.9295行
2,对于AVG_RANG_ROW,比如186302到216305之间的每个Id的行数,预估是197.4439行
观察比如上面默认的取样密度,这一次不管是RANG_HI_Key还是AVG_RANG_ROW得预估,都有不一个非常高的下降,开始趋于接近于真实的数据分布(每个Id有50行数据)
整体上看,但是这个误差还是比较大的,如果继续提高采样密度,看看有什么变化?
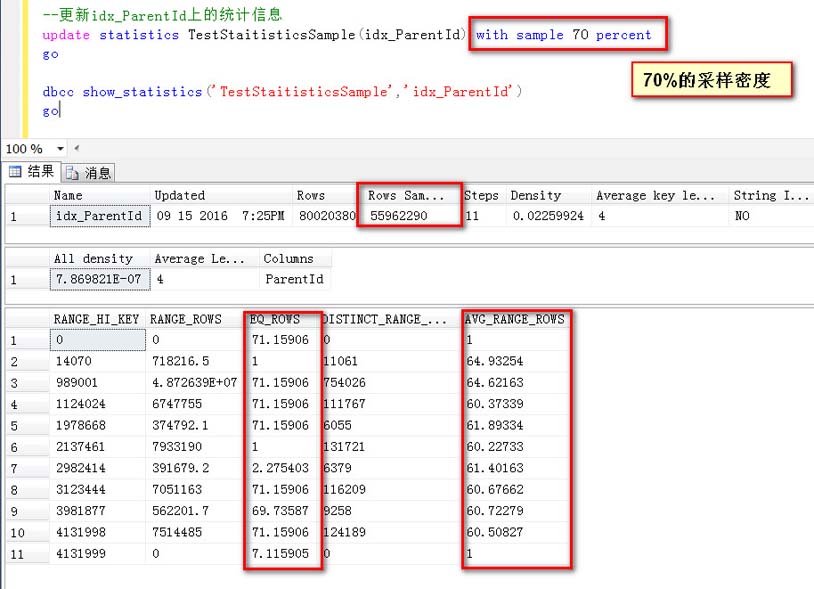
指定一个采样密度的方式更新统计信息(70%采样)
这一次用70%的采样密度,可以看到取样行数是55962290行
1,对于取样的RANG_HI_Key值,比如1978668,预估了71.15906行
2,对于AVG_RANG_ROW,比如1124024到1978668之间的每个Id,预估为61.89334行
可以说,对于绝大多数值得预估(AVG_RANG_ROW),都愈发接近于真实值
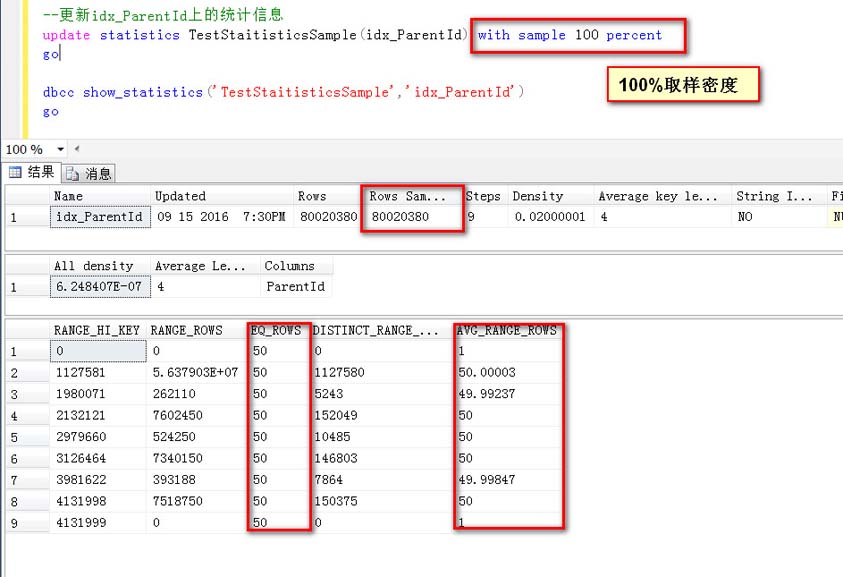
指定一个采样密度的方式更新统计信息(100%采样)
可以看到,取样行数等于总行数,也就是所谓的全部(100%)取样
看一下预估结果:
比如Id=3981622,预估是50行,3981622与4131988之间的Id的行数,预估为49.99874行,基本上等于真实数据分布
这个就不做过多解释了,基本上跟真实值是一样的,只是AVG_RANG_ROW有一点非常非常小的误差。
取样密度高低与统计信息准确性的关系
至于为什么默认取样密度和较低取样密度情况下,误差很大的情况我简单解释一下,也非常容易理解,因为“子表”中存储主表ID的ParentId值允许重复,在存在重复值的情况下,如果采样密度不够,极有可能造成“以偏概全”的情况
比如对10W行数据取样1W行,原本10W行数剧中有2000个不重复的ParentId值,如果是10%的取样,在1W行取样数据中,因为密度不够大,只找到了20个不重复的ParentId值,那么就会认为每一行ParentId对应500行数据,这根实际的分布的每个ParentId有一个非常大的误差范围
如果提高采样密度,那么这个误差就会越来越小。
更新统计信息的时候,高比例的取样是否可取(可行)
因此在观察统计信息是否过期,决定更新统计信息的时候,一定要注意取样的密度,就是说表中有多少行数据,统计信息更新的时候取了多少采样行,密度有多高。
当然,肯定有人质疑,那你说采样密度越高,也就是取样行数越高越准确,那么我就100%取样。
这样行不行?
还要分情况看,对于几百万或者十几万的小表来说,当然没有问题,这也是为什么数据库越小,表数据越少越容易掩盖问题的原因。
对于大表,上亿的,甚至是十几亿的,你按照100%采样试一试?
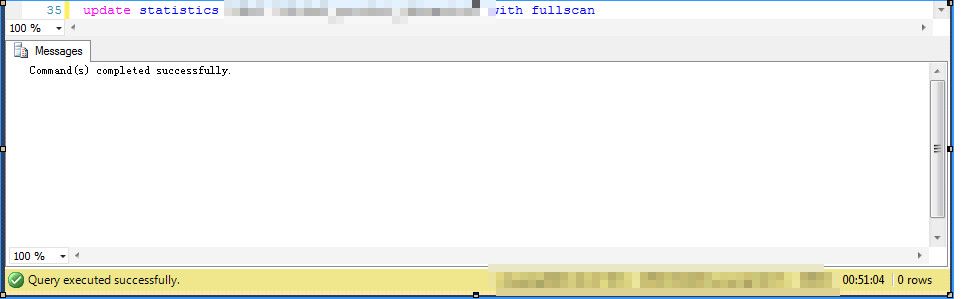
举个实际例子:
我这里对一个稍微大一点的表做个全表统计信息的更新,测试环境,服务器没负载,存储是比普通的机械硬盘要强很多的SAN存储
采用full scan,也就是100%采样的更新操作,看一下,仅仅这一样表的update statistic操作就花费了51分钟
试想一下,对一个数百GB甚至数TB的库来说,你敢这么搞一下。
扯一句,这个中秋节过的,折腾了大半天,话说做测试过程中电脑有开始有点卡,
做完测试之后停掉SQLServer服务,瞬间内存释放了7个G,可见这些个操作还是比较耗内存的
总结:
本文通过对于某些场景下,在对较大的表的索引统计信息更新时,采样密度的分析,阐述了不同采样密度下,对统计信息预估的准确性的影响。
当然对于小表,一些都好说。
随着单表数据量的增加,统计信息的更新策略也要做相应的调整,
不光要看统计信息是否“过期”,更重要的是注意统计信息更新时究竟取样了全表的多少行数据做统计。
对于大表,采用FULL SCAN或者100%采样往往是不可行的,这时候就需要做出权衡,做到既能准确地预估,又能够以合理的代价执行。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持
相关推荐
-

SQLSERVER收集语句运行的统计信息并进行分析
对于语句的运行,除了执行计划本身,还有一些其他因素要考虑,例如语句的编译时间.执行时间.做了多少次磁盘读等. 如果DBA能够把问题语句单独测试运行,可以在运行前打开下面这三个开关,收集语句运行的统计信息. 这些信息对分析问题很有价值. 复制代码 代码如下: SET STATISTICS TIME ON SET STATISTICS IO ON SET STATISTICS PROFILE ON SET STATISTICS TIME ON ----------------------------
-
SQL Server自动更新统计信息的基本算法
自动更新统计信息的基本算法是: · 如果表格是在 tempdb 数据库表的基数是小于 6,自动更新到表的每个六个修改. · 如果表的基数是大于 6,但小于或等于 500,更新状态每 500 的修改. · 如果基数大于 500,表为更新统计信息时(500 + 20%的表)发生了更改. · 表变量为基数的更改不会触发自动更新统计信息. 注意:此严格意义上讲,SQL Server 计算基数为表中的行数. 注意:除了基数,该谓语的选择性也会影响 AutoStats 生成.这意味着该统计信息可能无法更新的
-
SQLSERVER语句的执行时间显示的统计结果是什么意思
在SQL语句调优的时候,大部分都会查看语句执行时间,究竟SQLSERVER显示出来的统计结果是什么意思? 下面看一下例子 比较简单的语句: 复制代码 代码如下: 1 SET STATISTICS TIME ON 2 USE [pratice] 3 GO 4 SELECT * FROM [dbo].[Orders] 结果: 复制代码 代码如下: SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒. SQL Server 执行时间: CPU 时间 = 0 毫秒
-
SQLServer2005 中的几个统计技巧
在SQLServer中我们可以用over子句中来代替子查询实现来提高效率,over子句除了排名函数之外也可以和聚合函数配合.实现代码如下: 复制代码 代码如下: use tempdb go if (object_id ('tb' ) is not null ) drop table tb go create table tb (name varchar (10 ), val int ) go insert into tb select 'aa' , 10 union all select 'a
-
sqlserver 统计sql语句大全收藏
1.计算每个人的总成绩并排名 select name,sum(score) as allscore from stuscore group by name order by allscore 2.计算每个人的总成绩并排名 select distinct t1.name,t1.stuid,t2.allscore from stuscore t1,( select stuid,sum(score) as allscore from stuscore group by stuid)t2where t1
-
浅谈SQL Server中统计对于查询的影响分析
而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息. 如何查看统计信息 查看SQL Server的统计信息非常简单,使用如下指令: DBCC SHOW_STATISTICS('表名','索引名') 所得到的结果如图1所示. 图1.统计信息 统计信息如何影响查询 下面我们通过一个简单的例子来看统计信息是如何影响查询分析器.我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引
-
SQL Server统计信息更新时采样百分比对数据预估准确性的影响详解
为什么要写统计信息 最近看到园子里有人写统计信息,楼主也来凑热闹. 话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯. 当然解决办法也并非一成不变,"一招鲜吃遍天"的做法已经行不通了(题外话:整个时代不都是这样子吗) 当然,还是那句话,既然写了就不能太俗套,写点不一样的,本文通过分析一个类似实际案例来解读统计信息的更新的相关问题. 对于实际问题,不但要解决问题,更重要的是要从理论上深入分析,才能更好地驾驭数据库. 何时更新统计信息 (1)查询执行缓慢
-
sql server把退款总金额拆分到尽量少的多个订单中详解
一.问题 原来有三个充值订单,现在要退款450元,如何分配才能让本次退款涉及的充值订单数量最少?具体数据参考下图: 二.解决方案 Step 1:对可退金额进行降序排列,以便优先使用可退金额比较大的订单 Step 2:使用CTE公用表达式,实现类似for或while循环或游标的功能 三.脚本 create table #t ( 充值 int, 已退 int, 可退 int ) insert into #t(充值, 已退, 可退) values (200, 100, 100), (500, 200,
-
深入SQL Server中定长char(n)与变长varchar(n)的区别详解
char(n)是定长格式,格式为char(n)的字段固定占用n个字符宽度,如果实际存放的数据长度超过n将被截取多出部分,如果长度小于n就用空字符填充. varchar(n)是变长格式,这种格式的字段根据实际数据长度分配空间,不浪费对于的空间,但是搜索数据的速度会麻烦一点. 一般地说,只要一个表有一个字段定义为varchar(n)类型,那么其余用char(n)定义的字段实际上也是varchar(n)类型. 如果你的长度本身不长,比如就3-10个字符,那么使用char(n)格式效率比较高,搜索速度快
-
SQL Server实时同步更新远程数据库遇到的问题小结
工作中遇到这样的情况,需要在更新表TableA(位于服务器ServerA 172.16.8.100中的库DatabaseA)同时更新TableB(位于服务器ServerB 172.16.8.101中的库DatabaseB). TableA与TableB结构相同,但数据数量不一定相同,应为有可能TableC也在更新TableB.由于数据更新不频繁,为简单起见想到使用了触发器Tirgger.记录一下遇到的一些问题: 1. 访问异地数据库 在ServerA 中创建指向ServerB的链接服务器,并做好
-
使用SQL Server 2008远程链接时SQL数据库不成功的解决方法
远程连接SQL Server 2008,服务器端和客户端配置 关键设置: 第一步(SQL2005.SQL2008): 开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server网络配置-->MSSQLSERVER(这个名称以具体实例名为准) 的协议-->TCP/IP-->右键-->启用 第二步: SQL2005: 开始-->程序-->Mi
-
简析SQL Server数据库用视图来处理复杂的数据查询关系
SQL Server数据库用视图来处理复杂的数据查询关系是本文我们主要要介绍的内容,该内容是这样想到的:在辅助教务系统那块的时候,我做的一个页面是对单个老师和整个学院老师的工作量查询,这个操作设计到了三个本数据库中的表和一个不同数据库中的一个教师信息表,如果用普通的SQL语句是非常难实现的,由于我刚开始做的视频播放系统,数据库的表相对比较少,没有涉及到这么复杂的处理关系,刚开始感觉很难. 后来想到用视图可以解决多个表的复杂关系,但是另外一张表是不同数据库的,是否依然能进行操作,经过测试之后,居然
-
SQL Server 2012使用Offset/Fetch Next实现分页数据查询
在Sql Server 2012之前,实现分页主要是使用ROW_NUMBER(),在SQL Server2012,可以使用Offset ...Rows Fetch Next ... Rows only的方式去实现分页数据查询. select [column1] ,[column2] ... ,[columnN] from [tableName] order by [columnM] offset (pageIndex-1)*pageSize rows fetch next pageSize r
-
pytorch中的上采样以及各种反操作,求逆操作详解
import torch.nn.functional as F import torch.nn as nn F.upsample(input, size=None, scale_factor=None,mode='nearest', align_corners=None) r"""Upsamples the input to either the given :attr:`size` or the given :attr:`scale_factor` The algorith
-
SQL 使用 VALUES 生成带数据的临时表实例代码详解
VALUES 是 INSER 命令的子句. INSERT INOT 表名(列名1,列名2,-) VALUES(值1,值2,-) --语法: --SELECT * FROM ( --VALUES -- (1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) -- ,(1,2,3,......) --) AS t(c1,c2,c3......) SELECT * FROM (
-
SQL Server 2005附加数据库时Read-Only错误的解决方案
SQL Server 2005附加数据库文件时出现了Read-Only错误,附加的时候,系统提示mdf文件为只读,可是打开文件属性,这个属性不为只读.该怎么解决呢?本文我们就介绍了这一解决方案,接下来就让我们来一起了解一下吧. 两种解决方法如下: 1.重新打开数据库软件,在登录认证框那里选择:Windows authentication进行登录.然后再附加数据库,这时附加的就没有Read-Only了. 2.在*.mdf文件的属性里,找到"安全"页,然后把里面所有的"组或用户名