floyd算法实现思路及实例代码
正如我们所知道的,Floyd算法用于求最短路径。Floyd算法可以说是Warshall算法的扩展,三个for循环就可以解决问题,所以它的时间复杂度为O(n^3)。
Floyd算法的基本思想如下:从任意节点A到任意节点B的最短路径不外乎2种可能,1是直接从A到B,2是从A经过若干个节点X到B。所以,我们假设Dis(AB)为节点A到节点B的最短路径的距离,对于每一个节点X,我们检查Dis(AX) + Dis(XB) < Dis(AB)是否成立,如果成立,证明从A到X再到B的路径比A直接到B的路径短,我们便设置Dis(AB) = Dis(AX) + Dis(XB),这样一来,当我们遍历完所有节点X,Dis(AB)中记录的便是A到B的最短路径的距离。
很简单吧,代码看起来可能像下面这样:
for ( int i = 0; i < 节点个数; ++i )
{
for ( int j = 0; j < 节点个数; ++j )
{
for ( int k = 0; k < 节点个数; ++k )
{
if ( Dis[i][k] + Dis[k][j] < Dis[i][j] )
{
// 找到更短路径
Dis[i][j] = Dis[i][k] + Dis[k][j];
}
}
}
}
但是这里我们要注意循环的嵌套顺序,如果把检查所有节点X放在最内层,那么结果将是不正确的,为什么呢?因为这样便过早的把i到j的最短路径确定下来了,而当后面存在更短的路径时,已经不再会更新了。
让我们来看一个例子,看下图:
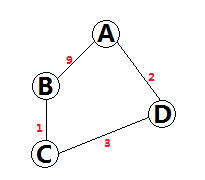
图中红色的数字代表边的权重。如果我们在最内层检查所有节点X,那么对于A->B,我们只能发现一条路径,就是A->B,路径距离为9。而这显然是不正确的,真实的最短路径是A->D->C->B,路径距离为6。造成错误的原因就是我们把检查所有节点X放在最内层,造成过早的把A到B的最短路径确定下来了,当确定A->B的最短路径时Dis(AC)尚未被计算。所以,我们需要改写循环顺序,如下:
代码如下:
for ( int k = 0; k < 节点个数; ++k )
{
for ( int i = 0; i < 节点个数; ++i )
{
for ( int j = 0; j < 节点个数; ++j )
{
if ( Dis[i][k] + Dis[k][j] < Dis[i][j] )
{
// 找到更短路径
Dis[i][j] = Dis[i][k] + Dis[k][j];
}
}
}
}
这样一来,对于每一个节点X,我们都会把所有的i到j处理完毕后才继续检查下一个节点。
那么接下来的问题就是,我们如何找出最短路径呢?这里需要借助一个辅助数组Path,它是这样使用的:Path(AB)的值如果为P,则表示A节点到B节点的最短路径是A->...->P->B。这样一来,假设我们要找A->B的最短路径,那么就依次查找,假设Path(AB)的值为P,那么接着查找Path(AP),假设Path(AP)的值为L,那么接着查找Path(AL),假设Path(AL)的值为A,则查找结束,最短路径为A->L->P->B。
那么,如何填充Path的值呢?很简单,当我们发现Dis(AX) + Dis(XB) < Dis(AB)成立时,就要把最短路径改为A->...->X->...->B,而此时,Path(XB)的值是已知的,所以,Path(AB) = Path(XB)。
好了,基本的介绍完成了,接下来就是实现的时候了,这里我们使用图以及邻接矩阵:
代码如下:
#define INFINITE 1000 // 最大值
#define MAX_VERTEX_COUNT 20 // 最大顶点个数
//////////////////////////////////////////////////////////////////////////
struct Graph
{
int arrArcs[MAX_VERTEX_COUNT][MAX_VERTEX_COUNT]; // 邻接矩阵
int nVertexCount; // 顶点数量
int nArcCount; // 边的数量
};
//////////////////////////////////////////////////////////////////////////
首先,我们写一个方法,用于读入图的数据:
void readGraphData( Graph *_pGraph )
{
std::cout << "请输入顶点数量和边的数量: ";
std::cin >> _pGraph->nVertexCount;
std::cin >> _pGraph->nArcCount;
std::cout << "请输入邻接矩阵数据:" << std::endl;
for ( int row = 0; row < _pGraph->nVertexCount; ++row )
{
for ( int col = 0; col < _pGraph->nVertexCount; ++col )
{
std::cin >> _pGraph->arrArcs[row][col];
}
}
}
void floyd( int _arrDis[][MAX_VERTEX_COUNT], int _arrPath[][MAX_VERTEX_COUNT], int _nVertexCount )
{
// 先初始化_arrPath
for ( int i = 0; i < _nVertexCount; ++i )
{
for ( int j = 0; j < _nVertexCount; ++j )
{
_arrPath[i][j] = i;
}
}
//////////////////////////////////////////////////////////////////////////
for ( int k = 0; k < _nVertexCount; ++k )
{
for ( int i = 0; i < _nVertexCount; ++i )
{
for ( int j = 0; j < _nVertexCount; ++j )
{
if ( _arrDis[i][k] + _arrDis[k][j] < _arrDis[i][j] )
{
// 找到更短路径
_arrDis[i][j] = _arrDis[i][k] + _arrDis[k][j];
_arrPath[i][j] = _arrPath[k][j];
}
}
}
}
}
void printResult( int _arrDis[][MAX_VERTEX_COUNT], int _arrPath[][MAX_VERTEX_COUNT], int _nVertexCount )
{
std::cout << "Origin -> Dest Distance Path" << std::endl;
for ( int i = 0; i < _nVertexCount; ++i )
{
for ( int j = 0; j < _nVertexCount; ++j )
{
if ( i != j ) // 节点不是自身
{
std::cout << i+1 << " -> " << j+1 << "\t\t";
if ( INFINITE == _arrDis[i][j] ) // i -> j 不存在路径
{
std::cout << "INFINITE" << "\t\t";
}
else
{
std::cout << _arrDis[i][j] << "\t\t";
// 由于我们查询最短路径是从后往前插,因此我们把查询得到的节点
// 压入栈中,最后弹出以顺序输出结果。
std::stack<int> stackVertices;
int k = j;
do
{
k = _arrPath[i][k];
stackVertices.push( k );
} while ( k != i );
//////////////////////////////////////////////////////////////////////////
std::cout << stackVertices.top()+1;
stackVertices.pop();
unsigned int nLength = stackVertices.size();
for ( unsigned int nIndex = 0; nIndex < nLength; ++nIndex )
{
std::cout << " -> " << stackVertices.top()+1;
stackVertices.pop();
}
std::cout << " -> " << j+1 << std::endl;
}
}
}
}
}
好了,是时候测试了,我们用的图如下:
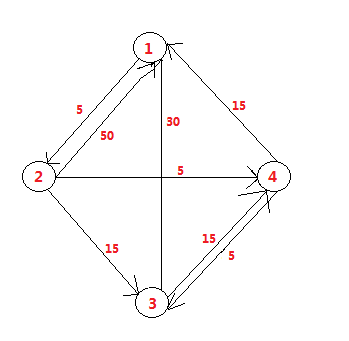
int main( void )
{
Graph myGraph;
readGraphData( &myGraph );
//////////////////////////////////////////////////////////////////////////
int arrDis[MAX_VERTEX_COUNT][MAX_VERTEX_COUNT];
int arrPath[MAX_VERTEX_COUNT][MAX_VERTEX_COUNT];
// 先初始化arrDis
for ( int i = 0; i < myGraph.nVertexCount; ++i )
{
for ( int j = 0; j < myGraph.nVertexCount; ++j )
{
arrDis[i][j] = myGraph.arrArcs[i][j];
}
}
floyd( arrDis, arrPath, myGraph.nVertexCount );
//////////////////////////////////////////////////////////////////////////
printResult( arrDis, arrPath, myGraph.nVertexCount );
//////////////////////////////////////////////////////////////////////////
system( "pause" );
return 0;
}
如图:

相关推荐
-
常用的C语言排序算法(两种)
1. 要求输入10个整数,从大到小排序输出 输入:2 0 3 -4 8 9 5 1 7 6 输出:9 8 7 6 5 3 2 1 0 -4 解决方法:选择排序法 实现代码如下: #include <stdio.h> int main(int argc, const char * argv[]) { int num[10],i,j,k,l,temp; //用一个数组保存输入的数据 for(i=0;i<=9;i++) { scanf("%d",&num[i]);
-
常用排序算法的C语言版实现示例整理
所谓排序,就是要整理文件中的记录,使之按关键字递增(或递减)次序排列起来.其确切定义如下: 输入:n个记录R1,R2,-,Rn,其相应的关键字分别为K1,K2,-,Kn. 输出:Ril,Ri2,-,Rin,使得Ki1≤Ki2≤-≤Kin.(或Ki1≥Ki2≥-≥Kin). 排序的时间开销可用算法执行中的数据比较次数与数据移动次数来衡量.基本的排序算法有如下几种:交换排序(冒泡排序.快速排序).选择排序(直接选择排序.堆排序).插入排序(直接插入排序.希尔排序).归并排序.分配排序(基数排
-

贪心算法的C语言实现与运用详解
贪心算法 所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择.也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解. 贪心算法不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题他能产生整体最优解或者是整体最优解的近似解.贪心算法的基本思路如下: 1.建立数学模型来描述问题. 2.把求解的问题分成若干个子问题. 3.对每一子问题求解,得到子问题的局部最优解. 4.把子问题的解局部最优解合成原来解问题的一个解. 实现该算法的过程: 从问题的某一初始解出发:
-
常用Hash算法(C语言的简单实现)
如下所示: #include "GeneralHashFunctions.h" unsigned int RSHash(char* str, unsigned int len) { unsigned int b = 378551; unsigned int a = 63689; unsigned int hash = 0; unsigned int i = 0; for(i = 0; i < len; str++, i++) { hash = hash * a + (*str);
-
C语言对堆排序一个算法思路和实现代码
算法思想简单描述: 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义如下:具有n个元素的序列(h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1)(i=1,2,...,n/2)时称之为堆.在这里只讨论满足前者条件的堆. 由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项.完全二叉树可以很直观地表示堆的结构.堆顶为根,其它为左子树.右子树. 初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的
-
floyd算法实现思路及实例代码
正如我们所知道的,Floyd算法用于求最短路径.Floyd算法可以说是Warshall算法的扩展,三个for循环就可以解决问题,所以它的时间复杂度为O(n^3). Floyd算法的基本思想如下:从任意节点A到任意节点B的最短路径不外乎2种可能,1是直接从A到B,2是从A经过若干个节点X到B.所以,我们假设Dis(AB)为节点A到节点B的最短路径的距离,对于每一个节点X,我们检查Dis(AX) + Dis(XB) < Dis(AB)是否成立,如果成立,证明从A到X再到B的路径比A直接到B的路径短,
-
python实现word文档批量转成自定义格式的excel文档的思路及实例代码
支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符 最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个.而且可能有几十份这样的试题. 而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档.这个如果是手动一个个粘贴到excel表格,那就头大了. 我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内
-
JavaScript实现的Tween算法及缓冲特效实例代码
本文实例讲述了JavaScript实现的Tween算法及缓冲特效.分享给大家供大家参考,具体如下: 这里演示Tween 算法及缓冲特效的JavaScript代码,利用它可以做缓动.弹簧等很多动画效果,怎么利用flash的Tween类的算法,来做js的Tween算法,并利用它做一些简单的缓动效果呢,看懂了本代码你就明白了. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-tween-run-style-codes/ 具体代码如下: <!DOC
-
c# 冒泡排序算法(Bubble Sort) 附实例代码
冒泡排序(Bubble Sort) 冒泡排序算法的运作如下: 1.比较相邻的元素.如果第一个比第二个大,就交换他们两个.2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.在这一点,最后的元素应该会是最大的数.3.针对所有的元素重复以上的步骤,除了最后一个.4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较. 平均时间复杂度 复制代码 代码如下: /// <summary> /// 冒泡排序 /// </summary> /// <param
-
C语言 奇偶排序算法详解及实例代码
C语言奇偶排序算法 奇偶排序,或奇偶换位排序,或砖排序,是一种相对简单的排序算法,最初发明用于有本地互连的并行计算.这是与冒泡排序特点类似的一种比较排序.该算法中,通过比较数组中相邻的(奇-偶)位置数字对,如果该奇偶对是错误的顺序(第一个大于第二个),则交换.下一步重复该操作,但针对所有的(偶-奇)位置数字对.如此交替进行下去. 使用奇偶排序法对一列随机数字进行排序的过程 处理器数组的排序 在并行计算排序中,每个处理器对应处理一个值,并仅有与左右邻居的本地互连.所有处理器可同时与邻居进行比较.交
-
Java实现Floyd算法求最短路径
本文实例为大家分享了Java实现Floyd算法求最短路径的具体代码,供大家参考,具体内容如下 import java.io.FileInputStream; import java.io.FileNotFoundException; import java.util.Scanner; public class TestMainIO { /** * @param args * @throws FileNotFoundException */ public static void main(Stri
-
Java使用异或运算实现简单的加密解密算法实例代码
Java简单的加密解密算法,使用异或运算 实例1: package cn.std.util; import java.nio.charset.Charset; public class DeEnCode { private static final String key0 = "FECOI()*&<MNCXZPKL"; private static final Charset charset = Charset.forName("UTF-8"); pr
-
php回溯算法计算组合总和的实例代码
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在每个组合中只能使用一次. 说明 所有数字(包括目标数)都是正整数. 解集不能包含重复的组合. 实例 输入: candidates = [10,1,2,7,6,1,5], target = 8, 所求解集为: [ [1, 7], [1, 2, 5], [2, 6], [1, 1, 6]] 解题思路 直接参考回溯算法团灭排列/
-
用js实现简单算法的实例代码
一.冒泡排序 var arr1=[3,9,2,7,0,8,4]; for(var i=0;i<arr1.length;i++){ for(var j=i+1;j<arr1.length;j++){ var temp=0; if(arr1[i]>arr1[j]){ temp=arr1[i]; arr1[i]=arr1[j]; arr1[j]=temp; } } } alert(arr1); 二.快速排序 var a=[3,5,0,9,2,7,5]; function quickSort(a
-
Android中关于递归和二分法的算法实例代码
// 1. 实现一个函数,在一个有序整型数组中二分查找出指定的值,找到则返回该值的位置,找不到返回 -1. package demo; public class Mytest { public static void main(String[] args) { int[] arr={1,2,5,9,11,45}; int index=findIndext(arr,0,arr.length-1,12); System.out.println("index="+index); } // 1