Python网络爬虫与信息提取(实例讲解)
课程体系结构:
1、Requests框架:自动爬取HTML页面与自动网络请求提交
2、robots.txt:网络爬虫排除标准
3、BeautifulSoup框架:解析HTML页面
4、Re框架:正则框架,提取页面关键信息
5、Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍
理念:The Website is the API ...
Python语言常用的IDE工具
文本工具类IDE:
IDLE、Notepad++、Sublime Text、Vim & Emacs、Atom、Komodo Edit
集成工具IDE:
PyCharm、Wing、PyDev & Eclipse、Visual Studio、Anaconda & Spyder、Canopy
·IDLE是Python自带的默认的常用的入门级编写工具,它包含交互式文件式两种方式。适用于较短的程序。
·Sublime Text是专为程序员开发的第三方专用编程工具,可以提高编程体验,具有多种编程风格。
·Wing是Wingware公司提供的收费IDE,调试功能丰富,具有版本控制,版本同步功能,适合于多人共同开发。适用于编写大型程序。
·Visual Studio是微软公司维护的,可以通过配置PTVS编写Python,主要以Windows环境为主,调试功能丰富。
·Eclipse是一款开源的IDE开发工具,可以通过配置PyDev来编写Python,但是配置过程复杂,需要有一定的开发经验。
·PyCharm分为社区版和专业版,社区版免费,具有简单、集成度高的特点,适用于编写较复杂的工程。
适用于科学计算、数据分析的IDE:
·Canopy是由Enthought公司维护的收费工具,支持近500个第三方库,适合科学计算领域应用开发。
·Anaconda是开源免费的,支持近800个第三方库。
Requests库入门
Requests的安装:
Requests库是目前公认的爬取网页最好的Python第三方库,具有简单、简捷的特点。
官方网站:http://www.python-requests.org
在"C:\Windows\System32"中找到"cmd.exe",使用管理员身份运行,在命令行中输入:“pip install requests”运行。
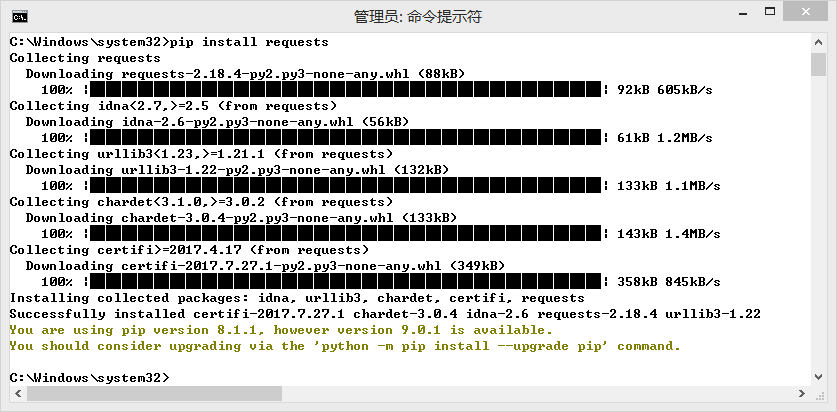
使用IDLE测试Requests库:
>>> import requests
>>> r = requests.get("http://www.baidu.com")#抓取百度页面
>>> r.status_code
>>> r.encoding = 'utf-8'
>>> r.text
Requests库的7个主要方法
| 方法 | 说明 |
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELET |
详细信息参考 Requests库 API文档:http://www.python-requests.org/en/master/api/
get()方法
r = requests.get(url)
get()方法构造一个向服务器请求资源的Request对象,返回一个包含服务器资源的Response对象。
requests.get(url, params=None, **kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问参数
Requests库的2个重要对象
· Request
· Response:Response对象包含爬虫返回的内容
Response对象的属性
r.status_code :HTTP请求的返回状态,200表示连接成功,404表示失败
r.text :HTTP响应内容的字符串形式,即,url对应的页面内容
r.encoding : 从HTTP header中猜测的相应内容编码方式
r.apparent_encoding : 从内容中分析出的相应内容编码方式(备选编码方式)
r.content : HTTP响应内容的二进制形式
r.encoding :如果header中不存在charset,则认为编码为ISO-8859-1 。
r.apparent_encoding :根据网页内容分析出的编码方式可以 看作是r.encoding的备选。
Response的编码:
r.encoding : 从HTTP header中猜测的响应内容的编码方式;如果header中不存在charset,则认为编码为ISO-8859-1,r.text根据r.encoding显示网页内容
r.apparent_encoding : 根据网页内容分析出的编码方式,可以看作r.encoding的备选
爬取网页的通用代码框架
Requests库的异常
| 异常 | 说明 |
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.ToolManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,尝试超时异常 |
Response的异常
r.raise_for_status() : 如果不是200,产生异常requests.HTTPError;
在方法内部判断r.status_code是否等于200,不需要增加额外的if语句,该语句便于利用try-except进行异常处理
import requests def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() # 如果状态不是200,引发HTTPError异常 r.encoding = r.apparent_encoding return r.text except: return "产生异常" if __name__ == "__main__": url = "http://www.baidu.com" print(getHTMLText(url))
通用代码框架,可以使用户爬取网页变得更有效,更稳定、可靠。
HTTP协议
HTTP,Hypertext Transfer Protocol,超文本传输协议。
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP协议采用URL作为定位网络资源的标识。
URL格式:http://host[:port][path]
· host:合法的Internet主机域名或IP地址
· port:端口号,缺省端口号为80
· path:请求资源的路径
HTTP URL的理解:
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源的操作
| 方法 | 说明 |
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
理解PATCH和PUT的区别
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段。
需求:用户修改了UserName,其他不变。
· 采用PATCH,仅向URL提交UserName的局部更新请求。
· 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除。
PATCH的主要好处:节省网络带宽
Requests库主要方法解析
requests.request(method, url, **kwargs)
· method:请求方式,对应get/put/post等7种
例: r = requests.request('OPTIONS', url, **kwargs)
· url:拟获取页面的url链接
· **kwargs:控制访问的参数,共13个,均为可选项
params:字典或字节序列,作为参数增加到url中;
kv = {'key1':'value1', 'key2':'value2'}
r = requests.request('GET', 'http://python123.io/ws',params=kv)
print(r.url)
'''
http://python123.io/ws?key1=value1&key2=value2
'''
data:字典、字节序列或文件对象,作为Request的内容;
json:JSON格式的数据,作为Request的内容;
headers:字典,HTTP定制头;
hd = {'user-agent':'Chrome/10'}
r = requests.request('POST','http://www.yanlei.shop',headers=hd)
cookies:字典或CookieJar,Request中的cookie;
auth:元组,支持HTTP认证功能;
files:字典类型,传输文件;
fs = {'file':open('data.xls', 'rb')}
r = requests.request('POST','http://python123.io/ws',files=fs)
timeout:设定超时时间,秒为单位;
proxies:字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects:True/False,默认为True,重定向开关;
stream:True/False,默认为True,获取内容立即下载开关;
verify:True/False,默认为True,认证SSL证书开关;
cert:本地SSL证书路径
#方法及参数 requests.get(url, params=None, **kwargs) requests.head(url, **kwargs) requests.post(url, data=None, json=None, **kwargs) requests.put(url, data=None, **kwargs) requests.patch(url, data=None, **kwargs) requests.delete(url, **kwargs)

网络爬虫引发的问题
性能骚扰:
受限于编写水平和目的,网络爬虫将会为web服务器带来巨大的资源开销
法律风险:
服务器上的数据有产权归属,网路爬虫获取数据后牟利将带来法律风险。
隐私泄露:
网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。
网络爬虫的限制
·来源审查:判断User-Agent进行限制
检查来访HTTP协议头的User-Agent域,值响应浏览器或友好爬虫的访问。
· 发布公告:Roots协议
告知所有爬虫网站的爬取策咯,要求爬虫遵守。
Robots协议
Robots Exclusion Standard 网络爬虫排除标准
作用:网站告知网络爬虫哪些页面可以抓取,哪些不行。
形式:在网站根目录下的robots.txt文件。
案例:京东的Robots协议
http://www.jd.com/robots.txt
# 注释:*代表所有,/代表根目录 User-agent: * Disallow: /?* Disallow: /pop/*.html Disallow: /pinpai/*.html?* User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow: / User-agent: WochachaSpider Disallow: /
Robots协议的使用
网络爬虫:自动或人工识别robots.txt,再进行内容爬取。

约束性:Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险。
Requests库网络爬虫实战
1、京东商品
import requests
url = "https://item.jd.com/5145492.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
2、亚马逊商品
# 直接爬取亚马逊商品是会被拒绝访问,所以需要添加'user-agent'字段
import requests
url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'} # 使用代理访问
r = requests.get(url, headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(t.text[1000:2000])
except:
print("爬取失败")
3、百度/360搜索关键词提交
搜索引擎关键词提交接口
· 百度的关键词接口:
http://www.baidu.com/s?wd=keyword
· 360的关键词接口:
http://www.so.com/s?q=keyword
# 百度
import requests
keyword = "Python"
try:
kv = {'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
# 360
import requests
keyword = "Python"
try:
kv = {'q':keyword}
r = requests.get("http://www.so.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
4、网络图片的爬取和存储
网络图片链接的格式:
http://www.example.com/picture.jpg
国家地理:
http://www.nationalgeographic.com.cn/
选择一张图片链接:
http://image.nationalgeographic.com.cn/2017/0704/20170704030835566.jpg
图片爬取全代码
import requests
import os
url = "http://image.nationalgeographic.com.cn/2017/0704/20170704030835566.jpg"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
5、IP地址归属地的自动查询
www.ip138.com IP查询
http://ip138.com/ips138.asp?ip=ipaddress
http://m.ip138.com/ip.asp?ip=ipaddress
import requests
url = "http://m.ip138.com/ip.asp?ip="
ip = "220.204.80.112"
try:
r = requests.get(url + ip)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1900:])
except:
print("爬取失败")
# 使用IDLE >>> import requests >>> url ="http://m.ip138.com/ip.asp?ip=" >>> ip = "220.204.80.112" >>> r = requests.get(url + ip) >>> r.status_code >>> r.text
以上这篇Python网络爬虫与信息提取(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
Python3.4编程实现简单抓取爬虫功能示例
本文实例讲述了Python3.4编程实现简单抓取爬虫功能.分享给大家供大家参考,具体如下: import urllib.request import urllib.parse import re import urllib.request,urllib.parse,http.cookiejar import time def getHtml(url): cj=http.cookiejar.CookieJar() opener=urllib.request.build_opener(urllib.
-
Python 爬虫之超链接 url中含有中文出错及解决办法
Python 爬虫之超链接 url中含有中文出错及解决办法 python3.5 爬虫错误: UnicodeEncodeError: 'ascii' codec can't encode characters 这个错误是由于超链接中含有中文引起的,超链接默认是用ascii编码的,所以不能直接出现中文,若要出现中文, 解决方法如下: import urllib from urllib.request import urlopen link="http://list.jd.com/list.html?
-
python爬虫实战之最简单的网页爬虫教程
前言 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.最近对python爬虫有了强烈地兴趣,在此分享自己的学习路径,欢迎大家提出建议.我们相互交流,共同进步.话不多说了,来一起看看详细的介绍: 1.开发工具 笔者使用的工具是sublime text3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷.推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你. sublime text3
-
Python探索之爬取电商售卖信息代码示例
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 下面有一个示例代码,分享给大家: #! /usr/bin/env python # encoding = 'utf-8'# Filename: spider_58center_sth.py from bs4 import BeautifulSoup import time import requests url_58 = 'http://nj.58.c
-
Python开发中爬虫使用代理proxy抓取网页的方法示例
本文实例讲述了Python开发中爬虫使用代理proxy抓取网页的方法.分享给大家供大家参考,具体如下: 代理类型(proxy):透明代理 匿名代理 混淆代理和高匿代理. 这里写一些python爬虫使用代理的知识, 还有一个代理池的类. 方便大家应对工作中各种复杂的抓取问题. urllib 模块使用代理 urllib/urllib2使用代理比较麻烦, 需要先构建一个ProxyHandler的类, 随后将该类用于构建网页打开的opener的类,再在request中安装该opener. 代理格式是"h
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
Python网络爬虫中的同步与异步示例详解
一.同步与异步 #同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> <-e_url-> <-f_url-> <-g_url-> <-h_url-> <--i_ur
-
Python 网络爬虫--关于简单的模拟登录实例讲解
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号.密码等等. 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存) 2.将信息进行提交 3.获取登录后的信息 先给上源码 <span style="font-size: 14px;"># -*- coding: utf-8 -*- import requests def login(): sessi
-
Python网络爬虫实例讲解
聊一聊Python与网络爬虫. 1.爬虫的定义 爬虫:自动抓取互联网数据的程序. 2.爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出. 3.爬虫的时序图 4.URL管理器 URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取.URL管理器的主要职能如下图
-
python爬虫筛选工作实例讲解
我们在选择一件商品的时候,会先了解一些相关的商品信息,根据自己的需求和情况再进行选择.这种现象也同样适用于找工作,筛选一个岗位的重要环节,就是看自身是否符合工作经验的要求.不过因为信息量比较大,有没有什么方法可以用python爬虫中的知识点帮我们解决一下呢~具体内容往下看: 根据工作经验年限,划分招聘等级 # 校正拉勾网工作年限描述,以 Boss直聘描述为准 def update_lagou_workyear(): items = db.jobs_lagou_php.find({}) for i
-
python网络爬虫学习笔记(1)
本文实例为大家分享了python网络爬虫的笔记,供大家参考,具体内容如下 (一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2.Beautiful Soup 模块使用Python编写,速度慢. 安装: pip install beautifulsoup4 3. Lxml 模块使用C语言编写,即快速又健壮,通常应该是最好的选择. (二) Lxml安装 pip install lxml 如果使用lxml的css选择器,还要安装下面的
-
对Python 网络设备巡检脚本的实例讲解
1.基本信息 我公司之前采用的是人工巡检,但奈何有大量网络设备,往往巡检需要花掉一上午(还是手速快的话),浪费时间浪费生命. 这段时间正好在学 Python ,于是乎想(其)要(实)解(就)放(是)双(懒)手. 好了,脚本很长又比较挫,有耐心就看看吧. 需要巡检的设备如下: 设备清单 设备型号 防火墙 华为 E8000E H3C M9006 飞塔 FG3950B 交换机 华为 S9306 H3C S12508 Cisco N7K 路由器 华为 NE40E 负载 Radware RD5412 Ra
-
Python创建简单的神经网络实例讲解
在过去的几十年里,机器学习对世界产生了巨大的影响,而且它的普及程度似乎在不断增长.最近,越来越多的人已经熟悉了机器学习的子领域,如神经网络,这是由人类大脑启发的网络.在本文中,将介绍用于一个简单神经网络的 Python 代码,该神经网络对于一个 1x3 向量,分类第一个元素是否为 10. 步骤1: 导入 NumPy. Scikit-learn 和 Matplotlib import numpy as np from sklearn.preprocessing import MinMaxScale
-
python网络爬虫精解之XPath的使用说明
目录 一.XPath的介绍 二.XPath使用 1.选取所有节点 2.获取子节点 3.获取父节点 4.属性匹配 5.文本获取 6.属性获取 7.属性多值匹配 8.多属性匹配 9.按序选择 10.节点轴选择 XPath的使用 一.XPath的介绍 XPath的几个常用规则: 表达式 描述 nodename 选取此节点的所有子节点 / 从当前节点选取直接子节点 // 从当前节点选取子孙节点 . 选取当前节点 - 选取当前节点的父节点 @ 选取属性 二.XPath使用 1.选取所有节点 test01.
-
python网络爬虫精解之Beautiful Soup的使用说明
目录 一.Beautiful Soup的介绍 二.Beautiful Soup的使用 1.节点选择器 2.提取信息 3.关联选择 4.方法选择器 5.CSS选择器 一.Beautiful Soup的介绍 Beautiful Soup是一个强大的解析工具,它借助网页结构和属性等特性来解析网页. 它提供一些函数来处理导航.搜索.修改分析树等功能,Beautiful Soup不需要考虑文档的编码格式.Beautiful Soup在解析时实际上需要依赖解析器,常用的解析器是lxml. 二.Beautif