C 标准I/O库的粗略实现教程
写一下fopen/getc/putc等C库的粗略实现,参考了K&R,但是有几点根据自己理解的小改动,下面再具体说一下^_^
写这篇文章主要是帮助自己理解下标准I/O库大体是怎么工作的。
fopen与open之间的关系
操作系统提供的接口即为系统调用。而C语言为了让用户更加方便的编程,自己封装了一些函数,组成了C库。而且不同的操作系统对同一个功能提供的系统调用可能不同,在不同的操作系统上C库对用户屏蔽了这些不同,所谓一次编译处处运行。这里open为系统调用,fopen为C库提供的调用。

C库对的读写操作封装了一个缓冲区。试想假如用户频繁的对文件读写少量字符,会频繁的进行系统调用(read函数),而系统调用比较耗时。C库自己封装了一个缓冲区,每次读取特定数据量到缓冲区,读取时优先从缓冲区读取,当缓冲区内容被读光后才进行系统调用将缓冲区再次填满。
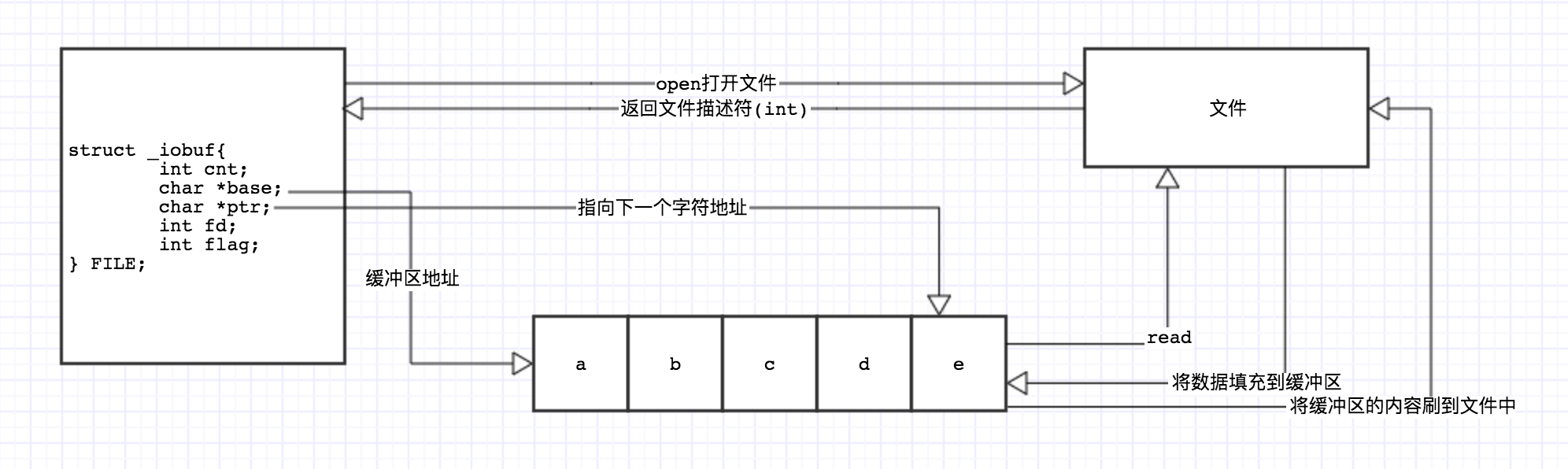
FILE结构体
上面我们看到一个结构体,里面有5个参数,分别记录了:缓冲区剩余的字符数cnt、下一个字符的位置ptr、缓冲区的位置base、文件访问模式flag、文件描述符fd。
其中文件描述符就是系统调用open返回的文件描述符fd,是int类型。ptr与base上面图中已经展示了。cnt是缓冲区剩余字符数,当cnt为0时,会系统调用read来填满缓冲区。flag为文件访问模式,记录了文件打开方式、是否到达文件结尾等。
结构体的具体定义如下,对应调用fopen返回的文件指针FILE *fp = fopen(xxx,r):
typedef struct _iobuf{
int cnt; //缓冲区剩余字节数
char *base; //缓冲区地址
char *ptr; //缓冲区下一个字符地址
int fd; //文件描述符
int flag; //访问模式
} FILE; //别名,与标准库一致
结构体中有flag字段,flag字段可以是以下几种的并集:
enum _flags {
_READ = 1,
_WRITE = 2,
_UNBUF = 4, //不进行缓冲
_EOF = 8,
_ERR = 16
};
我们注意到其中有一个字段,标识不进行缓冲,说明此种情况下每一次读取和输出都调用系统函数。一个例子就是标准错误流stderr : 当stderr连接的是终端设备时,写入一个字符就立即在终端设备显示。
而stdin和stdout都是带缓冲的,明确的说是行缓冲。本文不考虑行缓冲,默认都是全缓冲,即缓冲区满了才刷新缓冲区。(详细可以参考《UNIX环境高级编程》标准I/O库章节)。
现在我们可以初始化stdin、stdout与stderr:
FILE _iob[OPEN_MAX] = {
{0,NULL,NULL,_READ,0},
{0,NULL,NULL,_WRITE,1},
{0,NULL,NULL,_WRITE|_UNBUF,2}
};
_ferror/_feof/_fileno
//判断文件流中是否有错误发生
int _ferror(FILE *f){
return f-> flag & _ERR;
}
//判断文件流是否到达文件尾
int _feof(FILE *f){
return f-> flag & _EOF;
}
//返回文件句柄,即open函数的返回值
int _fileno(FILE *f){
return f->fd;
}
_fopen
FILE *_fopen(char *file,char *mode){
int fd;
FILE *fp;
if(*mode != 'r' && *mode != 'w' && *mode != 'a') {
return NULL;
}
for(fp = _iob; fp < _iob + OPEN_MAX; fp++) { //寻找一个空闲位置
if (fp->flag == 0){
break;
}
}
if(fp >= _iob + OPEN_MAX){
return NULL;
}
if(*mode == 'w'){
fd = creat(file,PERMS);
}else if(*mode == 'r'){
fd = open(file,O_RDONLY,0);
}else{ //a模式
if((fd = open(file,O_WRONLY,0)) == -1){
fd = creat(file,PERMS);
}
lseek(fd,0L,2); //文件指针指向末尾
}
if(fd == -1){
return NULL;
}
fp->fd = fd;
fp->cnt = 0; //fopen不分配缓存空间
fp->base = NULL;
fp->ptr = NULL;
fp->flag = *mode == 'r' ? _READ : _WRITE;
return fp;
}
fopen的处理过程:
判断打开模式的合法性。
在_iob中寻找一个空闲位置,找不到的话说明程序打开的文件数已经到达的最大值,不能再打开新的文件。
如果是w模式,创建一个新文件。如果是r模式,以只读方式打开文件。如果是a模式,首先打开文件,如果打开失败则创建文件,否则通过系统调用lseek将文件指针置到末尾。
对FILE结构体进行初始化,注意fopen不会分配缓冲区。
_getc
getc的作用是从文件中返回下一个字符,参数是文件指针,即FILE:
int _getc(FILE *f){
return --f->cnt >= 0 ? *f->ptr++ : _fillbuf(f);
}
对照上面的图示:当缓冲区中还有剩余字符待读取时,读取该字符并返回,并将缓冲区指针向后移动一个char单位,否则就调用_fillbuf函数填满缓冲区,_fillbuf的返回值就是待读取的字符。
这里有一个问题:当读取到最后一个字符时,cnt为0,但是ptr已经越界了,如下图:

这种情况虽然是非法的,但是C语言中保证:数组末尾之后的第一个元素(即&arr[n],或者arr + n)的指针算术运算可以正确执行。下面的例子也是上述的一种应用场景:
int a[10] = {1,2,3,4,5,6,7,8,9,10};
for(int *x = a;x < a + 10; x++){
printf("%d\n",*x);
}
当for循环到最后一步时,x也指向了a[10],虽然是非法的,但是C语言保证可以正确执行,只要不出现如下情况就ok:
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int *x;
for(x = a;x < a + 10; x++){
printf("%d\n",*x);
}
*x = 11; //越界进行值访问
_fillbuf
我们看下_getc中的_fillbuf的实现,_fillbuf是当缓冲区没有可以读取的字符时,通过系统调用read读取一定字节的数据填满缓冲区,供之后使用:
int _fillbuf(FILE *f){
int bufsize;
if((f->flag & (_READ | _EOF | _ERR)) != _READ){ //判断文件是否可读
return EOF;
}
bufsize = f->flag & _UNBUF ? 1 : BUFSIZ;
if(f->base == NULL){ //没有分配过缓冲区
if((f->base = (char *)malloc(bufsize)) == NULL){
return EOF;
}
}
f->ptr = f->base;
int n = read(f->fd,f->ptr,BUFSIZ); //系统调用read
if(n == 0){ //到达文件结尾
f->base = NULL;
f->cnt = 0;
f-> flag |= _EOF;
return EOF;
}else if(n == -1){ //出错
f->cnt= 0;
f->flag |= _ERR;
return EOF;
}else{
f->cnt = --n;
return *f->ptr++;
}
}
_fillbuf的处理过程:
判断文件是否可读
判断调用read函数时应该读取的字节数,当文件设置了无缓冲时,读取1个字节,否则读取BUFSIZ个字节,BUFSIZ在
判断是否分配过缓冲区(fopen不会分配缓冲区,会再第一次调用getc时分配)。
调用系统函数read。
判断read返回值,分为到达文件结尾、出错和正常读取三种情况。
正常情况下返回缓冲区第一个字符给getc函数,并将cnt减1。
这里注意,到达文件结尾和出错都是返回EOF,区别是前者会将flag的_EOF位置1,后者会将flag的_ERR位置1,上游可以通过feof和ferror函数进行判断(这两个函数在上面已经实现过了)。
The character read is returned as an int value. If the End-of-File is reached or a reading error happens, the function returns EOF and the corresponding error or eof indicator is set. You can use either ferror or feof to determine whether an error happened or the End-Of-File was reached.
_putc
int _putc(int x,FILE *f){
return --f->cnt >= 0 ? *f->ptr++ = x : _flushbuf(x,f);
}
与_getc的实现相似,将写入的字符放到ptr指向的位置,并将ptr向后移动一位。当缓冲区满时,调用_flushbuf将缓冲区内容刷新到文件中。
_flushbuf
int _flushbuf(int x,FILE *f){
if((f->flag & (_WRITE | _EOF | _ERR)) != _WRITE){ //判断文件是否可写
return EOF;
}
int n;
int bufsize = f->flag & _UNBUF ? 1 : BUFSIZ;
if(f->base != NULL){
n = write(f->fd,f->base,f->ptr - f->base); //判断需要写入多少字节
if(n != f->ptr - f->base){
f->flag |= _ERR;
return EOF;
}
}else{
if((f->base = (char *)malloc(bufsize)) == NULL){
f->flag |= _ERR;
return EOF;
}
}
if(x != EOF){
f->cnt = bufsize - 1;
f->ptr = f->base;
*f->ptr++ = x;
}else{ //当写入EOF时,代表强制刷新缓冲区内容到文件中
f->cnt = bufsize;
f->ptr = f->base;
}
return x;
}
_flushbuf的处理过程:
判断文件是否可写。
当已分配过缓冲区时,将缓冲区的内容通过系统调用write写入文件中。
当没有分配过缓冲区时,分配缓冲区。
判断当写入的字符为EOF时,说明调用此函数的目的为强制刷新缓冲区,不写入字符。将cnt赋值为BUFSIZ,ptr赋值为缓冲区首地址base。
当写入字符不为EOF时,说明缓冲区已满,需要将缓冲区刷新到文件中。cnt为BUFSIZE - 1,将写入的字符x放到到缓冲区的第一格,然后将ptr向后移动一个char单位。
注意,调用write函数时,写入的字节数不能写死为1或者BUFSIZ:
n = write(f->fd,f->base,f->ptr - f->base); //判断需要写入多少字节

如上图,我们需要写入base至ptr之间的数据,而不是BUFSIZ,因为我们可能会强制刷新缓冲区而不是等到缓冲区满了才刷新缓冲区。
还有一点:当我们想要强制刷新缓冲区时,第一个参数x该传入什么呢?K&R传递的是字符0,但是我认为这样会污染缓冲区,所以我的实现是传入一个特殊字符EOF,根据EOF来做不同的处理:
if(x != EOF){
f->cnt = bufsize - 1;
f->ptr = f->base;
*f->ptr++ = x;
}else{ //当写入EOF时,代表强制刷新缓冲区内容到文件中
f->cnt = bufsize;
f->ptr = f->base;
}
当缓冲区满时,刷新缓冲区后缓冲区的表现:

当强制刷新缓冲区时,缓冲区的表现:

但是按照K&R的方式来强制刷新缓冲区时,缓冲区的表现:

这样会污染缓冲区,所以我的实现是传入EOF来强制刷新缓冲区。
_fflush
_fflush(FILE *f)的作用是把缓冲区内容写入文件。当参数为空时,会刷新所有文件:
int _fflush(FILE *f){
int res = 0;
if(f == NULL){
for(int i = 0; i < OPEN_MAX; i++){ //当参数为NULL时,刷新所有的文件流
if((f->flag & _WRITE) && (_fflush(&_iob[i]) == -1)){ //有一个出错即返回-1
res = EOF;
}
}
}else{
if(f->flag & _WRITE){
_flushbuf(EOF,f);
}else{
res = EOF;
}
}
if(f->flag & _ERR){ //出错
res = EOF;
}
return res;
}
_fflush的处理过程:
判断参数是否为空,如果为空的话,遍历_iob数组,将所有文件流都强制刷新。
如果参数不为空,判断文件是否可写,再调用_flushbuf进行刷新,注意此处传递给_flushbuf的参数是EOF。还有一点就是判断_flushbuf是否出错不是判断返回值是否为-1,因为参数为EOF时的返回值也为-1,所以此处用flag & _ERR判断是否出错。
注意,这里我们只针对可写的文件流进行操作,忽略了只读的文件流:
If the stream was open for reading, the behavior depends on the specific implementation. In some implementations this causes the input buffer to be cleared.
针对只读的文件流,不同系统处理的方式不一样,有的系统会清空缓冲区。
_fclose
int _fclose(FILE *f){
int ret;
if((ret = _fflush(f)) != EOF){
free(f->base);
f->base = NULL;
f->ptr = NULL;
f->fd = 0;
f->flag = 0;
f->cnt=0;
}
return 0;
}
fclose调用fflush函数,保证在文件关闭前将缓冲区中的内容刷到文件中,并且释放掉缓冲区的内存空间。
_fseek
关于fseek的介绍请看fseek
int _fseek(FILE *f,long offset,int origin){
int rc;
if(f->flag & _READ) {
if(origin == 1) {
offset -= f->cnt;
}
rc = lseek(f->fd,offset,origin);
f->cnt = 0; //将缓冲区剩余字符数清0
}else if(f->flag & _WRITE) {
rc = _fflush(f); //强制刷新缓冲区
if(rc != EOF) {
rc = lseek(f->fd,offset,origin);
}
}
return rc == -1 ? EOF : 0;
}
int _fseek(FILE *f,long offset,int origin){
int rc;
if(f->flag & _READ) {
if(origin == 1) {
offset -= f->cnt;
}
rc = lseek(f->fd,offset,origin);
f->cnt = 0; //将缓冲区剩余字符数清0
}else if(f->flag & _WRITE) {
rc = _fflush(f); //强制刷新缓冲区
if(rc != EOF) {
rc = lseek(f->fd,offset,origin);
}
}
return rc == -1 ? EOF : 0;
}
当文件流为可读时,见下图:
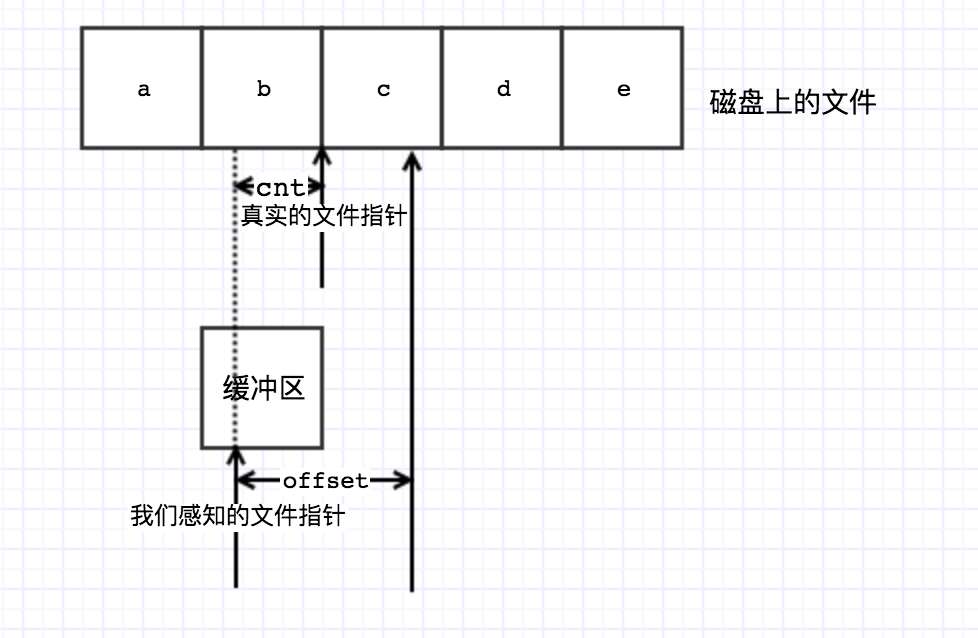
由于有缓冲区的存在,我们直觉上的文件指针位置和真实的文件指针位置是不同的,差了cnt个单位长度。所以当我们设置移动offset个长度时,真实的文件指针需要移动offset-cnt个单位长度(offset为正数或者负数)。
之后我们需要将cnt置为0,以便下次读取时将缓冲区的数据更新。
当origin为0或者2时,直接调动lseek即可。
而当文件流为可写时,见下图:

真实的文件指针位置与我们直觉上的文件指针位置差了ptr - base个单位长度,即我们新写入缓冲区的内容长度,所以我们直接调用_fflush即可。(K&R中直接调用的write,但是我觉得这样没有重置ptr指针的位置和cnt,这样的话base与ptr之间的内容会被刷入到文件中两次)。
当文件是以a模式打开时,fseek无效:
a+ Open for reading and appending (writing at end of file). The file is created if it does not exist. The initial file position for reading is at the beginning of the file, but output is always appended to the end of the file.
_getchar
int _getchar(){
return _getc(stdin);
}
我们可以发现,_getchar调用的就是_getc,只不过_getc可以传入任意的文件指针,而对_getchar来说,_getc传入的是stdin,也就是{0,NULL,NULL,_READ,0}。

当调用getchar时,首先去stdin结构体中的缓存取数据,如果缓存为空,会在_fillbuf中的int n = read(f->fd,f->ptr,BUFSIZ); //系统调用read处阻塞住,等待用户输入字符。
当标准输入(stdin)连接的是终端时,终端I/O会采用规范模式输入处理:对于终端输入以行为单位进行处理,对于每个读请求,终端设备输入队列会返回一行(用户输入的字符会缓存在终端输入队列中,直到用户输入一个行定界符,输入队列中的数据会返回给read函数)。
这一行数据会缓存在标准I/O缓冲区中,下次调用getchar时会返回缓冲区第一个字符。当缓冲区数据被读光时,重复上述过程。
_putchar
int _putchar(int x){
return _putc(x,stdout);
}
我们可以发现,_putchar调用的就是_putc,只不过_putc可以传入任意的文件指针,而对_putchar来说,_putc传入的是stdout,也就是{0,NULL,NULL,_WRITE,1}。

调用putchar时,数据会缓存在stdout中的缓冲中。
当stdout的缓冲被装满时,会调用write将数据写入到stdout中,stdout将数据写入到终端设备输出队列中,输出队列将数据写入到终端。
完整代码
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#define EOF -1
#define BUFSIZ 1024
#define OPEN_MAX 20 //打开的最大文件数
#define PERMS 0666
typedef struct _iobuf{
int cnt; //缓冲区剩余字节数
char *base; //缓冲区地址
char *ptr; //缓冲区下一个字符地址
int flag; //访问模式
int fd; //文件描述符
} FILE; //别名,与标准库一致
extern FILE _iob[OPEN_MAX];
//八进制
enum _flags {
_READ = 01,
_WRITE = 02,
_UNBUF = 04, //不进行缓冲
_EOF = 010,
_ERR = 020
};
FILE _iob[OPEN_MAX] = {
{0,NULL,NULL,_READ,STDIN_FILENO},
{0,NULL,NULL,_WRITE,STDOUT_FILENO},
{0,NULL,NULL,_WRITE|_UNBUF,STDERR_FILENO}
};
#define stdin (&_iob[0])
#define stdout (&_iob[1])
#define stderr (&_iob[2])
int _ferror(FILE *f){
return f-> flag & _ERR;
}
int _feof(FILE *f){
return f-> flag & _EOF;
}
int _fileno(FILE *f){
return f->fd;
}
//返回第一个字符
int _fillbuf(FILE *f){
int bufsize;
if((f->flag & (_READ | _EOF | _ERR)) != _READ){ //判断文件是否可读
return EOF;
}
bufsize = f->flag & _UNBUF ? 1 : BUFSIZ;
if(f->base == NULL){ //没有分配过缓冲区
if((f->base = (char *)malloc(bufsize)) == NULL){
return EOF;
}
}
f->ptr = f->base;
int n = read(f->fd,f->ptr,BUFSIZ); //系统调用read
if(n == 0){ //到达文件结尾
f->base = NULL;
f->cnt = 0;
f-> flag |= _EOF;
return EOF;
}else if(n == -1){ //出错
f->cnt= 0;
f->flag |= _ERR;
return EOF;
}else{
f->cnt = --n;
return *f->ptr++;
}
}
int _flushbuf(int x,FILE *f){
if((f->flag & (_WRITE | _EOF | _ERR)) != _WRITE){
return EOF;
}
int n;
int bufsize = f->flag & _UNBUF ? 1 : BUFSIZ;
if(f->base != NULL){
n = write(f->fd,f->base,f->ptr - f->base); //判断需要写入多少字节
if(n != f->ptr - f->base){
f->flag |= _ERR;
return EOF;
}
}else{
if((f->base = (char *)malloc(bufsize)) == NULL){
f->flag |= _ERR;
return EOF;
}
}
if(x != EOF){
f->cnt = bufsize - 1;
f->ptr = f->base;
*f->ptr++ = x;
}else{ //当写入EOF时,代表强制刷新缓冲区内容到文件中
f->cnt = bufsize;
f->ptr = f->base;
}
return x;
}
/**
* @brief _fflush
* @param f
* @return
*/
int _fflush(FILE *f){
int res = 0;
if(f == NULL){
for(int i = 0; i < OPEN_MAX; i++){ //当参数为NULL时,刷新所有的文件流
if((f->flag & _WRITE) && (_fflush(&_iob[i]) == -1)){ //有一个出错即返回-1
res = EOF;
}
}
}else{
if(f->flag & _WRITE){
_flushbuf(EOF,f);
}else{
res = EOF;
}
}
if(f->flag & _ERR){ //出错
res = EOF;
}
return res;
}
int _fclose(FILE *f){
int ret;
if((ret = _fflush(f)) != EOF){
free(f->base);
f->base = NULL;
f->ptr = NULL;
f->fd = 0;
f->flag = 0; //@TODO
}
return 0;
}
int _fseek(FILE *f,long offset,int origin){
int rc;
if(f->flag & _READ) {
if(origin == 1) {
offset -= f->cnt;
}
rc = lseek(f->fd,offset,origin);
f->cnt = 0; //将缓冲区剩余字符数清0
}else if(f->flag & _WRITE) {
rc = _fflush(f); //强制刷新缓冲区
if(rc != EOF) {
rc = lseek(f->fd,offset,origin);
}
}
return rc == -1 ? EOF : 0;
}
int _getc(FILE *f){
return --f->cnt >= 0 ? *f->ptr++ : _fillbuf(f);
}
int _putc(int x,FILE *f){
return --f->cnt >= 0 ? *f->ptr++ = x : _flushbuf(x,f);
}
int _getchar(){
return _getc(stdin);
}
int _putchar(int x){
return _putc(x,stdout);
}
FILE *_fopen(char *file,char *mode){
int fd;
FILE *fp;
if(*mode != 'r' && *mode != 'w' && *mode != 'a') {
return NULL;
}
for(fp = _iob; fp < _iob + OPEN_MAX; fp++) { //寻找一个空闲位置
if (fp->flag == 0){
break;
}
}
if(fp >= _iob + OPEN_MAX){
return NULL;
}
if(*mode == 'w'){
fd = creat(file,PERMS);
}else if(*mode == 'r'){
fd = open(file,O_RDONLY,0);
}else{ //a模式
if((fd = open(file,O_WRONLY,0)) == -1){
fd = creat(file,PERMS);
}
lseek(fd,0L,2); //文件指针指向末尾
}
if(fd == -1){
return NULL;
}
fp->fd = fd;
fp->cnt = 0; //fopen不分配缓存空间
fp->base = NULL;
fp->ptr = NULL;
fp->flag = *mode == 'r' ? _READ : _WRITE;
return fp;
}
int main(int argc,char *argv[]){
FILE *f = _fopen("zyc.txt","a");
/*char c;
for(int i = 0; i < 10; i++){
c = _getc(f);
}*/
/*for(int i = 0; i < 9; i++){
_putc('6',f);
}
_fseek(f,-5,1);
for(int i = 0; i < 9; i++){
_putc('8',f);
}
_fclose(f);*/
int c;
while((c = _getchar()) != '\n'){
_putchar(c);
}
_fclose(stdout);
return 0;
}
上面提到的部分函数在Answer to Exercise 8-3, page 179中有更详细的实现。
以上这篇C 标准I/O库的粗略实现教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
C 标准I/O库的粗略实现教程
写一下fopen/getc/putc等C库的粗略实现,参考了K&R,但是有几点根据自己理解的小改动,下面再具体说一下^_^ 写这篇文章主要是帮助自己理解下标准I/O库大体是怎么工作的. fopen与open之间的关系 操作系统提供的接口即为系统调用.而C语言为了让用户更加方便的编程,自己封装了一些函数,组成了C库.而且不同的操作系统对同一个功能提供的系统调用可能不同,在不同的操作系统上C库对用户屏蔽了这些不同,所谓一次编译处处运行.这里open为系统调用,fopen为C库提供的调用. C库对的读
-

VS2010 boost标准库开发环境安装教程
分享VS2010 boost标准库开发环境安装教程 1. BOOST编译过程非常复杂,目前为了学习BOOST,首先搭建基于VS2010的BOOST开发环境. Boost库是一个可移植.提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一.Boost库由C++标准委员会库工作组成员发起,其中有些内容有望成为下一代C++标准库内容.在C++社区中影响甚大,是不折不扣的"准"标准库.Boost由于其对跨平台的强调,对标准C++的强调,与编写平台无关.大部分boost库功能
-
C++11标准库bind函数应用教程
目录 bind 是什么? 举个栗子 1. bind 无参数的普通函数 2. bind 1个参数的普通函数 3. bind 多个参数的普通函数 4. bind 多个参数的普通函数并打乱参数位置 5. bind 类的成员函数 再举个应用栗子 bind 是什么? bind 顾名思义: 绑定 通俗来讲呢,可以这么理解有点像函数指针的意思. 资料上是这么讲的:可以将 bind 函数看做一个通用函数的适配器,它接受一个可调用对象,生成一个新的可以调用对象来"适应"原对象参数列表 它一般调用形式:
-
python中turtle库的简单使用教程
python的turtle库的简单使用 Python的turtle库是一个直观有趣的图形绘制函数库,是python的标准库之一. 一.绘图坐标体系 turtle库绘制图形的基本框架:通过一个小海龟在坐标系中的爬行轨迹绘制图形,小海龟的初始位置在画布中央. turtle.setup(width,height,startx,starty) 1.width,height:为主窗体的宽和高 2.startx,starty:为窗口距离左侧与屏幕左侧像素距离和窗口顶部与屏幕顶部的像素距离. import t
-
Python爬虫库urllib的使用教程详解
目录 Python urllib库 urllib.request模块 urlopen函数 Request 类 urllib.error模块 URLError 示例 HTTPError示例 URLError和HTTPError混合使用 urllib.parse模块 urlparse() urlunparse() urlsplit() urljoin() URL 转码 编码quote(string) 编码urlencode() 解码 unquote(string) urllib.robotparse
-
github版本库使用详细图文教程(命令行及图形界面版)
Git是一个分布式的版本控制系统,作为开源代码库以及版本控制系统,Github目前拥有140多万开发者用户.随着越来越多的应用程序转移到了云上,Github已经成为了管理软件开发以及发现已有代码的首选方法. > Git是一个分布式的版本控制系统,最初由Linus Torvalds编写,用作Linux内核代码的管理.在推出后,Git在其它项目中也取得了很大成功,尤其是在Ruby社区中.目前,包括 Rubinius和Merb在内的很多知名项目都使用了Git.Git同样可以被诸如Capistrano和
-
atom-design(Vue.js移动端组件库)手势组件使用教程
介绍 atom-design经过几个月的开发,以及这段时间的修复bug,对js,css压缩,按需引入处理等等的性能优化,现在已经逐渐完善.做这套UI考虑到很多性能的问题,以及如何让开发者更自由.更简单的去使用.这篇文章主要讲使用Gesture(手势)相关组件的感受. Gesture(手势)相关组件 •Carousel(传送带) •SlideItem (滑动条) •Range (区域选择) •Pull Gesture (上下拉动手势) Carousel(传送带) import {Carousel}
-
Visual Studio 2019 DLL动态库连接实例(图文教程)
由于第一次使用Visual Studio 2019建立动态链接库,也是给自己留个操作笔记.如有雷同,纯属巧合! 建立动态库 1.建立一个动态库项目 建立名称为mydll的动态链接库项目 项目建立完成后出现下面的项目结构 其中pch.h声明用的头文件,具体函数代码在pch.cpp文件中.dllmain.cpp和framework.h文件分别为动态链接库的入口和默认加载头文件,可以不用管.直接使用自动生成的代码即可. 2.首先是在pch.h的头文件中声明要加入的函数 extern "C"
-
Python Selenium库的基本使用教程
(一)Selenium基础 入门教程:Selenium官网教程 1.Selenium简介 Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome.Firefox.Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器. 2.支持多种操作系统 如Windows.Linux.IOS.Android等. 3.安装Selenium pip install Selenium 4.安装浏览器驱动 Selenium3.x调用浏览器必须有一个webdriver驱动文件
-
python pillow库的基础使用教程
知识点 图像模块 (Image.Image) Image模块的功能 Image模块的方法 ImageChops模块 ImageColor模块 基础使用 图像模块 Image.Image 加载图像对象,旋转90度并显示 from PIL import Image #显示图像 im = Image.open('background.jpg') im.show() # 转换图像90度 im.rotate(90).show() 创建缩略图 128x128 from PIL import Image im