java8中NIO缓冲区(Buffer)的数据存储详解
java8新特性NIO缓冲区(Buffer)的数据存储。
ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatBuffer,
DoubleBuffer.
1、缓冲区在java nio中负责数据的存储。缓冲区就是数组。用于存储不同数据类型的数据。根据数据类型不同(boolean除外),提供了相应类型的缓冲区。
ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatBuffer,
DoubleBuffer.
上述缓冲区的管理方式几乎一致,通过allocate()获取缓冲区。
//分配一个指定大小的缓冲区ByteBuffer byteBuffer = ByteBuffer.allocate(1024);

2、缓冲区中的四个核心属性:
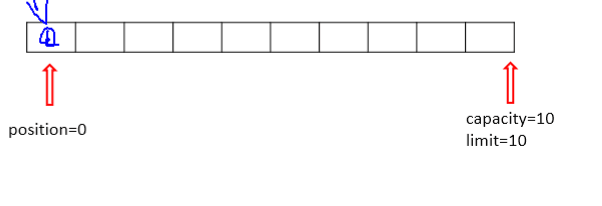
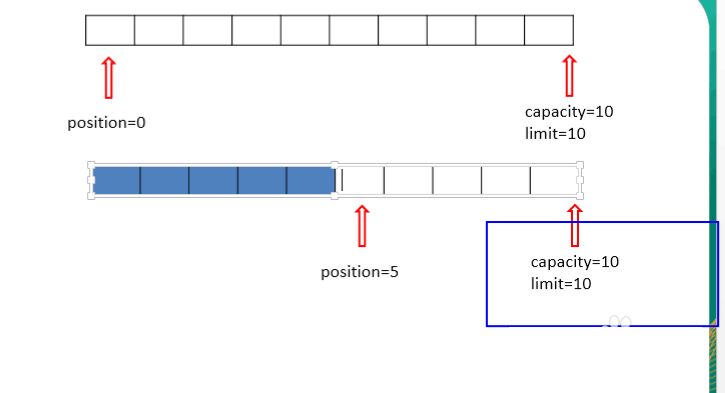
capacity:容量,表示缓冲区中最大存储数据的容量。一旦声明不能改变。
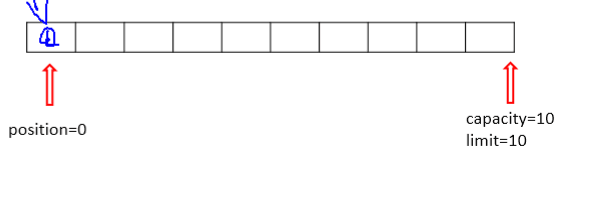
3、limit:界限,表示缓冲区中可以操作数据的大小。(limit后所得数据不能进行读写)。
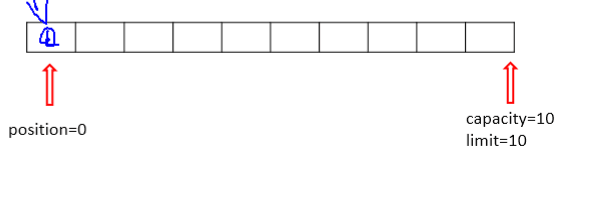
4、position:位置,表示缓冲区中正在操作数据的位置。
position<=limit<=capacity
5、ByteBuffer的基本使用。
缓冲区存取数据的两个核心方法:
put():存入数据到缓冲区
//分配一个指定大小的缓冲区 ByteBuffer byteBuffer = ByteBuffer.allocate(1024); System.out.println(byteBuffer.position()); System.out.println(byteBuffer.limit());; System.out.println(byteBuffer.capacity()); //利用put方法存入数据到缓冲区中 String str = "abcde"; byteBuffer.put(str.getBytes());

6、ByteBuffer的基本使用。
缓冲区存取数据的两个核心方法:
get():获取缓冲区的数据
//4、利用get()读取缓冲区的数据
byte[] dst = new byte[byteBuffer.limit()];
byteBuffer.get(dst);
System.out.println(new String(dst,0,dst.length));
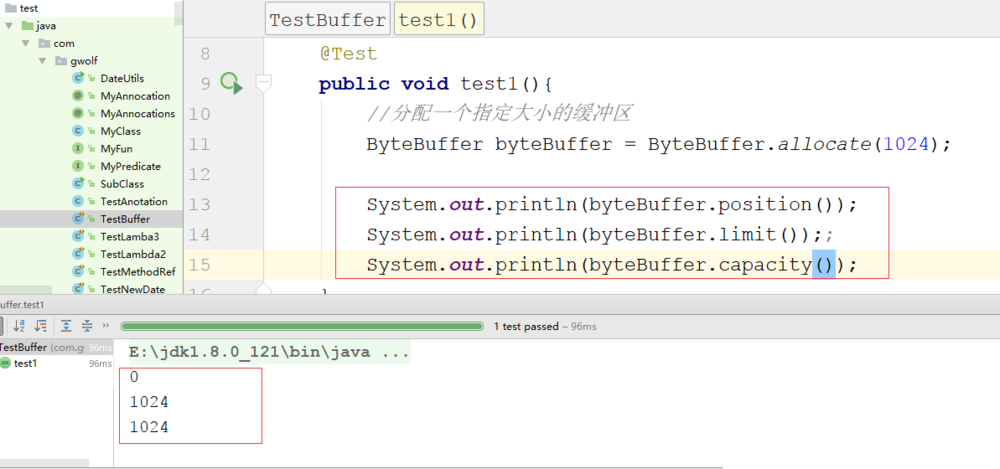
7、调用flip()读数据模式之后
//3、切换成读取数据模式byteBuffer.flip();
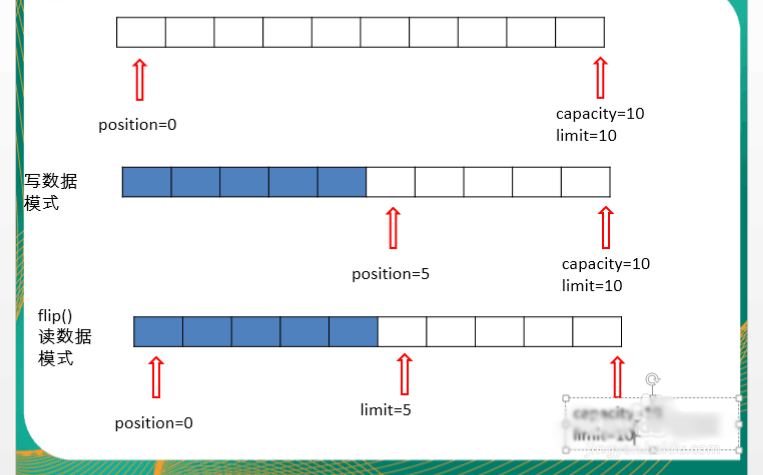

8、调用flip()操作之后:
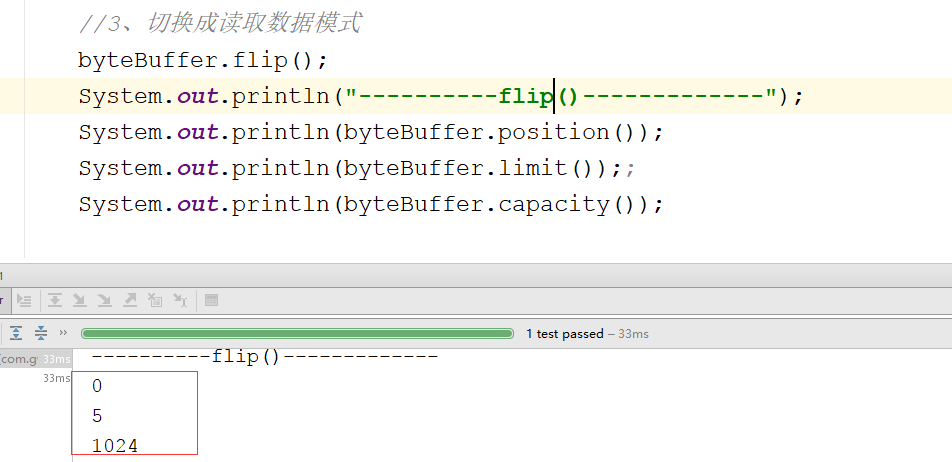
9、rewind()方法:可重复读:
byteBuffer.rewind();
System.out.println("----------rewind()-------------");
System.out.println(byteBuffer.position());
System.out.println(byteBuffer.limit());;
System.out.println(byteBuffer.capacity());

相关推荐
-
Java文件读写IO/NIO及性能比较详细代码及总结
干Java这么久,一直在做WEB相关的项目,一些基础类差不多都已经忘记.经常想得捡起,但总是因为一些原因,不能如愿. 其实不是没有时间,只是有些时候疲于总结,今得空,下定决心将丢掉的都给捡起来. 文件读写是一个在项目中经常遇到的工作,有些时候是因为维护,有些时候是新功能开发.我们的任务总是很重,工作节奏很快,快到我们不能停下脚步去总结. 文件读写有以下几种常用的方法 1.字节读写(InputStream/OutputStream) 2.字符读取(FileReader/FileWriter) 3.
-

使用java NIO及高速缓冲区写入文件过程解析
这篇文章主要介绍了使用java NIO及高速缓冲区写入文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 byte[] bytes = Files.readAllBytes(Paths.get("E:\\pdf\\aaa\\html\\text.txt").normalize()); String text = IOUtils.toString(bytes); String xml = text.substring(
-
Java NIO和IO的区别
下表总结了Java NIO和IO之间的主要差别,我会更详细地描述表中每部分的差异. 复制代码 代码如下: IO NIO面向流 面向缓冲阻塞IO 非阻塞IO无 选择器 面向流与面向缓冲 Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的. Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方.此外,它不能前后移动流中的数
-
java使用nio2拷贝文件的示例
这个程序只是为了更方便的进行拷贝文件(夹)而创造.1.可以不用新建文件夹,就像windows的复制粘贴一样简单.2.有简单的出错重连机制3.不需要重复拷贝,差异化复制文件.4.拷贝文件夹的时候可以不用复制全路径,只关注需要拷贝的文件夹.5.程序做了简单的必要检查,效率也不算低.6.使用的是7的nio2的新API. 复制代码 代码如下: import java.io.IOException;import java.nio.file.FileVisitResult;import java.nio.f
-
JDK1.7 之java.nio.file.Files 读取文件仅需一行代码实现
JDK1.7中引入了新的文件操作类java.nio.file这个包,其中有个Files类它包含了很多有用的方法来操作文件,比如检查文件是否为隐藏文件,或者是检查文件是否为只读文件.开发者还可以使用Files.readAllBytes(Path)方法把整个文件读入内存,此方法返回一个字节数组,还可以把结果传递给String的构造器,以便创建字符串输出.此方法确保了当读入文件的所有字节内容时,无论是否出现IO异常或其它的未检查异常,资源都会关闭.这意味着在读文件到最后的块内容后,无需关闭文件.要注意
-
浅谈Java中BIO、NIO和AIO的区别和应用场景
最近一直在准备面试,为了使自己的Java水平更上一个档次,拜读了李林峰老师的<Netty权威指南>,了解了Java关于IO的发展和最新的技术,真是受益匪浅,现在把我总结的关于BIO.NIO和AIO的区别和应用场景概述一遍. 在此之前,先弄清几个概念: 1.同步:使用同步IO时,Java自己处理IO读写. 2.异步:使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS,完成后OS通知Java处理(回调). 3.阻塞:使用阻塞IO时,Java调用会一直阻塞到读写完成
-
java8中NIO缓冲区(Buffer)的数据存储详解
java8新特性NIO缓冲区(Buffer)的数据存储. ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatBuffer, DoubleBuffer. 1.缓冲区在java nio中负责数据的存储.缓冲区就是数组.用于存储不同数据类型的数据.根据数据类型不同(boolean除外),提供了相应类型的缓冲区. ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatB
-
IOS 数据存储详解及实例代码
iOS应用数据存储的常用方式 XML属性列表(plist)归档 Preference(偏好设置) NSKeyedArchiver归档(NSCoding) SQLite3 Core Data 1. XML属性列表(plist)归档 每个iOS应用都有自己的应用沙盒(应用沙盒就是文件系统目录),与其他文件系统隔离.应用必须待在自己的沙盒里,其他应用不能访问该沙盒. 应用沙盒结构分析: 应用程序包:包含了所有的资源文件和可执行文件 Documents:保存应用运行时生成的需要持久化的数据,iTunes
-
Java8中Lambda表达式使用和Stream API详解
前言 Java8 的新特性:Lambda表达式.强大的 Stream API.全新时间日期 API.ConcurrentHashMap.MetaSpace.总得来说,Java8 的新特性使 Java 的运行速度更快.代码更少.便于并行.最大化减少空指针异常. 0x00. 前置数据 private List<People> peoples = null; @BeforeEach void before () { peoples = new ArrayList<>(); peoples
-
TS 项目中高效处理接口返回数据方法详解
目录 写在前面 问题 解答 区别 总结 必备高效神器 写在前面 在 TypeScript 项目中,TypeScript 对接口返回数据的处理,是日常项目开发中一个比较棘手的问题. 那我们该如何 高效 的解决这个问题呢? 问题 项目中使用 ts 都会碰到如下场景:从接口请求过来的数据该如何进行处理? const fetchInfo = async (url: string, id: string) => { return $http.get(url, params); } const res =
-
C语言数据存储详解
目录 一.数据类型 二.整型在内存中的存储 1.原码.反码.补码 大小端介绍 三.浮点型在内存中的存储 1.举一个浮点数存储的例子: 2.浮点数存储规则: 总结 一.数据类型 char:字符数字类型.有无符号取决于编译器,大部分编译器有符号(signed char) 而short.int.long都是有符号的. unsigned char c1=255;内存中存放二进制的补码:11111111 都是有效位,没有符号位 char c2=255;结果为-1 同理可推出short.int等 二.整型在
-
Java8中stream和functional interface的配合使用详解
前言 Java 8 提供了一组称为 stream 的 API,用于处理可遍历的流式数据.stream API 的设计,充分融合了函数式编程的理念,极大简化了代码量. 大家其实可以把Stream当成一个高级版本的Iterator.原始版本的Iterator,用户只能一个一个的遍历元素并对其执行某些操作:高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,比如"过滤掉长度大于10的字符串"."获取每个字符串的首字母"等,具体这些操作如何应用到每个元素上,
-
C语言编程数据在内存中的存储详解
目录 变量在计算机中有三种表示方式,原码反码,补码 原码 反码 补码 总结一下 浮点数在内存的储存 C语言中,有几种基本内置类型. int unsigned int signed int char unsigned char signed char long unsigned long signed long float double 在内存中创建变量,会在内存中开辟空间,并为其赋值. int a=10; 在计算机中,所有数据都是以二进制的形式存储在内存中. 变量在计算机中有三种表示方式,原码反
-
C语言数据的存储详解
目录 数据类型的介绍 整形 浮点型 构造类型 指针类型 void空类型 整数在内存中的存储 原反补的介绍 大小端的介绍 面试例题 练习 浮点数在内存中的存储 存储规则讲解 举例 IEEE754的特别规定 案例 float用%d打印的特例讲解 数据类型的介绍 数据类型存在的意义 为变量开辟的空间大小(大小决定了使用范围) 取数据的时候按照什么格式取出(先看大小端,在看数据类型(用来解析二进制数据的方式)) 整形 char unsigned char signed char short unsign
-
Android中的存储详解
目录 1.存储在App内部 2.SD卡外部存储 3.SharedPreferences存储 4.使用SQLite数据库存储 4.1 自己完成一个BaseDao类 4.2 使用Google写的API处理 4.3 事务使用 总结 1.存储在App内部 最简单的一种.在尝试过程中发现,手机中很多文件夹都没有权限读写.我们可以将我们需要写的文件存放到App中的files文件夹中,当然我们有权限在整个App中读写文件 可以通过API获取一个file对象,这里的this就是MainActivity类 //
-
C++中整形与浮点型如何在内存中的存储详解
目录 1 数据类型 1.1 类型的基本归类 2 整形在内存中的存储 2.1 二进制的三种形式 2.2 大小端字的介绍 3 浮点数在内存中的存储 3.1 浮点数存储规则 1 数据类型 前面我们已经知道了基本的内置类型: 类型的意义: 1. 使用这个类型开辟内存空间的大小(大小决定了使用范围). 2. 如何看待内存空间的视角. 1.1 类型的基本归类 整形家族: char unsigned char signed char short unsigned short [int] signed shor