Mysql数据库之索引优化
MySQL凭借着出色的性能、低廉的成本、丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库。虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如“精通MySQL”、“SQL语句优化”、“了解数据库原理”等要求。我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
问题:cpu负载过高,达到36。

现象:通过mysqladmin -uroot -p processlist 查看到大量如下信息:
Sending data select * from `rep_corp_vehicle_online_count` where corp_id = 48 and vehicle_id = 10017543
根据以上的可能是表rep_corp_vehicle_online_count的问题 做出如下测试:
查看表结构:
mysql> desc rep_corp_vehicle_online_count; +-------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | corp_id | int(11) | NO | | NULL | | | vehicle_id | int(11) | NO | | NULL | | | online_day | varchar(20) | NO | | NULL | | | loc_total | int(11) | NO | | NULL | | | create_time | datetime | NO | | NULL | | | update_time | datetime | NO | | NULL | | +-------------+-------------+------+-----+---------+----------------+ 7 rows in set (0.00 sec)
查看索引,只有主键索引:
mysql> show index from rep_corp_vehicle_online_count; +-------------------------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------------------------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | rep_corp_vehicle_online_count | 0 | PRIMARY | 1 | id | A | 1247259 | NULL | NULL | | BTREE | | | +-------------------------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 1 row in set (0.00 sec)
代码执行情况:
mysql>explain select * from rep_corp_vehicle_online_count where corp_id = 79 and vehicle_id = 10016911 and online_day = '2016-03-29'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: rep_corp_vehicle_online_count type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1248495 Extra: Using where 1 row in set (0.00 sec)
表数据分析情况,重复数据很多:
mysql> select count(distinct corp_id) from rep_corp_vehicle_online_count; +-------------------------+ | count(distinct corp_id) | +-------------------------+ | 18 | +-------------------------+ 1 row in set (0.63 sec) mysql> select count(corp_id) from rep_corp_vehicle_online_count; +----------------+ | count(corp_id) | +----------------+ | 1239573 | +----------------+ 1 row in set (0.00 sec) mysql> select count(distinct vehicle_id) from rep_corp_vehicle_online_count; +----------------------------+ | count(distinct vehicle_id) | +----------------------------+ | 2580 | +----------------------------+ 1 row in set (1.03 sec) mysql>explain select count(vehicle_id) from rep_corp_vehicle_online_count; +-------------------+ | count(vehicle_id) | +-------------------+ | 1239911 | +-------------------+ 1 row in set (0.00 sec)
最后处理,创建索引:
mysql> create index r_c_v on rep_corp_vehicle_online_count(corp_id,vehicle_id); Query OK, 1487993 rows affected (6.09 sec) Records: 1487993 Duplicates: 0 Warnings: 0 mysql> show index from rep_corp_vehicle_online_count; +-------------------------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------------------------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | rep_corp_vehicle_online_count | 0 | PRIMARY | 1 | id | A | 1490176 | NULL | NULL | | BTREE | | | | rep_corp_vehicle_online_count | 1 | r_c_v | 1 | corp_id | A | 18 | NULL | NULL | | BTREE | | | | rep_corp_vehicle_online_count | 1 | r_c_v | 2 | vehicle_id | A | 2596 | NULL | NULL | | BTREE | | | +-------------------------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 3 rows in set (0.00 sec)
添加索引过后负载降低到了1.73:
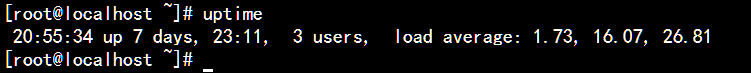
以上内容是小编给大家介绍的Mysql数据库之索引优化 ,希望对大家学习有所帮助!
相关推荐
-
Mysql判断表字段或索引是否存在
判断字段是否存在: DROP PROCEDURE IF EXISTS schema_change; DELIMITER // CREATE PROCEDURE schema_change() BEGIN DECLARE CurrentDatabase VARCHAR(); SELECT DATABASE() INTO CurrentDatabase; IF NOT EXISTS (SELECT * FROM information_schema.columns WHERE table_schem
-
Mysql使用索引实现查询优化
索引的目的在于提高查询效率,可以类比字典,如果要查"mysql"这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的. 1.索引的优点 假设你拥有三个未索引的表t1.t2和t3,每个表都分别包含数据列i1.i2和i3,并且每个表都包含了1000条数据行,其序号从1到1000.查找某些值匹配的数据行组合的查询可能如下所示: SELECT t1.i1, t2.i2, t3.i3 FROM t1, t2,
-
mysql 索引详细介绍
mysql 索引详解: 在mysql 中,索引可以分为两种类型 hash索引和 btree索引. 什么情况下可以用到B树索引? 1.全值匹配索引 比如: orderID="123" 2.匹配最左前缀索引查询 比如:在userid 和 date字段上创建联合索引. 那么如果输入 userId作为条件,那么这个userid可以使用到索引,如果直接输入 date作为条件,那么将不能使用到索引. 3.匹配列前缀查询 比如: order_sn like '134%' 这样可以使用到索引. 4
-

Mysql性能优化案例研究-覆盖索引和SQL_NO_CACHE
场景 产品中有一张图片表pics,数据量将近100万条,有一条相关的查询语句,由于执行频次较高,想针对此语句进行优化 表结构很简单,主要字段: 复制代码 代码如下: user_id 用户ID picname 图片名称 smallimg 小图名称 一个用户会有多条图片记录,现在有一个根据user_id建立的索引:uid,查询语句也很简单:取得某用户的图片集合: 复制代码 代码如下: select picname, smallimg from pics where user_id = xxx; 优化
-
详解mysql建立索引的使用办法及优缺点分析
前言 索引(index)是帮助MySQL高效获取数据的数据结构. 它对于高性能非常关键,但人们通常会忘记或误解它. 索引在数据越大的时候越重要.规模小.负载轻的数据库即使没有索引,也能有好的性能, 但是当数据增加的时候,性能就会下降很快. 为什么要创建索引呢? 这是因为,创建索引可以大大提高系统的性能. 第一.通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性. 第二.可以大大加快数据的检索速度,这也是创建索引的最主要的原因. 第三.可以加速表和表之间的连接,特别是在实现数据的参考完整性方
-
MySQL索引用法实例分析
本文实例分析了MySQL索引用法.分享给大家供大家参考,具体如下: MYSQL描述: 一个文章库,里面有两个表:category和article.category里面有10条分类数据.article里面有20万条.article里面有一个"article_category"字段是与category里的"category_id"字段相对应的.article表里面已经把 article_category字义为了索引.数据库大小为1.3G. 问题描述: 执行一个很普通的查
-
Mysql性能优化案例 - 覆盖索引分享
场景 产品中有一张图片表,数据量将近100万条,有一条相关的查询语句,由于执行频次较高,想针对此语句进行优化 表结构很简单,主要字段: 复制代码 代码如下: user_id 用户ID picname 图片名称 smallimg 小图名称 一个用户会有多条图片记录 现在有一个根据user_id建立的索引:uid 查询语句也很简单:取得某用户的图片集合 复制代码 代码如下: select picname, smallimg from pics where user_id = xxx; 优化前 执行查
-
mysql索引必须了解的几个重要问题
本文讲述了mysql索引必须了解的几个重要问题.分享给大家供大家参考,具体如下: 1.索引是做什么的? 索引用于快速找出在某个列中有一特定值的行.不使用索引,MySQL必须从第1条记录开始然后读完整个表直到找出相关的行. 表越大,花费的时间越多.如果表中查询的列有一个索引,MySQL能快速到达一个位置去搜寻到数据文件的中间,没有必要看所有数据. 大多数MySQL索引(PRIMARY KEY.UNIQUE.INDEX和FULLTEXT)在B树中存储.只是空间列类型的索引使用R-树,并且MEMORY
-
Mysql数据库之索引优化
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓"好马配好鞍",如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如"精通MySQL"."SQL语句优化"."了解数据库原理"等要求.我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,
-
MySQL数据库的索引原理与慢SQL优化的5大原则
我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重. 本文旨在以开发工程师的角度来解释数据库索引的原理和如何优化慢查询. MySQL索引原理 1.索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我
-
MySQL数据库查询性能优化策略
优化查询 使用Explain语句分析查询语句 Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句. 通过对查询语句的分析,可以了解查询语句的执行情况,找出查询语句执行的瓶颈,从而优化查询语句. 使用索引查询 MySql中提高性能的一个最有效的方式就是对数据表设计合理的索引. 索引提供了高效访问数据的方法,并且加快查询速度. 如果查询时没有使用索引,那么查询语句将扫描表中所有的记录.在数据量大的时候,这样查询速度会很慢. 使用索引进行查询,查
-
mysql数据库之索引详细介绍
目录 思维导图 简单理解 索引模型的演变 二叉查找树 自平衡二叉树 B树 B+树 聚集索引与二级索引 总结 如果你想深入了解为什么mysql可以快速的进行检索数据,那么你一定要来了解一下mysql的索引原理 思维导图 简单理解 你可以把索引理解为一本书的目录,我们可以通过索引快速的找到我们需要的数据,大概就像下面这个图,索引就像是右边的二叉树,每个节点指向具体的数据的物理地址,先通过二叉树找到数据的位置,然后再去物理磁盘中获取数据. 但是不同的二叉树的特性不同,我们还要选择合适的树来作为索引,所
-
MySQL数据库查询性能优化的4个技巧干货
目录 前言 SQL的执行频率 慢查询日志 show profiles详情分析 explain执行计划 1.ID参数 2.select_type参数 3.type参数 前言 MySQL性能优化是一个老生常谈的问题,无论是在实际工作中还是面试中,都不可避免遇到相应的场景,下面博主就总结一些能够帮助大家解决这个问题的小技巧. SQL优化之前需要确认哪些SQL需要优化,这时就需要引起SQL性能分析工具,主要优化的是查询语句. SQL的执行频率 SQL性能优化一般是针对查询语句,所以在定位是否需要优化之前
-
MYSQL数据库表结构优化方法详解
本文实例讲述了MYSQL数据库表结构优化方法.分享给大家供大家参考,具体如下: 选择合适的数据类型 1.使用可以存下你的数据的最小的数据类型 2.使用简单的数据类型.Int要比varchar类型在mysql处理上简单 3.尽可能的使用not null定义字段 4.尽量少用text类型,非用不可时最好考虑分表 使用int来存储日期时间,利用FROM_UNIXTIME()[将int类型时间戳转换成日期时间格式],UNIX_TIMESTAMP()[将日期时间格式转换成int类型]两个函数进行转换 使用
-
MySQL数据库之索引详解
目录 一.MySQL索引简介 二.MySQL五种类型索引详解 (一)普通索引 (二)唯一性索引 (三)主键索引 (四)复合索引 (五)全文索引 三.MySQL索引使用原则 总结 今天继续给大家介绍MySQL相关知识,本文主要内容是MySQL索引相关内容. 一.MySQL索引简介 索引是MySQL数据库为了加快数据查询的速度,给表中的某一个或者是某几个列添加的一种"目录".MySQL的索引是一个特殊的文件,但是InnoDB类型引擎(关于MySQL的引擎我们会在今后的文章中进行讲解)的表的
-
MySQL Order By索引优化方法
尽管 ORDER BY 不是和索引的顺序准确匹配,索引还是可以被用到,只要不用的索引部分和所有的额外的 ORDER BY 字段在 WHERE 子句中都被包括了. 使用索引的MySQL Order By 下列的几个查询都会使用索引来解决 ORDER BY 或 GROUP BY 部分: 复制代码 代码如下: SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1=constant ORD
-
MySQL数据库的性能优化
目录 一.MySQL数据库的优化目标.基本原则: 1.优化目标: 2.基本原则: 二.定位分析SQL语句的性能瓶颈: 1.通过show status 命令了解各种SQL的执行效率: 2.定位执行效率较低的SQL语句 3.通过explain分析慢SQL的执行计划 4.通过show profile 分析SQL的具体耗时瓶颈 三.数据库的优化方法: 一.MySQL数据库的优化目标.基本原则: 1.优化目标: MySQL数据库是常见的两个瓶颈是CPU和I/O的瓶颈,无论是索引优化.还是表结构优化,参数优
-
MySQL数据库十大优化技巧
1.优化你的MySQL查询缓存 在MySQL服务器上进行查询,可以启用高速查询缓存.让数据库引擎在后台悄悄的处理是提高性能的最有效方法之一.当同一个查询被执行多次时,如果结果是从缓存中提取,那是相当快的. 但主要的问题是,它是那么容易被隐藏起来以至于我们大多数程序员会忽略它.在有些处理任务中,我们实际上是可以阻止查询缓存工作的. 复制代码 代码如下: // query cache does NOT work $r = mysql_query("SELECT username FROM user