常用Oracle分析函数大全
Oracle的分析函数功能非常强大,工作这些年来经常用到。这次将平时经常使用到的分析函数整理出来,以备日后查看。
我们拿案例来学习,这样理解起来更容易一些。
1、建表
create table earnings -- 打工赚钱表 ( earnmonth varchar2(6), -- 打工月份 area varchar2(20), -- 打工地区 sno varchar2(10), -- 打工者编号 sname varchar2(20), -- 打工者姓名 times int, -- 本月打工次数 singleincome number(10,2), -- 每次赚多少钱 personincome number(10,2) -- 当月总收入 )
2、插入实验数据
insert into earnings values('200912','北平','511601','大魁',11,30,11*30);
insert into earnings values('200912','北平','511602','大凯',8,25,8*25);
insert into earnings values('200912','北平','511603','小东',30,6.25,30*6.25);
insert into earnings values('200912','北平','511604','大亮',16,8.25,16*8.25);
insert into earnings values('200912','北平','511605','贱敬',30,11,30*11);
insert into earnings values('200912','金陵','511301','小玉',15,12.25,15*12.25);
insert into earnings values('200912','金陵','511302','小凡',27,16.67,27*16.67);
insert into earnings values('200912','金陵','511303','小妮',7,33.33,7*33.33);
insert into earnings values('200912','金陵','511304','小俐',0,18,0);
insert into earnings values('200912','金陵','511305','雪儿',11,9.88,11*9.88);
insert into earnings values('201001','北平','511601','大魁',0,30,0);
insert into earnings values('201001','北平','511602','大凯',14,25,14*25);
insert into earnings values('201001','北平','511603','小东',19,6.25,19*6.25);
insert into earnings values('201001','北平','511604','大亮',7,8.25,7*8.25);
insert into earnings values('201001','北平','511605','贱敬',21,11,21*11);
insert into earnings values('201001','金陵','511301','小玉',6,12.25,6*12.25);
insert into earnings values('201001','金陵','511302','小凡',17,16.67,17*16.67);
insert into earnings values('201001','金陵','511303','小妮',27,33.33,27*33.33);
insert into earnings values('201001','金陵','511304','小俐',16,18,16*18);
insert into earnings values('201001','金陵','511305','雪儿',11,9.88,11*9.88);
commit;
3、查看实验数据
select * from earnings;
查询结果如下
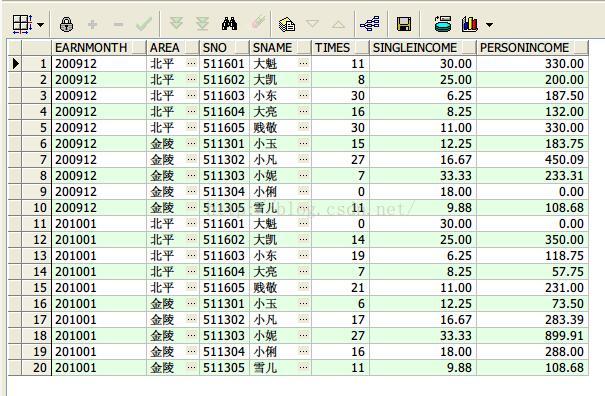
4、sum函数按照月份,统计每个地区的总收入
select earnmonth, area, sum(personincome) from earnings group by earnmonth,area;
查询结果如下
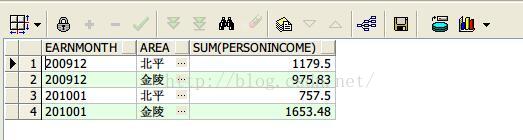
5、rollup函数按照月份,地区统计收入
select earnmonth, area, sum(personincome) from earnings group by rollup(earnmonth,area);
查询结果如下
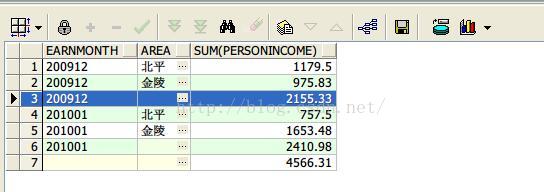
6、cube函数按照月份,地区进行收入汇总
select earnmonth, area, sum(personincome) from earnings group by cube(earnmonth,area) order by earnmonth,area nulls last;
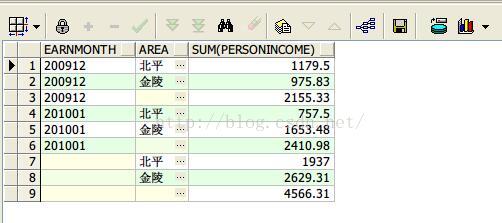
查询结果如下
小结:sum是统计求和的函数。
group by 是分组函数,按照earnmonth和area先后次序分组。
以上三例都是先按照earnmonth分组,在earnmonth内部再按area分组,并在area组内统计personincome总合。
group by 后面什么也不接就是直接分组。
group by 后面接 rollup 是在纯粹的 group by 分组上再加上对earnmonth的汇总统计。
group by 后面接 cube 是对earnmonth汇总统计基础上对area再统计。
另外那个 nulls last 是把空值放在最后。
rollup和cube区别:
如果是ROLLUP(A, B, C)的话,GROUP BY顺序
(A、B、C)
(A、B)
(A)
最后对全表进行GROUP BY操作。
如果是GROUP BY CUBE(A, B, C),GROUP BY顺序
(A、B、C)
(A、B)
(A、C)
(A)
(B、C)
(B)
(C)
最后对全表进行GROUP BY操作。
7、grouping函数在以上例子中,是用rollup和cube函数都会对结果集产生null,这时候可用grouping函数来确认
该记录是由哪个字段得出来的
grouping函数用法,带一个参数,参数为字段名,结果是根据该字段得出来的就返回1,反之返回0
select decode(grouping(earnmonth),1,'所有月份',earnmonth) 月份,
decode(grouping(area),1,'全部地区',area) 地区, sum(personincome) 总金额
from earnings
group by cube(earnmonth,area)
order by earnmonth,area nulls last;
查询结果如下

8、rank() over开窗函数
按照月份、地区,求打工收入排序
select earnmonth 月份,area 地区,sname 打工者, personincome 收入,
rank() over (partition by earnmonth,area order by personincome desc) 排名
from earnings;
查询结果如下

9、dense_rank() over开窗函数按照月份、地区,求打工收入排序2
select earnmonth 月份,area 地区,sname 打工者, personincome 收入,
dense_rank() over (partition by earnmonth,area order by personincome desc) 排名
from earnings;
查询结果如下
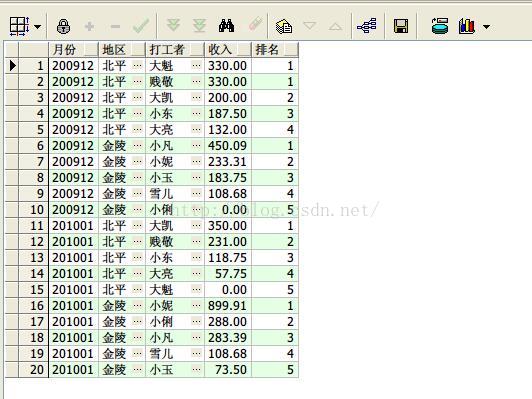
10、row_number() over开窗函数按照月份、地区,求打工收入排序3
select earnmonth 月份,area 地区,sname 打工者, personincome 收入,
row_number() over (partition by earnmonth,area order by personincome desc) 排名
from earnings;
查询结果如下

通过(8)(9)(10)发现rank,dense_rank,row_number的区别:
结果集中如果出现两个相同的数据,那么rank会进行跳跃式的排名,
比如两个第二,那么没有第三接下来就是第四;
但是dense_rank不会跳跃式的排名,两个第二接下来还是第三;
row_number最牛,即使两个数据相同,排名也不一样。
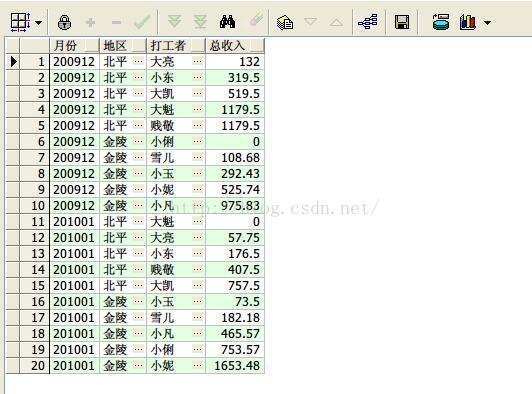
11、sum累计求和根据月份求出各个打工者收入总和,按照收入由少到多排序
select earnmonth 月份,area 地区,sname 打工者,
sum(personincome) over (partition by earnmonth,area order by personincome) 总收入
from earnings;
查询结果如下
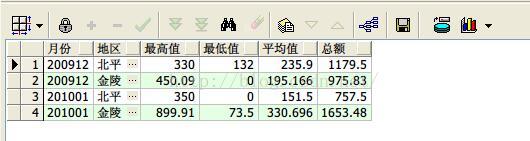
12、max,min,avg和sum函数综合运用按照月份和地区求打工收入最高值,最低值,平均值和总额
select distinct earnmonth 月份, area 地区,
max(personincome) over(partition by earnmonth,area) 最高值,
min(personincome) over(partition by earnmonth,area) 最低值,
avg(personincome) over(partition by earnmonth,area) 平均值,
sum(personincome) over(partition by earnmonth,area) 总额
from earnings;
查询结果如下
13、lag和lead函数求出每个打工者上个月和下个月有没有赚钱(personincome大于零即为赚钱)
select earnmonth 本月,sname 打工者,
lag(decode(nvl(personincome,0),0,'没赚','赚了'),1,0) over(partition by sname order by earnmonth) 上月,
lead(decode(nvl(personincome,0),0,'没赚','赚了'),1,0) over(partition by sname order by earnmonth) 下月
from earnings;
查询结果如下
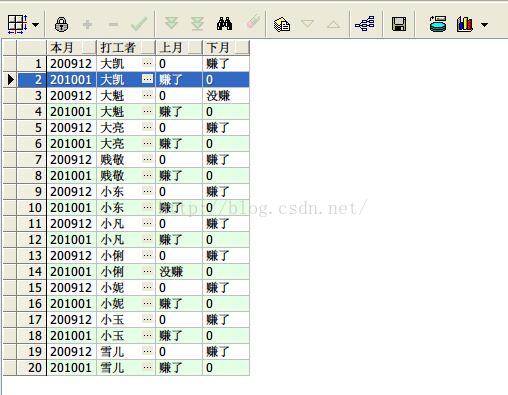
说明:Lag和Lead函数可以在一次查询中取出某个字段的前N行和后N行的数据(可以是其他字段的数据,比如根据字段甲查询上一行或下两行的字段乙)
语法如下:
lag(value_expression [,offset] [,default]) over ([query_partition_clase] order_by_clause);
lead(value_expression [,offset] [,default]) over ([query_partition_clase] order_by_clause);
其中:
value_expression:可以是一个字段或一个内建函数。
offset是正整数,默认为1,指往前或往后几点记录.因组内第一个条记录没有之前的行,最后一行没有之后的行,default就是用于处理这样的信息,默认为空。
再讲讲所谓的开窗函数,依本人遇见,开窗函数就是 over([query_partition_clase] order_by_clause)。比如说,我采用sum求和,rank排序等等,但是我根据什么来呢?over提供一个窗口,可以根据什么什么分组,就用partition by,然后在组内根据什么什么进行内部排序,就用 order by。
以上所述是小编给大家介绍的常用Oracle分析函数大全,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Oracle开发之分析函数(Rank, Dense_rank, row_number)
一.使用rownum为记录排名: 在前面一篇<Oracle开发之分析函数简介Over>,我们认识了分析函数的基本应用,现在我们再来考虑下面几个问题: ①对所有客户按订单总额进行排名 ②按区域和客户订单总额进行排名 ③找出订单总额排名前13位的客户 ④找出订单总额最高.最低的客户 ⑤找出订单总额排名前25%的客户 按照前面第一篇文章的思路,我们只能做到对各个分组的数据进行统计,如果需要排名的话那么只需要简单地加上rownum不就行了吗?事实情况是否如此想象般简单,我们来实践一下. [1]测试环境
-
Oracle开发之分析函数总结
这一篇是对前面所有关于分析函数的文章的总结: 一.统计方面: 复制代码 代码如下: Sum() Over ([Partition by ] [Order by ]) Sum() Over ([Partition by ] [Order by ] Rows Between Preceding And Following) Sum() Over ([Partition by ] [Order by ] Rows Between Preceding An
-
Oracle开发之分析函数(Top/Bottom N、First/Last、NTile)
一.带空值的排列: 在前面<Oracle开发之分析函数(Rank.Dense_rank.row_number)>一文中,我们已经知道了如何为一批记录进行全排列.分组排列.假如被排列的数据中含有空值呢? 复制代码 代码如下: SQL> select region_id, customer_id, sum(customer_sales) cust_sales, sum(sum(customer_sales)) over(partition by regio
-
深入探讨:oracle中row_number() over()分析函数用法
row_number()over(partition by col1 order by col2)表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的). 与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪劣rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码. row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开始排序). rank()是跳跃排序,有两个第二名
-
Oracle开发之分析函数简介Over用法
一.Oracle分析函数简介: 在日常的生产环境中,我们接触得比较多的是OLTP系统(即Online Transaction Process),这些系统的特点是具备实时要求,或者至少说对响应的时间多长有一定的要求:其次这些系统的业务逻辑一般比较复杂,可能需要经过多次的运算.比如我们经常接触到的电子商城. 在这些系统之外,还有一种称之为OLAP的系统(即Online Aanalyse Process),这些系统一般用于系统决策使用.通常和数据仓库.数据分析.数据挖掘等概念联系在一起.这些系统的特点
-
Oracle 分析函数RANK(),ROW_NUMBER(),LAG()等的使用方法
ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序 而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的) RANK() 类似,不过RANK 排序的时候跟派名次一样,可以并列2个第一名之后 是第3名 LAG 表示 分组排序后 ,组内后面一条记录减前面一条记录的差,第一条可返回 NULL BTW: EXPERT ONE ON ONE 上讲的最详细,还有很多相关特性,文档看起来比较费劲 row
-

常用Oracle分析函数大全
Oracle的分析函数功能非常强大,工作这些年来经常用到.这次将平时经常使用到的分析函数整理出来,以备日后查看. 我们拿案例来学习,这样理解起来更容易一些. 1.建表 create table earnings -- 打工赚钱表 ( earnmonth varchar2(6), -- 打工月份 area varchar2(20), -- 打工地区 sno varchar2(10), -- 打工者编号 sname varchar2(20), -- 打工者姓名 times int, -- 本月打工次
-
常用的正则表达式大全(数字、字符、固定格式)
相关阅读: IOS开发常用的正则表达式 Java正则表达式过滤出字母.数字和中文 正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串.将匹配的子串做替换或者从某个串中取出符合某个条件的子串等. 列目录时, dir *.txt或ls *.txt中的*.txt就不是一个正则表达式,因为这里*与正则式的*的含义是不同的. 构造正则表达式的方法和创建数学表达式的方法一样.也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式.
-
JavaScript常用判断写法大全(推荐)
js验证表单大全,用JS控制表单提交,具体内容如下所示: 1. 长度限制 <script> function test() { if(document.a.b.value.length>50) { alert("不能超过50个字符!"); document.a.b.focus(); return false; } } </script> <form name=a onsubmit="return test()"> <t
-
Linux 常用命令操作大全(推荐收藏)
1.系统信息 命令 arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI) hdparm -i /dev/hda 罗列一个磁盘的架构特性 hdparm -tT /dev/sda 在磁盘上执行测试性读取操作 cat /proc/cpuinfo 显示CPU info的信息 cat /proc/interrupts 显示中断 cat /proc/memin
-
IntelliJ IDEA 2020常用配置设置大全(方便干活)
IntelliJ IDEA 安装后需要进行初始化配置已更加方便使用.本文整理了比较通用的安装后初始配置. 本文适配版本:IntelliJ IDEA 2020.1版(于2020年4月9日发布). 本文适配版本:IntelliJ IDEA 2020.2.1版(于2020年8月25日发布). 本文适配版本:IntelliJ IDEA 2020.3版(于2020年12月1日发布). 安装和永久使用的方法,请参阅上篇:IntelliJ IDEA 2020最新激活码(亲测有效,可激活至 2089 年) 最新
-
C++常用字符串函数大全(2)
目录 1.cstring.h常用函数介绍 2.strlen 3.strcat 4.strncat 5.strcpy 6.strncpy 7.memset 8.memcpy 9.strcmp 10.strncmp 11.strstr 1.cstring.h常用函数介绍 cstring.h库即C语言中的string.h库,它是C语言中为字符串提供的标准库.C++对此进行了兼容,所以我们在C++当中一样可以使用. 这个库当中有大量的关于字符串操作的api,本文选择了其中最常用的几个进行阐述. 2.st
-
Oracle分析函数用法详解
一.概述 OLAP的系统(即Online Aanalyse Process)一般用于系统决策使用.通常和数据仓库.数据分析.数据挖掘等概念联系在一起.这些系统的特点是数据量大,对实时响应的要求不高或者根本不关注这方面的要求,以查询.统计操作为主. 我们来看看下面的几个典型例子: ①查找上一年度各个销售区域排名前10的员工 ②按区域查找上一年度订单总额占区域订单总额20%以上的客户 ③查找上一年度销售最差的部门所在的区域 ④查找上一年度销售最好和最差的产品 我们看看上面的几个例子就可以感觉到这几个
-
史上超强最常用SQL语句大全
目录 DDL(Data Definition Language)数据定义语言 一.操作库 二.操作表 一.增加 insert into 二.删除 delete 三.修改 update DQL(Data Query Language)数据查询语言 一.基础关键字 二.排序查询 order by 三. 聚合函数:将一列数据作为一个整体,进行纵向的计算. 四. 分组查询 grout by 五. 分页查询 六.内连接查询: 1.隐式内连接:使用where条件消除无用数据 2.显式内连接 七.外连接查询
-
oracle查询语句大全(oracle 基本命令大全一)
1.create user username identified by password;//建用户名和密码oracle ,oracle 2.grant connect,resource,dba to username;//授权 grant connect,resource,dba,sysdba to username; 3.connect username/password//进入. 4.select table_name,column_name from user_tab_columns
-
github 常用命令总结大全
github常用命令 最近开始研究github,mark下一些常用命令 git remote add upstream https://github.com/winterIce/testTitle.git(别人的repository) // 新建分支用于存放别人的repository git clone https://github.com/winterIce/testTitle.git 克隆到本地 git fetch branch2//更新信息 git merge branch2/ma