Python K最近邻从原理到实现的方法
本来这篇文章是5月份写的,今天修改了一下内容,就成今天发表的了,CSDN这是出BUG了还是什么改规则了。。。
引文:决策树和基于规则的分类器都是积极学习方法(eager learner)的例子,因为一旦训练数据可用,他们就开始学习从输入属性到类标号的映射模型。一个相反的策略是推迟对训练数据的建模,直到需要分类测试样例时再进行。采用这种策略的技术被称为消极学习法(lazy learner)。最近邻分类器就是这样的一种方法。
注:KNN既可以用于分类,也可以用于回归。
1.K最近邻分类器原理
首先给出一张图,根据这张图来理解最近邻分类器,如下:
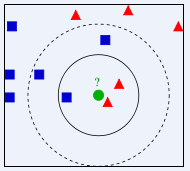
根据上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在, 我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他or她身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。其关键还在于K值的选取,所以应当谨慎。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
前面的例子中强调了选择合适的K值的重要性。如果太小,则最近邻分类器容易受到训练数据的噪声而产生的过分拟合的影响;相反,如果K太大,最近分类器可能会误会分类测试样例,因为最近邻列表中可能包含远离其近邻的数据点。(如下图所示)

K较大时的最近邻分类
可见,K值的选取还是非常关键。
2.算法算法描述
k近邻算法简单、直观:给定一个训练数据集(包括类别标签),对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。下面是knn的算法步骤。
算法步骤如下所示:

对每个测试样例z=(x′,y′),算法计算它和所有训练样例(x,y)属于D之间的距离(如欧氏距离,或相似度),以确定其最近邻列表Dz。如果训练样例的数目很大,那么这种计算的开销就会很大。不过,可以使索引技术降低为测试样例找最近邻是的计算量。
特征空间中两个实例点的距离是两个实例相似程度的反映。
一旦得到最近邻列表,测试样例就可以根据最近邻的多数类进行分类,使用多数表决方法。
K值选择
k值对模型的预测有着直接的影响,如果k值过小,预测结果对邻近的实例点非常敏感。如果邻近的实例恰巧是噪声数据,预测就会出错。也就是说,k值越小就意味着整个模型就变得越复杂,越容易发生过拟合。
相反,如果k值越大,有点是可以减少模型的预测误差,缺点是学习的近似误差会增大。会使得距离实例点较远的点也起作用,致使预测发生错误。同时,k值的增大意味着模型变得越来越简单。如果k=N,那么无论输入实例是什么,都将简单的把它预测为样本中最多的一类。这显然实不可取的。
在实际建模应用中,k值一般取一个较小的数值,通常采用cross-validation的方法来选择最优的k值。
3.K最邻近算法实现(Python)
KNN.py(代码来源《机器学习实战》一书)
from numpy import *
import operator
class KNN:
def createDataset(self):
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
def KnnClassify(self,testX,trainX,labels,K):
[N,M]=trainX.shape
#calculate the distance between testX and other training samples
difference = tile(testX,(N,1)) - trainX # tile for array and repeat for matrix in Python, == repmat in Matlab
difference = difference ** 2 # take pow(difference,2)
distance = difference.sum(1) # take the sum of difference from all dimensions
distance = distance ** 0.5
sortdiffidx = distance.argsort()
# find the k nearest neighbours
vote = {} #create the dictionary
for i in range(K):
ith_label = labels[sortdiffidx[i]];
vote[ith_label] = vote.get(ith_label,0)+1 #get(ith_label,0) : if dictionary 'vote' exist key 'ith_label', return vote[ith_label]; else return 0
sortedvote = sorted(vote.iteritems(),key = lambda x:x[1], reverse = True)
# 'key = lambda x: x[1]' can be substituted by operator.itemgetter(1)
return sortedvote[0][0]
k = KNN() #create KNN object
group,labels = k.createDataset()
cls = k.KnnClassify([0,0],group,labels,3)
print cls
运行:
1. 在Python Shell 中可以运行KNN.py
>>>import os
>>>os.chdir("/home/liudiwei/code/data_miningKNN/")
>>>execfile("KNN.py")
输出:B
(B表示类别)
2.或者terminal中直接运行
$ python KNN.py
3.也可以不在KNN.py中写输出,而选择在Shell中获得结果,i.e.,
>>>import KNN >>> KNN.k.KnnClassify([0,0],KNN.group,KNN.labels,3)
附件(两张自己的计算过程图):
 图
图
1 KNN算法核心部分

图2 KNN计算过程
说明:上述图片仅供参考,看不懂就自己测试一组数据如[0,1]慢慢推导一下吧
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python实现K最近邻算法
KNN核心算法函数,具体内容如下 #! /usr/bin/env python3 # -*- coding: utf-8 -*- # fileName : KNNdistance.py # author : zoujiameng@aliyun.com.cn import math def getMaxLocate(target): # 查找target中最大值的locate maxValue = float("-inFinIty") for i in range(len(target)
-
python机器学习案例教程——K最近邻算法的实现
K最近邻属于一种分类算法,他的解释最容易,近朱者赤,近墨者黑,我们想看一个人是什么样的,看他的朋友是什么样的就可以了.当然其他还牵着到,看哪方面和朋友比较接近(对象特征),怎样才算是跟朋友亲近,一起吃饭还是一起逛街算是亲近(距离函数),根据朋友的优秀不优秀如何评判目标任务优秀不优秀(分类算法),是否不同优秀程度的朋友和不同的接近程度要考虑一下(距离权重),看几个朋友合适(k值),能否以分数的形式表示优秀度(概率分布). K最近邻概念: 它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并
-
Python K最近邻从原理到实现的方法
本来这篇文章是5月份写的,今天修改了一下内容,就成今天发表的了,CSDN这是出BUG了还是什么改规则了... 引文:决策树和基于规则的分类器都是积极学习方法(eager learner)的例子,因为一旦训练数据可用,他们就开始学习从输入属性到类标号的映射模型.一个相反的策略是推迟对训练数据的建模,直到需要分类测试样例时再进行.采用这种策略的技术被称为消极学习法(lazy learner).最近邻分类器就是这样的一种方法. 注:KNN既可以用于分类,也可以用于回归. 1.K最近邻分类器原理 首先给
-
K最近邻算法(KNN)---sklearn+python实现方式
k-近邻算法概述 简单地说,k近邻算法采用测量不同特征值之间的距离方法进行分类. k-近邻算法 优点:精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. k-近邻算法(kNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标
-
Python构建网页爬虫原理分析
既然本篇文章说到的是Python构建网页爬虫原理分析,那么小编先给大家看一下Python中关于爬虫的精选文章: python实现简单爬虫功能的示例 python爬虫实战之最简单的网页爬虫教程 网络爬虫是当今最常用的系统之一.最流行的例子是 Google 使用爬虫从所有网站收集信息.除了搜索引擎之外,新闻网站还需要爬虫来聚合数据源.看来,只要你想聚合大量的信息,你可以考虑使用爬虫. 建立一个网络爬虫有很多因素,特别是当你想扩展系统时.这就是为什么这已经成为最流行的系统设计面试问题之一.在这篇文章中
-
python 图像插值 最近邻、双线性、双三次实例
最近邻: import cv2 import numpy as np def function(img): height,width,channels =img.shape emptyImage=np.zeros((2048,2048,channels),np.uint8) sh=2048/height sw=2048/width for i in range(2048): for j in range(2048): x=int(i/sh) y=int(j/sw) emptyImage[i,j]
-
for循环在Python中的工作原理详细
例如: 作用于列表 >>> for elem in [1,2,3]: ... print(elem) ... 1 2 3 作用于字符串 >>> for c in "abc": ... print(c) ... a b c 作用于字典 >>> for k in {"age":10, "name":"wang"}: ... print(k) ... age name 可能有人不
-

Python地图四色原理的遗传算法着色实现
目录 1 任务需求 2 代码实现 2.1 基本思路 2.3 结果展示 总结 1 任务需求 首先,我们来明确一下本文所需实现的需求. 现有一个由多个小图斑组成的矢量图层,如下图所示:我们需要找到一种由4种颜色组成的配色方案,对该矢量图层各图斑进行着色,使得各相邻小图斑间的颜色不一致,如下下图所示. 在这里,我们用到了四色定理(Four Color Theorem),又称四色地图定理(Four Color Map Theorem):如果在平面上存在一些邻接的有限区域,则至多仅用四种颜色来
-
python机器学习Logistic回归原理推导
目录 前言 Logistic回归原理与推导 sigmoid函数 目标函数 梯度上升法 Logistic回归实践 数据情况 训练算法 算法优缺点 前言 Logistic回归涉及到高等数学,线性代数,概率论,优化问题.本文尽量以最简单易懂的叙述方式,以少讲公式原理,多讲形象化案例为原则,给读者讲懂Logistic回归.如对数学公式过敏,引发不适,后果自负. Logistic回归原理与推导 Logistic回归中虽然有回归的字样,但该算法是一个分类算法,如图所示,有两类数据(红点和绿点)分布如下,如果
-
Python Counting Bloom Filter原理与实现详细介绍
目录 前言 原理 一.BF 为什么不支持删除 二.什么是 Counting Bloom Filter 三.Counter 大小的选择 简单的实现 总结 前言 标准的 Bloom Filter 是一种比较简单的数据结构,只支持插入和查找两种操作.在所要表达的集合是静态集合的时候,标准 Bloom Filter 可以很好地工作,但是如果要表达的集合经常变动,标准Bloom Filter的弊端就显现出来了,因为它不支持删除操作.这就引出来了本文要谈的 Counting Bloom Filter,后文简