Python零基础入门学习之输入与输出
简介
在之前的编程中,我们的信息打印,数据的展示都是在控制台(命令行)直接输出的,信息都是一次性的没有办法复用和保存以便下次查看,今天我们将学习Python的输入输出,解决以上问题。
复习
得到输入用的是input(),完成输出用的是print(),之前还有对字符串的操作,这些我们都可以使用help()命令来查看具体的使用方法。
文件
在Python2的时候使用的是file来创建一个file类,对它进行操作。Python3中去掉了这个类(我没有查到,只是猜测),使用open来打开一个文件,返回一个IO的文本包装类,之后我们使用这个类的方法对它进行操作。
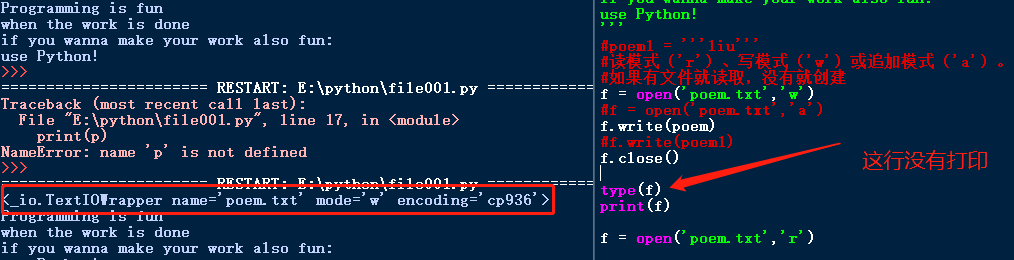
使用文件
poem = '''\
Programming is fun
when the work is done
if you wanna make your work also fun:
use Python!
'''
#poem1 = '''liu'''
#读模式('r')、写模式('w')或追加模式('a')。
#如果有文件就读取,没有就创建
f = open('poem.txt','w')
#f = open('poem.txt','a')
f.write(poem)
#f.write(poem1)
f.close()
type(f)
print(f)
f = open('poem.txt','r')
while True:
line = f.readline()
if len(line) == 0:
break
print(line, end='')
f.close()
运行结果

如何工作
open方法第一个参数是你的文件名和路径,我的文件和程序在同一个文件夹下所以只需要填写文件名即可,第一个参数后面可以跟很多参数来完成不同的操作,而且很多参数是由默认值的,通过我们之前对函数的学习知道这样做的好处。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) ========= =============================================================== Character Meaning --------- --------------------------------------------------------------- 'r' open for reading (default) 'w' open for writing, truncating the file first 'x' create a new file and open it for writing 'a' open for writing, appending to the end of the file if it exists 'b' binary mode 't' text mode (default) '+' open a disk file for updating (reading and writing) 'U' universal newline mode (deprecated) ========= ===============================================================
这个mode参数是主要的参数,大家记住这个就可以,mode参数可以很多个参连在一起使用比如open('text1.txt','wb')这个就是使用二进制写数据,一会就会使用到。
这个文件是不用手动创建的,在你的路径下有这个文件的话,就会打开这个文件,如果没有会自动创建这个文件。
读文件的时候使用的是循环读取,使用包装类的readline()方法,读取每一行,当方法返回0时,表示文件读取完成,破坏循环条件,关闭IO。

自动创建的文件。
储存器
Python中提供了一个pickle模块。通过这个模块你可以在文件中存储任何Python对象,你又可以从这个文件中吧对象取出。这被称为持久的存储对象。还有另一个模块称为cPickle,它的功能和pickle模块完全相同,只不过它是用C语言编写的,因此它的速度要快很多(比pickle快1000倍,Python3中取消使用)。这里将使用Pickle模块。
使用import...as...语法可以用as后的字符代替as前的字符,模块使用起来更简洁。将数据保存到打开的文件中就是存储,open一个文件,调用模块的dump函数,将数据存到文件中。使用模块的load函数返回存储的对象,这个过程叫做取存储。
import pickle as p shoplistfile = 'shoplist.data' shoplist = ['apple','mango','carrot'] f = open(shoplistfile,'wb') #将数据写入打开的文件中 p.dump(shoplist,f) f.close() del shoplist f = open(shoplistfile,'rb') storedlist = p.load(f) print(storedlist) print(__doc__)
运行结果

这里使用的就是二进制的写入,读取的时候也使用的二进制,和写入的数据有关,这个大家多多留意。
Python的输入与输出就写到这里,大家多多探索会有更多的知识等待你发掘。
相关推荐
-
python输入错误密码用户锁定实现方法
小编给大家带来了用python实现用户多次密码输入错误后,用户锁定的实现方式,以及具体的流程,让大家更好的理解运行的过程. 1.新建一个文件,用以存放白名单用户(正确注册的用户 格式:username:password),再建一个文件,用以存放黑名单用户(输入三次用户名均错误的用户). 2.读取白名单文件,将内容赋值给一个变量,并关闭. 3.将变量以" :"分割,分割出得第一位(索引为0)赋值给username,第二位(索引为1)赋值给password. 4.读取黑名单文件,将内容赋值
-
Python输入二维数组方法
前不久对于Python输入二维数组有些不解,今日成功尝试,记以备忘.这里以输入1-9,3*3矩阵为例 n=int(input()) line=[[0]*n]*n for i in range(n): line[i]=input().split(' ') print(line) 使用数据转换为int即可! 以上这篇Python输入二维数组方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 一些Python中的二维数组的操作方法 python中字
-
python输出100以内的质数与合数实例代码
具体代码如下所述: __author__ = 'Yue Qingxuan' # -*- coding: utf-8 -*- #求质数 p=[2] for i in range(2,101): for temp in range(2,i): if i%temp==0: break print('i=',i,'temp=',temp) elif temp==i-1: p.append(i) print('\n以下打印质数:') print(p) #求合数 list=[] for i in range
-
Python输出\u编码将其转换成中文的实例
爬取了下小猪短租的网站出租房信息但是输出的时候是这种: 百度了下.python2.7在window上的编码确实是个坑 解决如下 如果是个字典的话要先将其转成字符串 导入json库 然后 这么输出(json.dumps(data).decode("unicode-escape")) 整个代码demo # -*- coding: UTF-8 -*- #小猪短租爬取 import requests from bs4 import BeautifulSoup import json def g
-
解决nohup重定向python输出到文件不成功的问题
原因是: It looks like you need to flush stdout periodically (e.g. sys.stdout.flush()). In my testing Python doesn't automatically do this even with print until the program exits. You can run Python with the -u flag to avoid output buffering 所以, 解决办法之一:加
-
python输入整条数据分割存入数组的方法
通过手动输入数据,将数据分成几部分存入数组中 import os import sys def test(): brick = raw_input("input:") brick = brick.split(",") print brick test() 输入的数据是用逗号分割开的,所以直接使用"split(",")"拆分. 以上这篇python输入整条数据分割存入数组的方法就是小编分享给大家的全部内容了,希望能给大家一个参考
-
Python零基础入门学习之输入与输出
简介 在之前的编程中,我们的信息打印,数据的展示都是在控制台(命令行)直接输出的,信息都是一次性的没有办法复用和保存以便下次查看,今天我们将学习Python的输入输出,解决以上问题. 复习 得到输入用的是input(),完成输出用的是print(),之前还有对字符串的操作,这些我们都可以使用help()命令来查看具体的使用方法. 文件 在Python2的时候使用的是file来创建一个file类,对它进行操作.Python3中去掉了这个类(我没有查到,只是猜测),使用open来打开一个文件,返回一
-
零基础入门学习——Spring Boot注解(一)
声明bean的注解: @Component组件,没有明确角色的bean @Service,在业务逻辑层(service)中使用 @Repository,在数据访问层(dao)中使用 @Controller,在展现层中使用 @Configuration声明配置类 实体类无需添加注解,因为并不需要"注入"实体类 指定Bean的作用域的注解: @Scope("prototype") 默认值为singleton 可选值prototype.request.session.gl
-

Django零基础入门之自定义过滤器及模板中的使用
目录 引言 自定义过滤器 (1)首先 (2)内置过滤器lower的使用: (3)自定义过滤器的使用: (4)模板中使用自定义过滤器: (5)效果展示: 引言 分析Django内置的模板过滤器: 通过分析可以将内置的过滤器理解为: 一个带有一个或两个参数的python函数: (输入的)变量的值[注意:不一定是字符串形式,在前面也讲过可以是哪些类型.] 参数的值--可以有一个初始值,或者完全没有参数. 自定义过滤器 新建一个名为ceshi的app以供本文学习使用: 自定义过滤器及标签所在的tem
-
Django零基础入门之自定义标签及模板中的使用
目录 自定义标签: 第一部分 (1)视图函数编写: (2)编写模板文件: (3)自定义标签实现: (4)效果展示: 第二部分 (1)视图函数编写: (2)编写模板文件: (3)自定义标签实现: 第三部分 紧接上文--<Django零基础入门之自定义过滤器及模板中的使用>,本文来讲一讲自定义标签!!! 自定义标签: 源码学习: template.Library().simple_tags(): def simple_tag(self, func=None, takes_context=None,
-
Django零基础入门之运行Django版的hello world
目录 1.项目目录及文件说明: 2.项目与应用app的关系: 3.使用django框架编写hello world! 1.项目目录及文件说明: manage.py django中的一个命令行工具,管理django项目: __init__.py 空文件,告诉python这个目录是python报: settings.py 配置文件,包含数据库信息,调试标志,静态文件等: urls.py django项目的URL声明: wsgi.py 部署服务器用到: templates 存放html文件. 2.项目与
-
PyTorch零基础入门之构建模型基础
目录 一.神经网络的构造 二.神经网络中常见的层 2.1 不含模型参数的层 2.2 含模型参数的层 (1)代码栗子1 (2)代码栗子2 2.3 二维卷积层 stride 2.4 池化层 三.LeNet模型栗子 三点提醒: 四.AlexNet模型栗子 Reference 一.神经网络的构造 PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活.Module 类是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型.
-
Python装饰器入门学习教程(九步学习)
装饰器(decorator)是一种高级Python语法.装饰器可以对一个函数.方法或者类进行加工.在Python中,我们有多种方法对函数和类进行加工,比如在Python闭包中,我们见到函数对象作为某一个函数的返回结果.相对于其它方式,装饰器语法简单,代码可读性高.因此,装饰器在Python项目中有广泛的应用. 这是在Python学习小组上介绍的内容,现学现卖.多练习是好的学习方式. 第一步:最简单的函数,准备附加额外功能 # -*- coding:gbk -*- '''示例1: 最简单的函数,表
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
Django零基础入门之调用漂亮的HTML前端页面
引言: Django如何调用HTML前端页面呢? Django怎样去调用漂亮的HTML前端页面呢? 就直接使用render方法即可! render方法是django封装好用来调用HTML前端模板的方法! 1.模板放在哪? 在主目录下创建一个templates目录用来存放所有的html的模板文件.(如果是使用pycharm创建django项目的话,默认就会自动创建这个目录哦!但是用命令创建django项目的话是没有此目录的!) templates目录里面再新建各个以app名字命名的目录来存放
-
Django零基础入门之路由path和re_path详解
目录 urls.py文件中的path和re_path 1.path的基本规则: 2.默认支持的转换器有: 3.re_path正则匹配: Django中实战使用path和re_path 1.urls.py文件: 2.views.py视图函数文件: 3.效果: 假设现在有个需求: 需要通过URL进行参数传递,我们该怎么做呢? 其中有个方法就是本文要讲的内容--path和进阶版的re_path. urls.py文件中的path和re_path 1.path的基本规则: path('test