python数据处理 根据颜色对图片进行分类的方法
前面一篇文章有说过,利用scrapy来爬取图片,是为了对图片数据进行分类而收集数据。
本篇文章就是利用上次爬取的图片数据,根据图片的颜色特征来做一个简单的分类处理。
实现步骤如下:
1:图片路径添加
2:对比度处理
3:滤波处理
4:数据提取以及特征向量化
5:图片分类处理
6:根据处理结果将图片分类保存
代码量中等,还可以更少,只是我为了练习类的使用,而将每个步骤都封装成了一个独立的类,当然里面也有类继承的问题,遇到的问题前面一篇文章有讲解。内容可能有点繁琐,尤其是文件和路径的使用(可以自己修改),已经尽量优化代码了。
爬取的原始数据如下:
直接上代码:
import os
import numpy as np
import skimage
import matplotlib.pyplot as plt
from skimage import io #读取图片
from skimage import exposure #调用调对比度的方法 rescale_intensity、equalize_hist
from skimage.filters import gaussian #高斯
from skimage import img_as_float #图片unit8类型到float
from scipy.cluster.vq import kmeans,vq,whiten #聚类算法
import shutil #文件夹内容删除
class Path(object):
def __init__(self):
self.path = r"D:\PYscrapy\get_lixiaoran\picture"
self.pathlist = [] #原始图片列表
self.page = 0
def append(self): #将每张图片的路径加载到列表中
much = os.listdir(self.path)
for i in range(len(much)):
repath = os.path.join(self.path,str(self.page)+'.jpg')
self.page +=1
self.pathlist.append(repath)
return self.pathlist
class Contrast(object):
def __init__(self,pathlist):
self.pathlist = pathlist
self.contrastlist = [] #改变对比度之后的图片列表
self.path2 = r"D:\PYscrapy\get_lixiaoran\picture2"
self.page2 = 0
def balance(self): #将每张图片进行对比度的处理,两种方式 1:均衡化 2:从某个值开始取极值
if os.path.exists(self.path2) == False:
os.mkdir(self.path2)
# for lis in self.pathlist:
# data = skimage.io.imread(lis)
# equalized = exposure.equalize_hist(data) #方法一这里使用个人人为更好的均衡化处理对比度的方法
# self.contrastlist.append(equalized)
for lis in self.pathlist:
data = skimage.io.imread(lis)
high_contrast = exposure.rescale_intensity(data,in_range=(20,220)) #方法二 以20和220取两端极值
self.contrastlist.append(high_contrast)
for img in self.contrastlist:
repath = os.path.join(self.path2,str(self.page2)+'.jpg') #保存修改后的图片
skimage.io.imsave(repath,img)
self.page2 +=1
class Filter(Contrast):
def __init__(self,pathlist):
super().__init__(pathlist)
self.path31 = self.path2
self.path32 = r"D:\PYscrapy\get_lixiaoran\picture3"
self.page3 = 0
self.filterlist = []
def filte_r(self):
img = os.listdir(self.path31) #读取文件内容
if os.path.exists(self.path32) == False:
os.mkdir(self.path32)
for lis in range(len(img)): #循环做每张图片的高斯过滤
path = os.path.join(self.path31,str(lis)+r'.jpg')
img = skimage.io.imread(path)
gas = gaussian(img,sigma=3) #multichannel=False 去掉颜色2D
self.filterlist.append(gas)
path_gas = os.path.join(self.path32,str(self.page3)+r'.jpg')
skimage.io.imsave(path_gas,gas)
self.page3 +=1
return self.path32
class Vectoring(object):
def __init__(self,filter_path):
self.path41 = filter_path
self.diff = []
self.calculate = []
def vector(self):
numbers = os.listdir(self.path41) #获取文件夹内容
os.chdir(self.path41) #切换路径
for i in range(len(numbers)):
self.diff.append([])
for j in range(4):
self.diff[i].append([]) #diff[[number],[img_float],[bin_centers],[hist]]
for cnt,number in enumerate(numbers):
img_float = img_as_float(skimage.io.imread(number)) #将图像ndarry nint8->float
hist,bin_centers = exposure.histogram(img_float,nbins=10) #取图像的 每个区间的像素值 分隔区间
self.diff[cnt][0] = number
self.diff[cnt][1] = img_float
self.diff[cnt][2] = bin_centers #把数据添加到diff中
self.diff[cnt][3] = hist
for i,j in enumerate(self.diff): #使用hist和bin_centers相乘来降维,向量化
self.calculate.append([y*self.diff[i][3][x] for x,y in enumerate(self.diff[i][2])]) #这里可能需要理解一下,就是涉及的参数有点多
for i in range(len(self.diff)):
self.diff[i].append(self.calculate[i]) #将特征向量calculate也加入到diff中
return self.diff #diff[[number],[img_float],[bin_centers],[hist],[calculate]]
class Modeling(Vectoring):
def __init__(self,filter_path,K):
super().__init__(filter_path)
self.K = K
def model(self):
diff = self.vector()
calculate = []
for i in range(len(diff)):
calculate.append(diff[i][4])
spot = whiten(calculate) #这里使用scipy的k-means方法来对图片进行分类
center,_ = kmeans(spot,self.K) #如果对scipy的k-means不熟悉,前面有专门的讲解
cluster,_ = vq(spot,center)
return diff,cluster #获得预测值
class Predicting(object):
def __init__(self,predicted_diff,predicted_cluster,K):
self.diff = predicted_diff
self.cluster = predicted_cluster
self.path42 = r'D:\PYscrapy\get_lixiaoran\picture4'
self.K = K
def predicted(self):
if os.path.exists(self.path42) == True:
much = shutil.rmtree(self.path42)
os.mkdir(self.path42)
else:
os.mkdir(self.path42)
os.chdir(self.path42)
for i in range(self.K): #创建K个文件夹
os.mkdir('classify{}'.format(i))
for i,j in enumerate(self.cluster):
skimage.io.imsave('classify{}\\{}'.format(j,self.diff[i][0]),self.diff[i][1]) #根据图片的分类来将它们保存至对应的文件夹
if __name__=="__main__":
np.random.seed(10)
#文件路径添加
start = Path()
pathlist = start.append()
#对比度类
second = Contrast(pathlist)
second.balance() #get改变对比度后的图片个数
#高斯过滤
filte = Filter(pathlist)
filter_path = filte.filte_r()
#数据提取及向量化
vectoring = Vectoring(filter_path)
#K值的自定义
K = 3
#建模
modeling = Modeling(filter_path,K)
predicted_diff,predicted_cluster = modeling.model()
#预测
predicted = Predicting(predicted_diff,predicted_cluster,K)
predicted.predicted()
文件如下:

(K=3)分类如下(picrure4):


白色的基本在一类
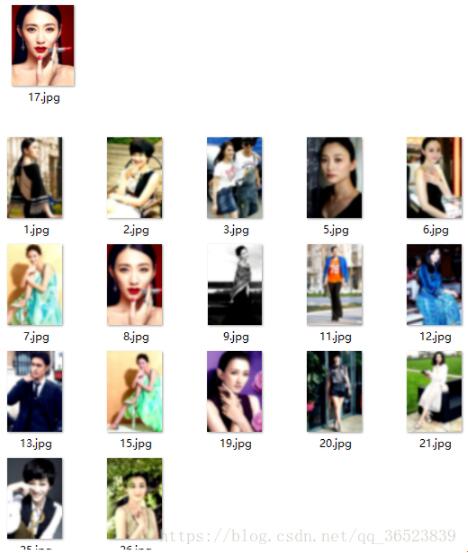
黑色的基本一类
分类出来的图片比较模糊是因为,我分类的是处理过后的图片,并非原图。
其实仔细看效果还是有的,就是确实不是太明显,图片的内容还是有点复杂的。大体的框架已经有了,只是优化的问题,调整优化,以及向量特征化的处理,就能得到更好的结果。或者使用一些更好的处理方式,我这里只是简单的使用了几种常见的图片处理方式,所以效果一般。
这里的类有点多,从上到下是类的顺序,所以一步步看还是不复杂的。如果有什么好的建议可以分享一下。
以上这篇python数据处理 根据颜色对图片进行分类的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python使用PIL模块获取图片像素点的方法
如下所示: from PIL import Image ########获取图片指定像素点的像素 def getPngPix(pngPath = "aa.png",pixelX = 1,pixelY = 1): img_src = Image.open(pngPath) img_src = img_src.convert('RGBA') str_strlist = img_src.load() data = str_strlist[pixelX,pixe
-

Python3实现取图片中特定的像素替换指定的颜色示例
本文实例讲述了Python3实现取图片中特定的像素替换指定的颜色.分享给大家供大家参考,具体如下: 1.原始图片 2.修改脚本: # -*- coding:utf-8 -*- #! python3 from PIL import Image i = 1 j = 1 img = Image.open("e:/pic/222.jpg")#读取系统的内照片 print (img.size)#打印图片大小 print (img.getpixel((4,4))) width = img.size
-
python获取图片颜色信息的方法
本文实例讲述了python获取图片颜色信息的方法.分享给大家供大家参考.具体分析如下: python的pil模块可以从图片获得图片每个像素点的颜色信息,下面的代码演示了如何获取图片所有点的颜色信息和每种颜色的数量. from PIL import Image image = Image.open("jb51.gif") image.getcolors() 返回结果如下 复制代码 代码如下: ..., (44, (72, 64, 55, 255)), (32, (231, 208, 14
-
用python处理图片实现图像中的像素访问
前面的一些例子中,我们都是利用Image.open()来打开一幅图像,然后直接对这个PIL对象进行操作.如果只是简单的操作还可以,但是如果操作稍微复杂一些,就比较吃力了.因此,通常我们加载完图片后,都是把图片转换成矩阵来进行更加复杂的操作. python中利用numpy库和scipy库来进行各种数据操作和科学计算.我们可以通过pip来直接安装这两个库 pip install numpy pip install scipy 以后,只要是在python中进行数字图像处理,我们都需要导入这些包: fr
-
Python实现去除图片中指定颜色的像素功能示例
本文实例讲述了Python实现去除图片中指定颜色的像素功能.分享给大家供大家参考,具体如下: 这里用python去除图片白色像素 需要python和pil from PIL import Image import numpy as np import cv2 img2 = Image.open('./Amazing_COL_2Fix.bmp') img1 = Image.open('./Amazing_RGB_2L.bmp') # img1 = img1.convert('RGBA') img2
-
Python通过PIL获取图片主要颜色并和颜色库进行对比的方法
本文实例讲述了Python通过PIL获取图片主要颜色并和颜色库进行对比的方法.分享给大家供大家参考.具体分析如下: 这段代码主要用来从图片提取其主要颜色,类似Goolge和Baidu的图片搜索时可以指定按照颜色搜索,所以我们先需要将每张图片的主要颜色提取出来,然后将颜色划分到与其最接近的颜色段上,然后就可以按照颜色搜索了. 在使用google或者baidu搜图的时候会发现有一个图片颜色选项,感觉非常有意思,有人可能会想这肯定是人为的去划分的,呵呵,有这种可能,但是估计人会累死,开个玩笑,当然是通
-
Python 处理图片像素点的实例
###在做爬虫的时候有时需要识别验证码,但是验证码一般都有干扰物,这时需要对验证码进行预处理,效果如下: from PIL import Image import itertools img = Image.open('C:/img.jpg').convert('L') #打开图片,convert图像类型有L,RGBA # 转化为黑白图 def blackWrite(img): blackXY = [] # 遍历像素点 for x in range(img.size[0]): for y in
-
python实现两张图片的像素融合
本文实例为大家分享了python实现两张图片像素融合的具体代码,供大家参考,具体内容如下 通过计算两张图片的颜色直方图特征,利用直方图对图片的颜色进行融合. import numpy as np import cv2 from PIL import Image,ExifTags def calcMeanAndVariance(img): row=img.shape[0] col=img.shape[1] #channel=img.shape[2] total=row*col print (row
-
python通过pil为png图片填充上背景颜色的方法
本文实例讲述了python通过pil为png图片填充上背景颜色的方法.分享给大家供大家参考.具体分析如下: png图片有些是没有背景颜色,如果希望以单色(比如白色)填充背景,可以使用下面的代码,这段代码将当前目录下的 jb51.net.png图片填充了白色背景. 使用指定的颜色的背景色即可,然后把该图片用alpha通道填充到该单色背景上. 比如下面使用白色背景: im = Image.open('jb51.net.png') x,y = im.size try: # 使用白色来填充背景 fro
-
python数据处理 根据颜色对图片进行分类的方法
前面一篇文章有说过,利用scrapy来爬取图片,是为了对图片数据进行分类而收集数据. 本篇文章就是利用上次爬取的图片数据,根据图片的颜色特征来做一个简单的分类处理. 实现步骤如下: 1:图片路径添加 2:对比度处理 3:滤波处理 4:数据提取以及特征向量化 5:图片分类处理 6:根据处理结果将图片分类保存 代码量中等,还可以更少,只是我为了练习类的使用,而将每个步骤都封装成了一个独立的类,当然里面也有类继承的问题,遇到的问题前面一篇文章有讲解.内容可能有点繁琐,尤其是文件和路径的使用(可以自己修
-
Python实现自动为照片添加日期并分类的方法
本文实例讲述了Python实现自动为照片添加日期并分类的方法.分享给大家供大家参考,具体如下: 小时候没怎么照相,所以跟别人说小时候特别帅他们都不信.小外甥女出生了,我给买了个照相机,让她多照相.可惜他舅目前还是个屌丝,买了个700的屌丝照相机,竟然没有自动加日期的功能.试了几个小软件,都不好用,大的图像软件咱又不会用.身为一个计算机科学与技术专业的学生,只能自立更生了. 听说Python有个图形库,不错,在照片上打日期很容易,于是我就下了这个库.对Python不熟,一面看着手册一面写的.完成了
-
通过python将大量文件按修改时间分类的方法
需求是这样的,我从本科到现在硬盘里存了好多照片,本来是按类别分的,有一天,我突然想,要是能按照时间来分类可能会更好.可以右键查看照片的属性,看它的修改日期,从而分类,但是十几个G的照片手动分类工作量还是很大的,所以想着写个脚本程序来完成这一个工作. 程序主要是获取文件的修改时间,包括年和月,并以此为名创建文件夹,再用递归调用的方式遍历整个文件夹,将每一张照片拷贝到相应的文件夹下. 程序源码如下: #coding:utf-8 import os import sys import os.path
-
python GUI框架pyqt5 对图片进行流式布局的方法(瀑布流flowlayout)
流式布局 流式布局,也叫做瀑布流布局,是网页中经常使用的一种页面布局方式,它的原理就是将高度固定,然后图片的宽度自适应,这样加载出来的图片看起来就像瀑布一样整齐的水流淌下来. pyqt流式布局 那么在pyqt5中我们怎么使用流式布局呢?pyqt没有这个控件,需要我们自己去封装,下面是流式布局的封装代码. class FlowLayout(QLayout): def __init__(self, parent=None, margin=0, spacing=-1): super(FlowLayou
-
使用Python实现图像颜色量化的方法
目录 一.选择图片 二.创建脚本 1.导入相关库 2.创建方法 三.完整代码 一.选择图片 从选择图像开始. 例如,我将使用下面的海水和椰子树的照片. 二.创建脚本 1.导入相关库 接下来,让我们导入 extcolors 和 rgb2hex 库. extcolors 库返回 RGB 值,将使用 rgb2hex 库将其转换为 HEX 颜色代码. import numpy as np import pandas as pd import matplotlib.pyplot as plt import
-
Python sklearn分类决策树方法详解
目录 决策树模型 决策树学习 使用Scikit-learn进行决策树分类 决策树模型 决策树(decision tree)是一种基本的分类与回归方法. 分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点(leaf node).内部结点表示一个特征或属性,叶结点表示一个类. 用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子
-
如何使用python数据处理解决数据冲突和样本的选取
目录 内容介绍 实际业务数据冲突 一般数据冲突类型: 一般数据冲突原因: 一般数据处理方法: 样本的选择 一般数据采样方法: 数据的共线性 一般产生原因: 解决共线性的5种常用方法: 内容介绍 将日常工作中遇到的数数据冲突和样本源的方法进行总结,其中主要包括实际业务数据冲突.样本选取问题.数据共线性 等思路,并且长期更新. 实际业务数据冲突 多业务数据源冲突是指来自多个或具有相同业务逻辑但结果不同的系统,环境,平台和工具的数据. 冲突的不同特征 一般数据冲突类型: 数据类型:同字段数据的格式不同
-
Python基于域相关实现图像增强的方法教程
目录 介绍 昆虫增强 使用针的增强 实验结果 介绍 当在图像上训练深度神经网络模型时,通过对由数据增强生成的更多图像进行训练,可以使模型更好地泛化.常用的增强包括水平和垂直翻转/移位.以一定角度和方向(顺时针/逆时针)随机旋转.亮度.饱和度.对比度和缩放增强. Python中一个非常流行的图像增强库是albumentations(https://albumentations.ai/),通过直观的函数和优秀的文档,可以轻松地增强图像.它也可以与PyTorch和TensorFlow等流行的深度学习框
-
Python数据处理-导入导出excel数据
目录 一.xlwt库将数据导入Excel 1.将数据写入一个Excel文件 2.定制Excel表格样式 3.元格对齐 4.单元格的背景色 5.单元格边框 二.xlrd库读取Excel中的数据 1.读取Excel文件 2.工作表的相关操作 3.处理时间数据 前言: Python的一大应用就是数据分析了,而数据分析中,经常碰到需要处理Excel数据的情况.这里做一个Python处理Excel数据的总结,基本受用大部分情况.相信以后用Python处理Excel数据不再是难事儿! 一.xlwt库将数据导