Node.js 去掉种子(torrent)文件里的邪恶信息
2012 年,一部名为 ABS-130 的日本影片引起了网络的震动,网络上纷纷出现了 “当初求种像条狗,如今*完嫌人丑”的现象,成为了 2012 年互联网的一件大事件。
2014年,净网行动如火如荼地进行,各大互联网公司都作出了表率,一时之间XX云、X雷都把万恶的种子拒之门外。净网行动万岁!!(还我苍老师!!)
各大网盘、下载应用都从种子当中提取关键信息,将种子拒之门外。这些关键信息究竟藏在哪里?让我们一探究竟。
种子文件结构
以下内容来自维基百科
.torrent种子文件本质上是文本文件,包含Tracker信息和文件信息两部分。Tracker信息主要是BT下载中需要用到的Tracker服务器的地址和针对Tracker服务器的设置,文件信息是根据对目标文件的计算生成的,计算结果根据BitTorrent协议内的Bencode规则进行编码。它的主要原理是需要把提供下载的文件虚拟分成大小相等的块,块大小必须为2k的整数次方(由于是虚拟分块,硬盘上并不产生各个块文件),并把每个块的索引信息和Hash验证码写入种子文件中;所以,种子文件就是被下载文件的“索引”。

上图是一个典型种子的结构,那些被识别出来的邪恶关键字就藏在 name 和 file 当中。name 包含了该种子的名字,如:abcd-123 性感XXXX。而 file 当中的 path 则包含了要下载的所有文件的信息,如:草X社区最新地址.txt等等。
Node.js 和 parse-torrent 库
为了寻找出种子当中的邪恶信息我们请出了 Node.js 和 parse-torrent库 作为助手。
实验准备:
种子一枚安装 Node.js 电脑一台
首先我们利用 npm 安装 parse-torrent 库,它帮助我们快速找到种子内的信息。
npm install parse-torrent
var fs = require("fs");
var parseTorrent = require('parse-torrent');
var info = parseTorrent(fs.readFileSync('my.torrent'));
console.log(info);
这个库会将种子的信息解析出来,以对象的形式返回给我们。
查看结果:
name:

files:

可以看到用 parse-torrent 库解析出来的 name 和 files 的信息都是以 Buffer 形式存储。
清洗种子
如何将种子里的邪恶信息清洗掉,把万恶的种子扼杀在摇篮之中,最重要的就算要清除调 name 和 files 里面 path 的信息。
function cleanInfo (info) {
// 将种子名用 md5 加密
info.name = md5(info.name);
info['name.utf-8'] = md5(info['name.utf-8']);
var files = info.files;
for (var i = 0; i < files.length; i++) {
var file = files[i];
for (var key in file) {
if (key == "path" || key == "path.utf-8") {
for (var j = 0; j < file[key].length; j++) {
var text = file[key][j].toString();
var dotIndex = text.lastIndexOf(".");
// 将种子名用 md5 加密
file[key][j] = md5(text.slice(0,dotIndex)) + text.slice(dotIndex,text.length);
}
}
}
}
return info;
}
// 将清洗干净后的 info 对象重新生成一个 torrent 文件
var buf = parseTorrent.toTorrentFile({
info: cleanInfos[i]
});
fs.writeFile(dir + "/" + cleanInfos[i].name + ".torrent", buf);
经过这样之后,我们的邪恶种子文件就变成这样了:
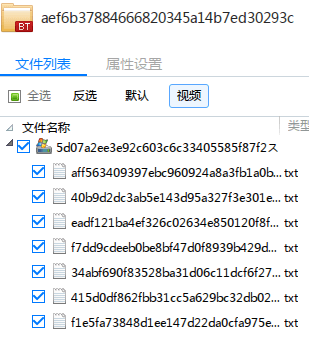
实战阶段
首先准备一个种子,进行XX云的离线下载。

一开始它是被拒绝的。

然后运行脚本进行清洗。
node cleanTorrent IPTD-XXX.torrent下载成功了!

脚本源码放在这里了,要去看一下我的下载内容了!!!


(**都脱了你给我看这个!!!)
最后
本文纯属技术讨论,感谢你的阅读,有不足之处请为我指出。
请您花一点时间将文章分享给您的朋友或者留下评论。我们将会由衷感谢您的支持!
相关推荐
-

Node.js实现在目录中查找某个字符串及所在文件
需求如下: 整个目录下大概有40几M,文件无数,由于时间久了, 记不清那个字符串具体在哪个文件,于是.强大,亮瞎双眼的Node.js闪亮登场. windows下安装Node.js和安装普通软件毫无差别,装完后打开Node.js的快捷方式,或者直接cmd,你懂的. 创建findString.js 复制代码 代码如下: var path = require("path"); var fs = require("fs"); var filePath = process
-
node.js开发中使用Node Supervisor实现监测文件修改并自动重启应用
在开发或调试Node.js应用程序的时候,当你修改js文件后,总是要按下CTRL+C终止程序,然后再重新启动,即使是修改一点小小的参数,也总是要不断地重复这几个很烦人的操作.有没有办法做到当文件修改之后,Node.js自动重新启动(或重新加载文件)以节省时间呢?一开始我是想到用grunt的watch模块来监控文件变化,但后来在网上一查,原来我们想到的,别人早已想到,并且已经做得很好.Node Supervisor正是这样一个可以实现这种需求的Node.js模块. 根据Github上的说明,Nod
-
Node.js中常规的文件操作总结
前言 Node.js 提供一组类似 UNIX(POSIX)标准的文件操作API. Node 导入文件系统模块(fs)语法如下所示: var fs = require("fs") fs模块是文件操作的封装,它提供了文件的读取.写入.更名.删除.遍历目录.链接等POSIX文件系统操作.与其他模块不同的是,fs模块中所有的操作都提供了异步和同步的两个版本,例如读取文件内容的函数有异步的fs.readFile()和同步的fs.readFileSync() . 一. 目录操作 1. 创建目录 创
-
Node.js本地文件操作之文件拷贝与目录遍历的方法
文件拷贝 NodeJS 提供了基本的文件操作 API,但是像文件拷贝这种高级功能就没有提供,因此我们先拿文件拷贝程序练手.与 copy 命令类似,我们的程序需要能接受源文件路径与目标文件路径两个参数. 小文件拷贝 我们使用 NodeJS 内置的 fs 模块简单实现这个程序如下. var fs = require('fs'); function copy(src, dst) { fs.writeFileSync(dst, fs.readFileSync(src)); } function main
-
在Node.js中实现文件复制的方法和实例
Node.js 本身并没有提供直接复制文件的 API,如果想用 Node.js 复制文件或目录,需要借助其他的 API 来实现.复制单个的文件可以直接用 readFile.writeFile,这样比较简便.如果是复制一个目录下的所有文件,目录下可能还包含了子目录,那么此时就需要用到更高级点的 API 了. 流 流是 Node.js 移动数据的方式,Node.js 中的流是可读/可写的,HTTP 和文件系统模块都有用到流.在文件系统中,使用流来读取文件的时候,对于一个大文件可能并不会一次性读取完,
-
node.js开机自启动脚本文件
复制代码 代码如下: #!/bin/bash ### BEGIN INIT INFO # Provides: xiyoulib # Required-Start: $all # Required-Stop: $all # Default-Start: 2 3 4 5 # Default-Stop: 0 1 6 # Short-Description: Start daemon at boot time # Description: Enable ser
-
在Node.js中使用HTTP上传文件的方法
开发环境 我们将使用 Visual Studio Express 2013 for Web 作为开发环境, 不过它还不能被用来做 Node.js 开发.为此我们需要安装 Node.js Tools for Visual Studio. 装好后 Visual Studio Express 2013 for Web 就会转变成一个 Node.js IDE 环境,提供创建这个应用所需要的所有东西..而基于这里提供的指导,我们需要: 下载安装 Node.js Windows 版,选择适用你系统平台的
-
node.js实现逐行读取文件内容的代码
在此之前先介绍一个逐行读取文件内容NPM:https://github.com/nickewing/line-reader,需要的朋友可以看看. 直接上代码: function readLines(input, func) { var remaining = ''; input.on('data', function(data) { remaining += data; var index = remaining.indexOf('\n'); while (index > -1) { var l
-
node.js解决获取图片真实文件类型的问题
遇到一个需求:假定有一个图片文件,真实的类型为jpg,而有人偷懒把jpg直接复制一张,存为同名的png文件,这样在as3读取文件时不会遇到问题,但手机c++在读取文件时却遇到问题了 - -! 现在就需要写一个程序,遍历所有文件夹下的文件,查找文件格式"不正常"的文件.我们的资源主要是gif.png.jpg,最开始,我到网上找到一篇文章:根据二进制流及文件头获取文件类型mime-type,然后读取文件二进制的头信息,获取其真实的文件类型,对与通过后缀名获得的文件类型进行比较. 复制代码
-
Node.js文件操作详解
Node有一组数据流API,可以像处理网络流那样处理文件,用起来很方便,但是它只允许顺序处理文件,不能随机读写文件.因此,需要使用一些更底层的文件系统操作. 本章覆盖了文件处理的基础知识,包括如何打开文件,读取文件某一部分,写数据,以及关闭文件. Node的很多文件API几乎是UNIX(POSIX)中对应文件API 的翻版,比如使用文件描述符的方式,就像UNIX里一样,文件描述符在Node里也是一个整型数字,代表一个实体在进程文件描述符表里的索引. 有3个特殊的文件描述符--1,2和3.他们分别