Python利用lxml模块爬取豆瓣读书排行榜的方法与分析
前言
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢。本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快。
本次爬取的豆瓣书籍排行榜的首页地址是:
https://www.douban.com/doulist/1264675/?start=0&sort=time&playable=0&sub_type=
该排行榜一共有22页,且发现更改网址的 start=0 的 0 为25、50就可以跳到排行榜的第二、第三页,所以后面只需更改这个数字然后通过遍历就可以爬取整个排行榜的书籍信息。
本次爬取的内容有书名、评分、评价数、出版社、出版年份以及书籍封面图,封面图保存为图片,其他数据存为csv文件,方面后面读取分析。
本次的项目步骤:一、分析网页,确定爬取数据
二、使用lxml库爬取内容并保存
三、读取数据并选择部分内容进行分析
步骤一:

分析网页源代码可以看到,书籍信息在属性为的div标签中,打开发现,我们需要爬取的信息都在标签内部,通过xpath语法我们可以很简便的爬取所需内容。
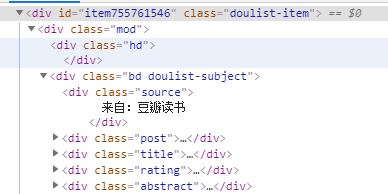
(书籍各类信息所在标签)
所需爬取的内容在 class为post、title、rating、abstract的div标签中。
步骤二:
先定义爬取函数,爬取所需内容执行函数,并存入csv文件
具体代码如下:
import requests
from lxml import etree
import time
import csv
#信息头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
#定义爬取函数
def douban_booksrank(url):
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
contents = selector.xpath('//div[@class="article"]/div[contains(@class,"doulist-item")]') #循环点
for content in contents:
try:
title = content.xpath('div/div[2]/div[3]/a/text()')[0] #书名
scores = content.xpath('div/div[2]/div[4]/span[2]/text()') #评分
scores.append('9.0') #因为有一些书没有评分,导致列表为空,此处添加一个默认评分,若无评分则默认为9.0
score = scores[0]
comments = content.xpath('div/div[2]/div[4]/span[3]/text()')[0] #评论数量
author = content.xpath('div/div[2]/div[5]/text()[1]')[0] #作者
publishment = content.xpath('div/div[2]/div[5]/text()[2]')[0] #出版社
pub_year = content.xpath('div/div[2]/div[5]/text()[3]')[0] #出版时间
img_url = content.xpath('div/div[2]/div[2]/a/img/@src')[0] #书本图片的网址
img = requests.get(img_url) #解析图片网址,为下面下载图片
img_name_file = 'C:/Users/lenovo/Desktop/douban_books/{}.png'.format((title.strip())[:3]) #图片存储位置,图片名只取前3
#写入csv
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as fp: #newline 使不隔行
writer = csv.writer(fp)
writer.writerow((title, score, comments, author, publishment, pub_year, img_url))
#下载图片,为防止图片名导致格式错误,加入try...except
try:
with open(img_name_file, 'wb')as imgf:
imgf.write(img.content)
except FileNotFoundError or OSError:
pass
time.sleep(0.5) #睡眠0.5s
except IndexError:
pass
#执行程序
if __name__=='__main__':
#爬取所有书本,共22页的内容
urls = ['https://www.douban.com/doulist/1264675/?start={}&sort=time&playable=0&sub_type='.format(str(i))for i in range(0,550,25)]
#写csv首行
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as f:
writer = csv.writer(f)
writer.writerow(('title', 'score', 'comment', 'author', 'publishment', 'pub_year', 'img_url'))
#遍历所有网页,执行爬取程序
for url in urls:
douban_booksrank(url)
爬取结果截图如下:
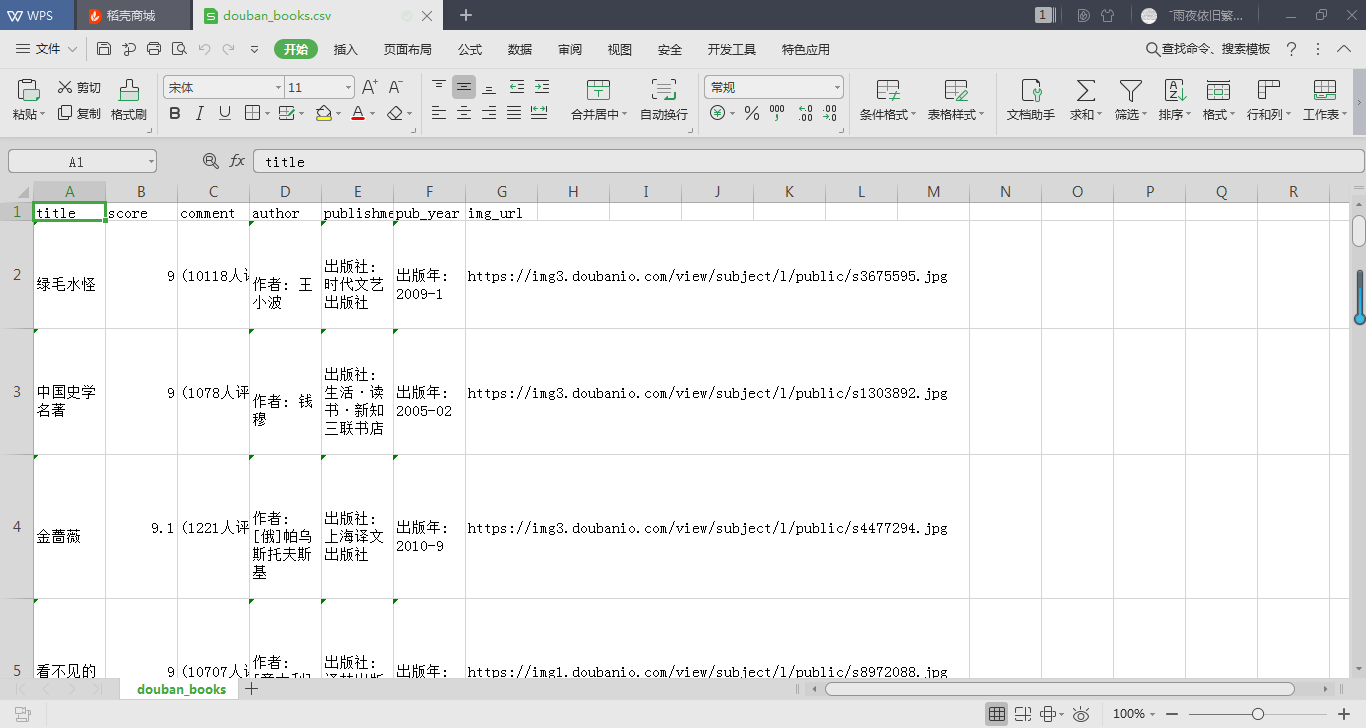
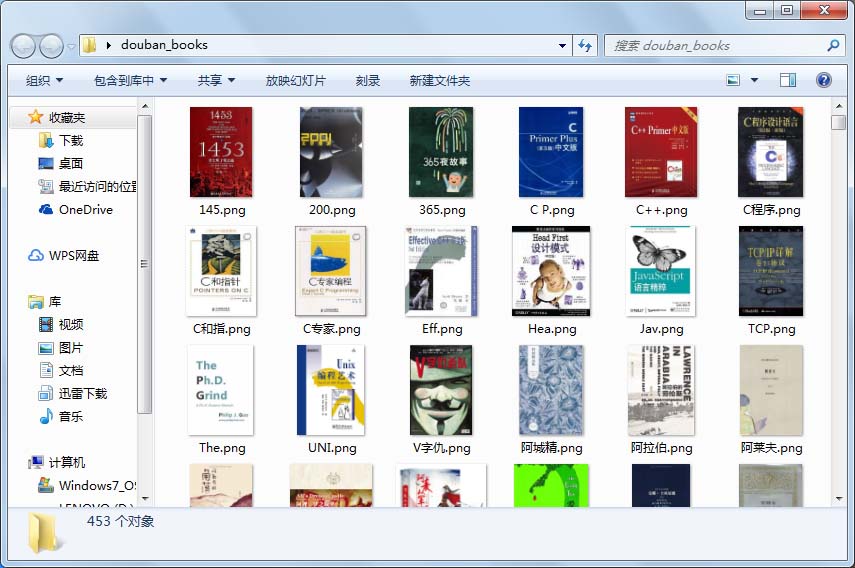
步骤三:
本次使用Python常用的数据分析库pandas来提取所需内容。pandas的read_csv()函数可以读取csv文件并根据文件格式转换为Series、DataFrame或面板对象。
此处我们提取的数据转变为DataFrame(数据帧)对象,然后通过Matplotlib绘图库来进行绘图。
具体代码如下:
from matplotlib import pyplot as plt
import pandas as pd
import re
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.subplots_adjust(wsapce=0.5, hspace=0.5) #调整subplot子图间的距离
pd.set_option('display.max_rows', None) #设置使dataframe 所有行都显示
df = pd.read_csv('C:\\Users\lenovo\Desktop\\douban_books.csv') #读取csv文件,并赋为dataframe对象
comment = re.findall('\((.*?)人评价', str(df.comment), re.S) #使用正则表达式获取评论人数
#将comment的元素化为整型
new_comment = []
for i in comment:
new_comment.append(int(i))
pub_year = re.findall(r'\d{4}', str(df.pub_year),re.S) #获取书籍出版年份
#同上
new_pubyear = []
for n in pub_year:
new_pubyear.append(int(n))
#绘图
#1、绘制书籍评分范围的直方图
plt.subplot(2,2,1)
plt.hist(df.score, bins=16, edgecolor='black')
plt.title('豆瓣书籍排行榜评分分布', fontweight=700)
plt.xlabel('scores')
plt.ylabel('numbers')
#绘制书籍评论数量的直方分布图
plt.subplot(222)
plt.hist(new_comment, bins=16, color='green', edgecolor='yellow')
plt.title('豆瓣书籍排行榜评价分布', fontweight=700)
plt.xlabel('评价数')
plt.ylabel('书籍数量(单位/本)')
#绘制书籍出版年份分布图
plt.subplot(2,2,3)
plt.hist(new_pubyear, bins=30, color='indigo',edgecolor='blue')
plt.title('书籍出版年份分布', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('书籍数量/本')
#寻找关系
plt.subplot(224)
plt.bar(new_pubyear,new_comment, color='red', edgecolor='white')
plt.title('书籍出版年份与评论数量的关系', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('评论数')
plt.savefig('C:\\Users\lenovo\Desktop\\douban_books_analysis.png') #保存图片
plt.show()
这里需要注意的是,使用了正则表达式来提取评论数和出版年份,将其中的符号和文字等剔除。
分析结果如下:
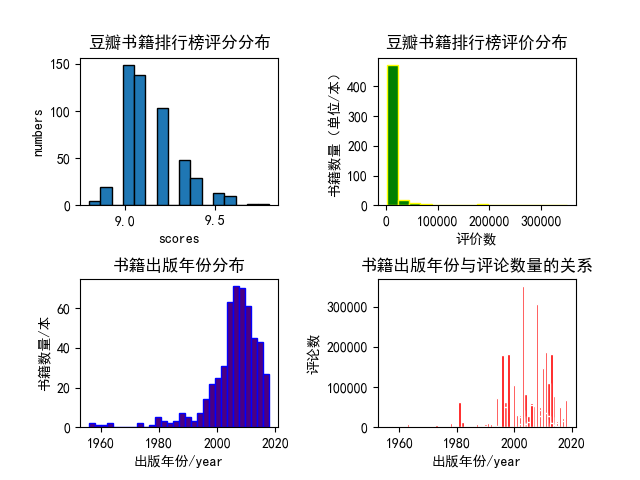
本次分析的内容也较为简单,从上面的几个图形中我们也能得出一些结论。
这些高分书籍中绝大多数的评论数量都在50000以下;多数排行榜上的高分书籍都出版在2000年以后;出版年份在2000年后的书籍有更多的评论数量。
以上数据也见解的说明了在进入二十世纪后我国的图书需求量更大了,网络更发达,更多人愿意发表自己的看法。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对我们的支持。
相关推荐
-
python lxml中etree的简单应用
我一般都是通过xpath解析DOM树的时候会使用lxml的etree,可以很方便的从html源码中得到自己想要的内容. 这里主要介绍一下我常用到的两个方法,分别是etree.HTML()和etree.tostrint(). 1.etree.HTML() etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象.作为_Element对象,可以方便的使用getparent().remove().xpath()等方法. 如果想通过xpath获取htm
-
Python3使用xml.dom.minidom和xml.etree模块儿解析xml文件封装函数的方法
总结了一下使用Python对xml文件的解析,用到的模块儿如下: 分别从xml字符串和xml文件转换为xml对象,然后解析xml内容,查询指定信息字段. from xml.dom.minidom import parse, parseString from xml.etree import ElementTree import xml.dom.minidom """ Get XML String info 查询属性值 response:xml string tag:xml t
-
浅谈Python大神都是这样处理XML文件的
最近有同学询问如何利用Python处理xml文件,特此整理一个比较简洁的操作手册,供大家参阅. 首先准备一个xml文件,xml中的内容如下所示.存储为:student.xml 如果要获取这个xml里面的数据,我们需要利用Python里面ElementTree来进行处理. 具体操作如下所示: 1.导入包(包是Python内置自带) 2.打开文件,并获取根节点的属性和节点名称 运行代码后,结果如下所示: 3.利用find方法获取子节点(缺点:只能根据提供的名称获取第一个子节点) 运行结果如下所示:
-
python解析xml简单示例
本文实例讲述了python解析xml的方法.分享给大家供大家参考,具体如下: xml是除了json之外另外一个比较常用的用来做为数据交换的载体格式.对于一些比较固定的数据,直接保存在xml中,还可以免去去数据库中查询的麻烦.而且直接读小文件,性能比查询数据库应该更好,下面一个例子,如何用python解析xml数据,xml数据是省份,城市 数据,内容如下: <?xml version="1.0" encoding="utf-8" ?> <countr
-
python提取xml里面的链接源码详解
因群里朋友需要提取xml地图里面的链接,就写了这个程序. 代码: #coding=utf-8 import urllib import urllib.request import re url='http://zhimo.yuanzhumuban.cc/sitemaps.xml' html=urllib.request.urlopen(url).read() html=html.decode('utf-8') r=re.compile(r'(http://zhimo.yuanzhumuban.c
-
Python利用lxml模块爬取豆瓣读书排行榜的方法与分析
前言 上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地址是: https://www.douban.com/doulist/1264675/?start=0&sort=time&playable=0&sub_type= 该排行榜一共有22页,且发现更改网址的 start=0 的 0 为25.50就可以跳到排行榜的第二.第三页,所以后
-

Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据
-
python使用re模块爬取豆瓣Top250电影
爬蟲四步原理: 1.发送请求:requests 2.获取相应数据:对方及其直接返回 3.解析并提取想要的数据:re 4.保存提取后的数据:with open()文件处理 爬蟲三步曲: 1.发送请求 2.解析数据 3.保存数据 注意:豆瓣网页爬虫必须使用请求头,否则服务器不予返回数据 import re import requests # 爬蟲三部曲: # 1.获取请求 def get_data(url, headers): response = requests.get(url, headers
-
Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析
前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful Soup爬取网页. 什么是Beautiful Soup Beautiful Soup是一款高效的Python网页解析分析工具,可以用于解析HTL和XML文件并从中提取数据. Beautiful Soup输入文件的默认编码是Unicode,输出文件的编码是UTF-8. Beautiful Soup具有将
-
selenium+PhantomJS爬取豆瓣读书
本文实例为大家分享了selenium+PhantomJS爬取豆瓣读书的具体代码,供大家参考,具体内容如下 获取关于Python的全部书籍信息: 通过代码测试 request携带'User-Agent'及 'data'数据信息的方式均无法获取到相关信息,获取数据时,部分数据为空,导致获取过程中报错,无法获取全部数据,初步判定豆瓣读书的反爬机制较为严格:通过selenium 模拟浏览器请求的方法测试后发现,可利用 selenium 方法请求获取数据: #导入需要的模块 from selenium i
-
python爬取豆瓣电影排行榜(requests)的示例代码
''' 爬取豆瓣电影排行榜 设计思路: 1.先获取电影类型的名字以及特有的编号 2.将编号向ajax发送get请求获取想要的数据 3.将数据存放进excel表格中 ''' 环境部署: 软件安装: Python 3.7.6 官网地址:https://www.python.org/ 安装地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe PyCharm 2020.2.2
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
Python 通过xpath属性爬取豆瓣热映的电影信息
目录 前言 页面分析 实现过程 创建项目 Item定义 中间件操作定义 爬虫定义 数据管道定义 配置设置 执行验证 总结 前言 声明一下:本文主要是研究使用,没有别的用途. GitHub仓库地址:github项目仓库 页面分析 主要爬取页面为:https://movie.douban.com/cinema/nowplaying/nanjing/ 至于后面的地区,可以按照自己的需要改一下,不过多赘述了.页面需要点击一下展开全部影片,才能显示全部内容,不然只有15部.所以我们使用selenium的时
-
Java爬取豆瓣电影数据的方法详解
本文实例讲述了Java爬取豆瓣电影数据的方法.分享给大家供大家参考,具体如下: 所用到的技术有Jsoup,HttpClient. Jsoup jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. HttpClient HTTP 协议可能是现在 Internet 上使用得最多.最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资
-
Python使用requests模块爬取百度翻译
requests模块: python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高. 作用:模拟浏览器发请求. 提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可! requests模块编码流程 指定url 1.1 UA伪装 1.2 请求参数的处理 2.发起请求 3.获取响应数据 4.持久化存储 环境安装: pip install requests 案例一:破解百度翻译(post请求) 1.代码如下: #爬取百度翻