Python爬虫通过替换http request header来欺骗浏览器实现登录功能
以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看。
如果用requests.get()方法获取这个http,没登录只能抓取回一个登录界面,所以我们要用Python登录网站才能抓取想要的网页。
一个简便的方法就是自己在浏览器上登录好,然后通过下图方法(Chrome为例),找到自己的Cookie和User-Agent,然后发送request时用这复制来的header替换掉待发送的request以达到登录的目的,server端会凭这个认为你是已经登录的用户。
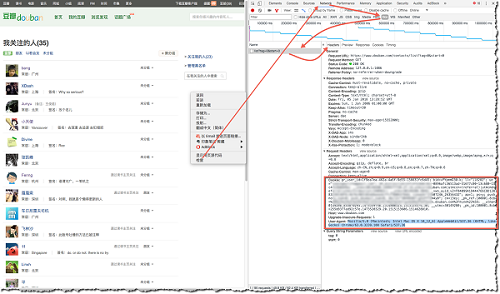
代码如下:
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
'Cookie':'gr_user_id=1f9ea7ea-462a-4a6f-9d55-156631fc6d45; bid=vPYpmmD30-k; ll="118282"; ue="codin; __utmz=30149280.1499577720.27.14.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/doulist/240962/; __utmv=30149280.3049; _vwo_uuid_v2=F04099A9dd; viewed="27607246_26356432"; ap=1; ps=y; push_noty_num=0; push_doumail_num=0; dbcl2="30496987:gZxPfTZW4y0"; ck=13ey; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1515153574%2C%22https%3A%2F%2Fbook.douban.com%2Fmine%22%5D; __utma=30149280.833870293.1473539740.1514800523.1515153574.50; __utmc=30149280; _pk_id.100001.8cb4=255d8377ad92c57e.1473520329.20.1515153606.1514628010.'
} #替换成自己的cookie
r = requests.get('https://www.douban.com/contacts/list', headers = headers)
print(r.text)
总结
以上所述是小编个大家介绍的Python爬虫通过替换http request header来欺骗浏览器实现登录 ,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-
HttpWebRequest出错.Section=ResponseHeader Detail=CR
服务器提交了协议冲突. Section=ResponseHeader Detail=CR 后面必须是 LF The server committed a protocol violation. Section=ResponseHeader Detail=CR must be followed by LF 主体意思是微软没有容忍不符合RFC 822中的httpHeader必须以CRLF结束的规定的服务器响应. 一个解决方案是在application.config或web.config文件里加入 <
-
Python开发中爬虫使用代理proxy抓取网页的方法示例
本文实例讲述了Python开发中爬虫使用代理proxy抓取网页的方法.分享给大家供大家参考,具体如下: 代理类型(proxy):透明代理 匿名代理 混淆代理和高匿代理. 这里写一些python爬虫使用代理的知识, 还有一个代理池的类. 方便大家应对工作中各种复杂的抓取问题. urllib 模块使用代理 urllib/urllib2使用代理比较麻烦, 需要先构建一个ProxyHandler的类, 随后将该类用于构建网页打开的opener的类,再在request中安装该opener. 代理格式是"h
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW
-
java 获取HttpRequest Header的几种方法(必看篇)
在开发应用程序的过程中,如果有多个应用,通常会通过一个portal 门户来集成,这个portal 是所有应用程序的入口,用户一旦在portal 登录之后,进入另外一个系统,就需要类似的单点登录(SSO). 进入各个子系统的时候,就不需要再次登录, 当然类似的功能,你可以通过专业的单点登录软件来实现,也可以自己写数据库token 等方式来实现.其实还有一个比较简单的方法,就是通过 portal 封装已经登录过的用户的消息,写到http header 之中,然后把请求forward 到各个子系统中
-
Python中Scrapy爬虫图片处理详解
下载图片 下载图片有两种方式,一种是通过 Requests 模块发送 get 请求下载,另一种是使用 Scrapy 的 ImagesPipeline 图片管道类,这里主要讲后者. 安装 Scrapy 时并没有安装图像处理依赖包 Pillow,需手动安装否则运行爬虫出错. 首先在 settings.py 中设置图片的存储路径: IMAGES_STORE = 'D:/' 图片处理相关的选项还有: # 图片最小高度和宽度设置,可以过滤太小的图片 IMAGES_MIN_HEIGHT = 110 IMAG
-

Python爬虫通过替换http request header来欺骗浏览器实现登录功能
以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看. 如果用requests.get()方法获取这个http,没登录只能抓取回一个登录界面,所以我们要用Python登录网站才能抓取想要的网页. 一个简便的方法就是自己在浏览器上登录好,然后通过下图方法(Chrome为例),找到自己的Cookie和User-Agent,然后发送request时用这复制来的header替换掉待发送的request以达到登录的目的,server端
-
Python爬虫天气预报实例详解(小白入门)
本文研究的主要是Python爬虫天气预报的相关内容,具体介绍如下. 这次要爬的站点是这个:http://www.weather.com.cn/forecast/ 要求是把你所在城市过去一年的历史数据爬出来. 分析网站 首先来到目标数据的网页 http://www.weather.com.cn/weather40d/101280701.shtml 我们可以看到,我们需要的天气数据都是放在图表上的,在切换月份的时候,发现只有部分页面刷新了,就是天气数据的那块,而URL没有变化. 这是因为网页前端使用
-
Python爬虫 12306抢票开源代码过程详解
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftT
-
Python爬虫实战之12306抢票开源
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 余票查询界面 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-2
-
python爬虫开发之Request模块从安装到详细使用方法与实例全解
python爬虫模块Request的安装 在cmd中,使用如下指令安装requests: pip install requests python爬虫模块Request快速上手 Requests 已安装 Requests 是最新的 Request模块发送请求 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试获取某个网页.本例子中,我们来获取 Github 的公共时间线: >>> r
-
python爬虫实现POST request payload形式的请求
1. 背景 最近在爬取某个站点时,发现在POST数据时,使用的数据格式是request payload,有别于之前常见的 POST数据格式(Form data).而使用Form data数据的提交方式时,无法提交成功. 1.1. Http请求中Form Data 和 Request Payload的区别 AJAX Post请求中常用的两种传参数的形式:form data 和 request payload 1.1.1. Form data get请求的时候,我们的参数直接反映在url里面,形式为
-
python爬虫之request模块深入讲解
目录 一.概述 二.安装和基本步骤使用 三.http知识复习 四.request请求模块的方法使用 五,params和payload参数使用说明 总结 一.概述 在后期渗透测试中,经常会遇到需要向第三方发送http请求的场景,python中的requests库可以很好的满足这一要求,Requests模块是一个用于网络请求的模块,主要用来模拟浏览器发请求.其实类似的模块有很多,比如urllib,urllib2,httplib,httplib2,他们基本都提供相似的功能.但是这些模块都复杂而且差不多
-
Python爬虫:Request Payload和Form Data的简单区别说明
Request Payload 和 Form Data 请求头上的参数差别在于: Content-Type Form Data Post表单请求 代码示例 headers = { "Content-Type": "application/x-www-form-urlencoded" } requests.post(url, data=data, headers=headers) Request Payload 传递json数据 headers = { "C
-
python爬虫用request库处理cookie的实例讲解
python爬虫中使用urli库可以使用opener"发送多个请求,这些请求是能共享处理cookie的,小编之前也提过python爬虫中使用request库会比urllib库更加⽅便,使用使用requests也能达到共享cookie的目的,即使用request库get方法和使用requests库提供的session对象都可以处理. 方法一:使用request库get方法 resp = requests.get('http://www.baidu.com/') print(resp.cookies
-
浅谈Python爬虫原理与数据抓取
通用爬虫和聚焦爬虫 根据使用场景,网络爬虫可分为通用爬虫和聚焦爬虫两种. 通用爬虫 通用网络爬虫 是 捜索引擎抓取系统(Baidu.Google.Yahoo等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 通用搜索引擎(Search Engine)工作原理 通用网络爬虫从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果. 第一步:抓取网页