Linux中Centos7搭建Hadoop服务步骤
下载Hadoop 官网:http://hadoop.apache.org/releases.html
先配置jdk环境(教程:http://www.jb51.net/article/108936.htm)
下载以后 解压到到/usr/local
tar -zxvf hadoop-2.8.0.tar.gz -C /usr/local
为了方便操作 把hadoop-2.8.0 改为hadoop
mv /usr/local/hadoop-2.8.0 /usr/local/hadoop
查看主机名
hostname //第一个参数为主机名
检查是否可以免密码
ssh localhost //这里的localhost为主机名
注意:一般初次安装都需要密码
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
再次验证
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
注意:如没有Enter password 就说明免密码了
配置环境变量
vim /etc/profile
末尾添加
export HADOOP_HOME=/usr/local/hadoop export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin
使环境变量立即生效
source /etc/profile
创建Hadoop的临时文件存放地
mkdir /usr/local/hadoop/tmp
编辑Hadoop的配置文件
cd /usr/local/hadoop/etc/hadoop/ vim hadoop-env.sh
末尾添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_131/ export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
注意:路径要对
使环境变量立即生效
source hadoop-env.sh
配置另一个文件
vim core-site.xml
在<configuration></configuration>中添加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
配置下一个文件 hdfs-site.xml
vim hdfs-site.xml
在<configuration></configuration>中添加以下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
配置下一个文件mapred-site.xml 因为这个文件默认不存在 我们把mapred-site.xml.template作为模板来配置
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在<configuration></configuration>中添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置下下个文件yarn-site.xml
vim yarn-site.xml
在<configuration></configuration>中添加以下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置最后一个文件yarn-env.sh
vim yarn-env.sh
注意:在第23行左右 export JAVA_HOME (删除# 去掉注释),并更改正确jdk的路径
格式化namenode
cd /usr/local/hadoop bin/hdfs namenode-format
注意:成功的话,会看到 “successfully formatted” 和 “Exitting withstatus 0” 的提示,若为 “Exitting with status 1” 则是出错了
通过脚本启动hdfs
sbin/start-dfs.sh
打开浏览器访问http://localhost:50070,验证是否hdfs配置成功
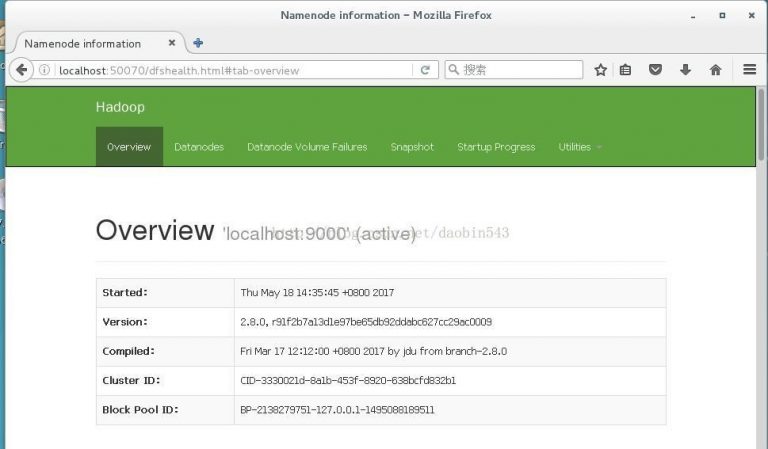
再来启动yarn
sbin/start-yarn.sh
打开浏览器访问http://localhost:8088,验证yarn是否配置成功
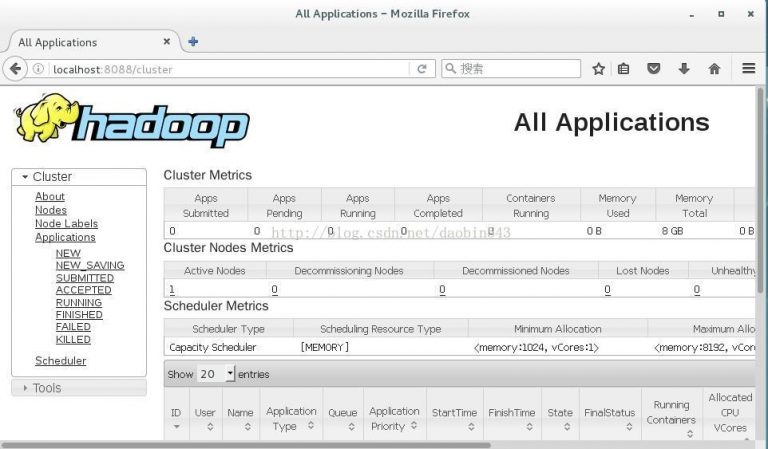
注意:由于浏览器存在缓存问题 打开地址可能会失败关闭浏览器 重新打开一两次就好,如果还是失败 检查配置文件是否有误
查看已启动的hadoop进程
jps
注意:如果没有 NameNode 或 DataNode ,那就是配置不成功
相关推荐
-
Linux中Centos7搭建Hadoop服务步骤
下载Hadoop 官网:http://hadoop.apache.org/releases.html 先配置jdk环境(教程:http://www.jb51.net/article/108936.htm) 下载以后 解压到到/usr/local tar -zxvf hadoop-2.8.0.tar.gz -C /usr/local 为了方便操作 把hadoop-2.8.0 改为hadoop mv /usr/local/hadoop-2.8.0 /usr/local/hadoop 查看主机名 ho
-
Centos7搭建sftp服务流程
注意:此教程是在网站的根目录下搭建sftp 创建一个用户组和用户,并设置密码 groupadd sftp useradd -g sftp -s /bin/false website passwd website 设置website用户的主目录为/var/www/html/uploads/ usermod -d /var/www/html/uploads/ 编辑sftp的配置文件 vim /etc/ssh/sshd_config 修改: #Subsystem sftp /usr/libexec/o
-
linux 之centos7搭建mysql5.7.29的详细过程
1.下载mysql 1.1下载地址 https://downloads.mysql.com/archives/community/ 1.2版本选择 2.管理组及目录权限 2.1解压mysql tar -zxf mysql-5.7.29-linux-glibc2.12-x86_64.tar.gz上传目录/home/tools 2.2重命名 mv mysql-5.7.29-linux-glibc2.12-x86_64 mysql-5.7.29 2.3移动指定目录 mv mysql-5.7.29 /u
-
LINUX Centos7搭建vsftpd服务
前言:在数据传输安全方面,被动模式安全性更高,且ftp连接工具都是默认被动模式:在网络安全方面,则是主动模式安全性更高. 安装vsftpd和ftp连接工具 yum -y install vsftpd ftp 修改vsftpd的配置文件 vim /etc/vsftpd/vsftpd.conf 修改: anonymous_enable=NO //修改为NO chroot_list_enable=YES //去掉前面的#号 chroot_list_file=/etc/vsftpd/chroot_lis
-

Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
linux下搭建hadoop环境步骤分享
1.下载hadoop包 wget http://apache.freelamp.com/hadoop/core/stable/hadoop-0.20.2.tar.gz2.tar xvzf hadoop-0.20.2.tar.gz3.安装JDK,从oracle网站上直接下载JDK,地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html4.chmod +x jdk-6u21-linux-i586.bin;./jdk-
-
使用Samba在Linux服务器上搭建共享文件服务的方法
最近我们的小团队需要在服务器上共分出一个共享文件夹用于大家存放公共的资源文档, 大家想啊,这肯定很简单呀,在Windows下面只要创建相关的windows account,共享某个文件夹,把读/写权限给我们创建的account的,就完成了共享,但在Linux下面就没有这么美好了,网上查阅资源资料多指向通过Samba完成共享任务,但一些blog只介绍了怎么做,但没有为什么这么 做,搭建工作且不太顺利,对Linux算不上熟悉,走了很多弯路,所以通过这篇blog深入理解其中的每一步. Samba的简介
-
Linux中安装Nginx的正确步骤
前言 如果你和我一样,作为一个苦逼的Java后台除了实现实现一大堆项目功能,还要兼顾项目的部署,运维工作.在新的服务器上安装新Nginx,在安装之前看下网上的教程,面对五花八门的教程,各式各样的安装方法,心里总会嘀咕什么方式才是最好的,或者说什么方法才是最适合自己的?下面我们一起来分析Nginx各种安装方式,分别适合于那种情况. 使用系统二进制源方式安装 在Ubuntu/Debian系 sudo apt-get install nginx 或者RedHat/CentOS系 sudo yum in
-
Linux中环境变量配置的步骤详解
简介 我们大家在平时使用Linux的时候,经常需要配置一些环境变量,这时候一般都是网上随便搜搜就有人介绍经验的.不过问题在于他们的方法各不相同,有人说配置在/etc/profile里,有人说配置在/etc/environment,有人说配置在~/.bash_profile里,有人说配置在~/.bashrc里,有人说配置在~/.bash_login里,还有人说配置在~/.profile里...这真是公说公有理...那么问题来了,Linux到底是怎么读取配置文件的呢,依据又是什么呢?下面这篇文章就来
-
Linux中Python 环境软件包安装步骤
简介: 记录一下关于 Python 环境软件包的一些安装步骤 1.升级 Python 到 2.7.10( 默认 2.6.6 ) shell > yum -y install epel-release shell > yum -y install gcc wget readline-devel zlib-devel openssl-devel shell > wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz sh