Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频。
一、实现登录账号
这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码。登录后,采用session保持登录。
1.获取验证码地址
第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608
颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此真正的验证码图片地址是:https://per.enetedu.com/Common/CreateImage
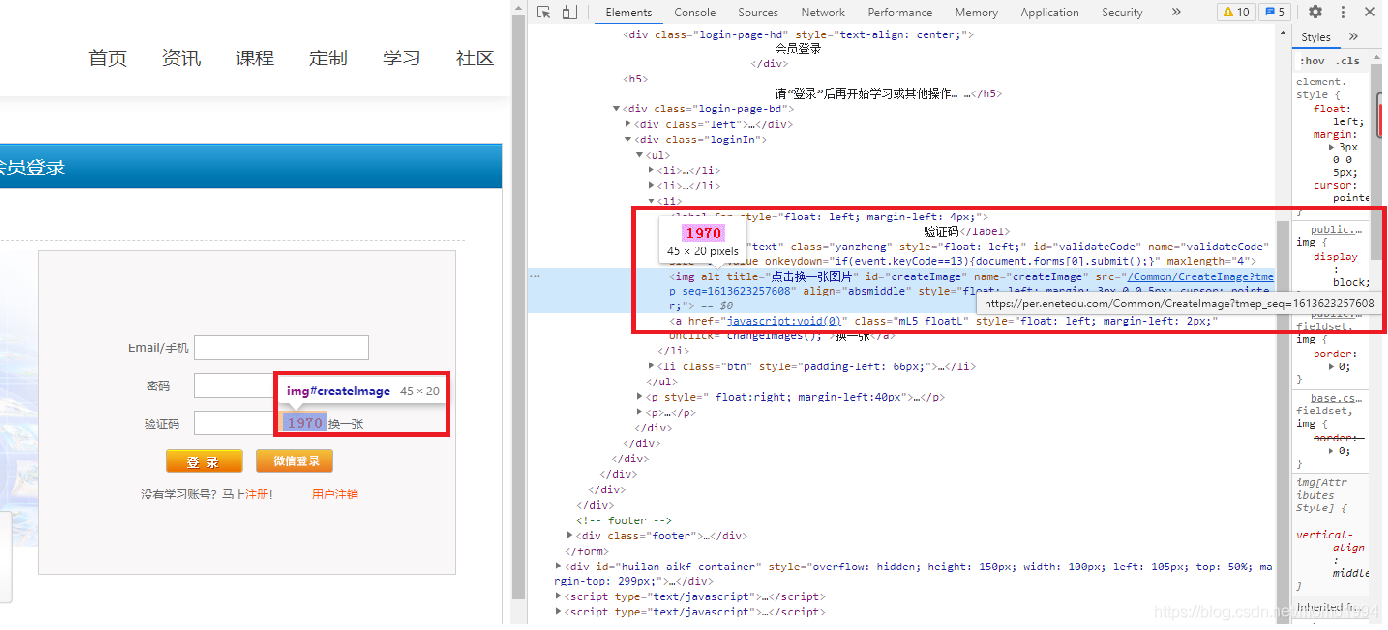
第二步:找出登录时提交的表单内容和POST地址。
(1) 不填写用户名密码和验证码,直接点击登录,使用Chrome浏览器的Network检查,找到POST地址:https://per.enetedu.com/AdminIndex/LoginDo
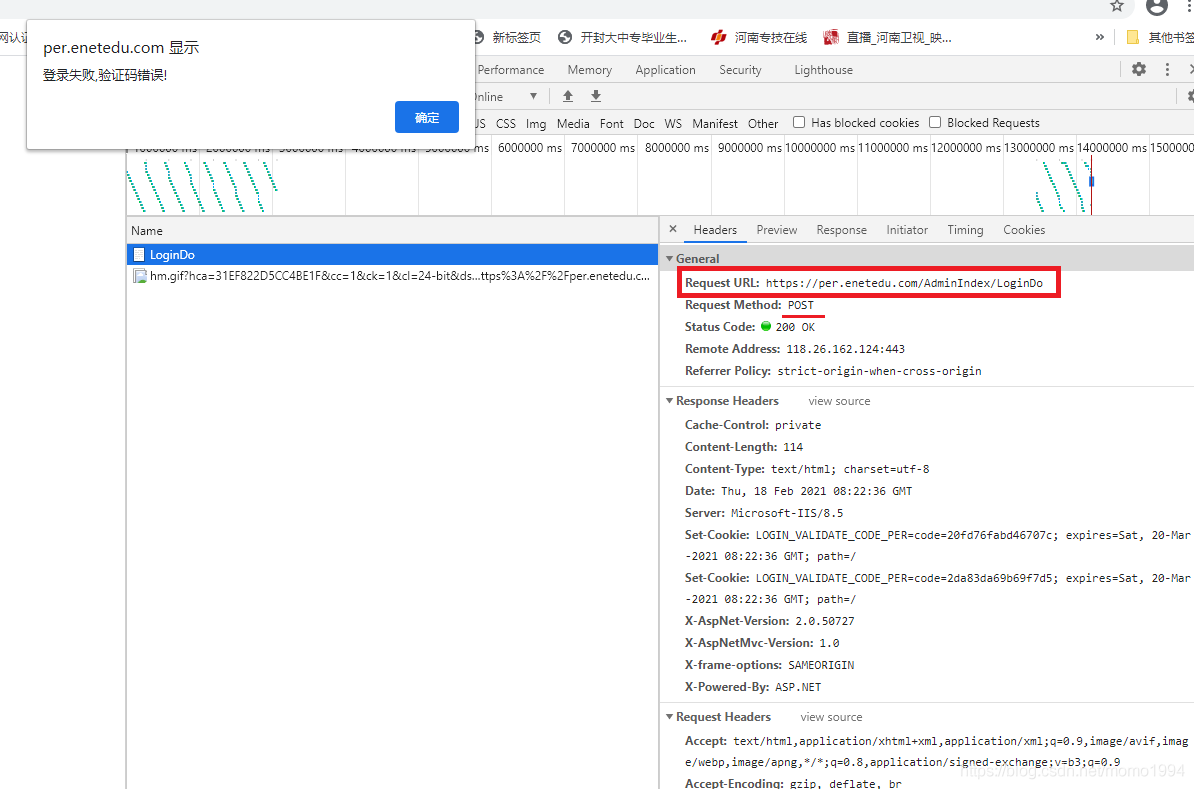
(2) 继续向下看,找到提交的表单 Form Data。
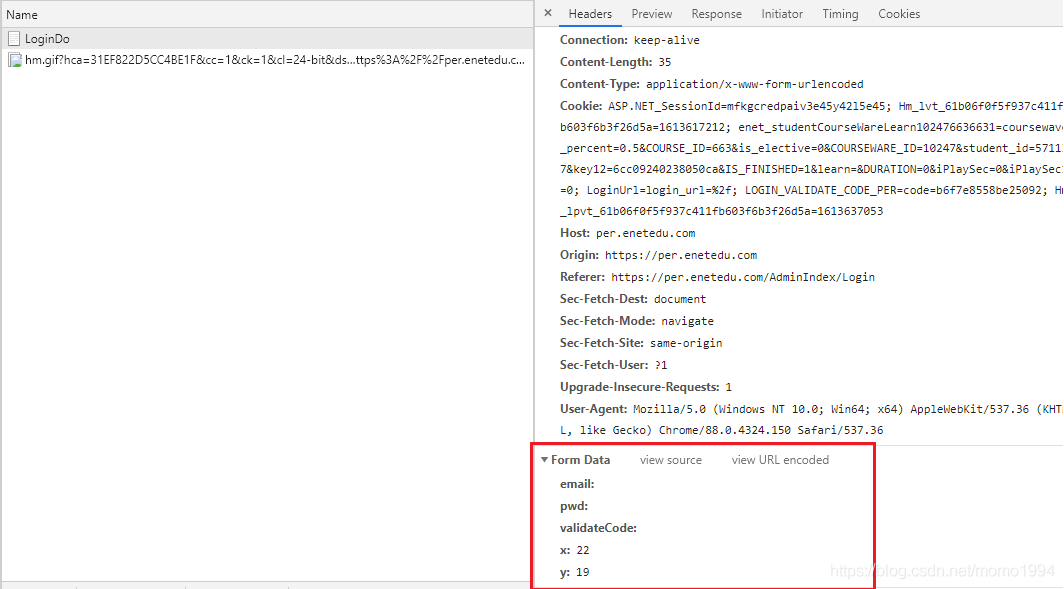
因此带有验证码的登录代码如下:
import requests
from PIL import Image
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '替换为自己的用户名'
password = '替换为自己的密码'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '22',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
二、实现ts碎片视频下载,并转换为mp4格式
1.分析视频下载地址
登录成功后,检查视频播放div对应的代码,企图找到视频地址直接保存至本地。结果,如下图所示,整个视频是被分割成一段一段的.ts文件,分段加载到页面中播放。GET每段视频的地址为右侧红框圈起来的部分。
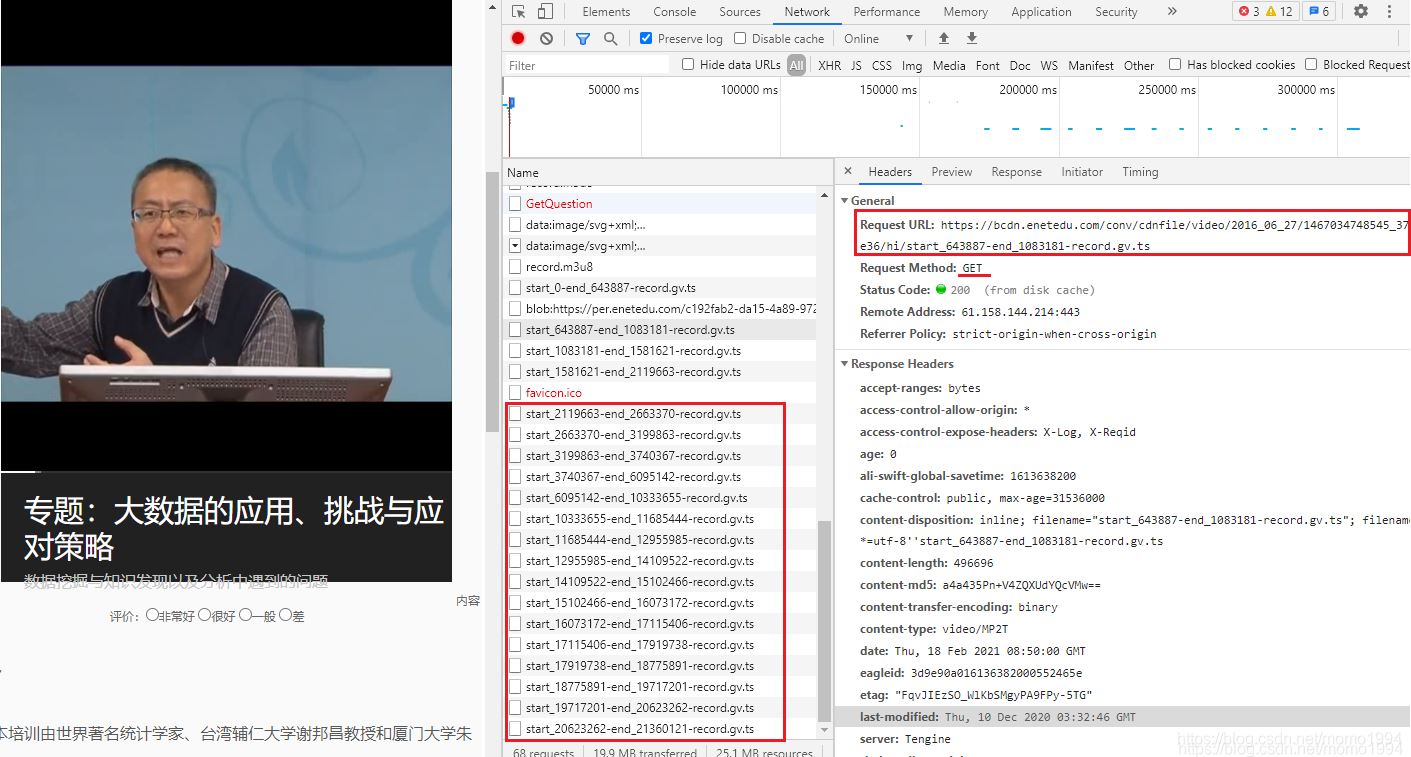
百度后才知道,整个视频如何分段是由一个m3u8文件来决定的。m3u8文件中的内容如下所示,记录了每段视频start和end的编号。
#EXTM3U #EXT-X-VERSION:3 #EXT-X-ALLOW-CACHE:YES #EXT-X-TARGETDURATION:10 #EXTINF:10.000000, start_0-end_765064-record.gv.ts #EXTINF:10.000000, start_765064-end_1769567-record.gv.ts #EXTINF:10.000000, start_1769567-end_2600798-record.gv.ts #EXTINF:10.000000, start_2600798-end_3593502-record.gv.ts #EXTINF:10.000000, start_3593502-end_4500784-record.gv.ts #EXTINF:10.000000, start_4500784-end_5399861-record.gv.ts #EXTINF:10.000000, start_5399861-end_6288622-record.gv.ts #EXTINF:10.000000, start_6288622-end_7044459-record.gv.ts #EXTINF:10.000000, start_7044459-end_7878487-record.gv.ts #EXTINF:10.000000, start_7878487-end_8811793-record.gv.ts #EXTINF:10.000000,
因此,下载视频的关键是获取m3u8文件,通过这个视频的m3u8文件来分段下载视频。
我是人工找出m3u8的下载地址,暂时还没研究出来怎么通过视频地址自动解析出m3u8地址。找的方法很简单,还是在Chrome的Network控制台找。打开Network控制台,刷新页面,就可以找到如图所示的m3u8文件。查看m3u8文件的相关信息,可以看到红框圈起来的地址就是这个视频的m3u8下载地址。
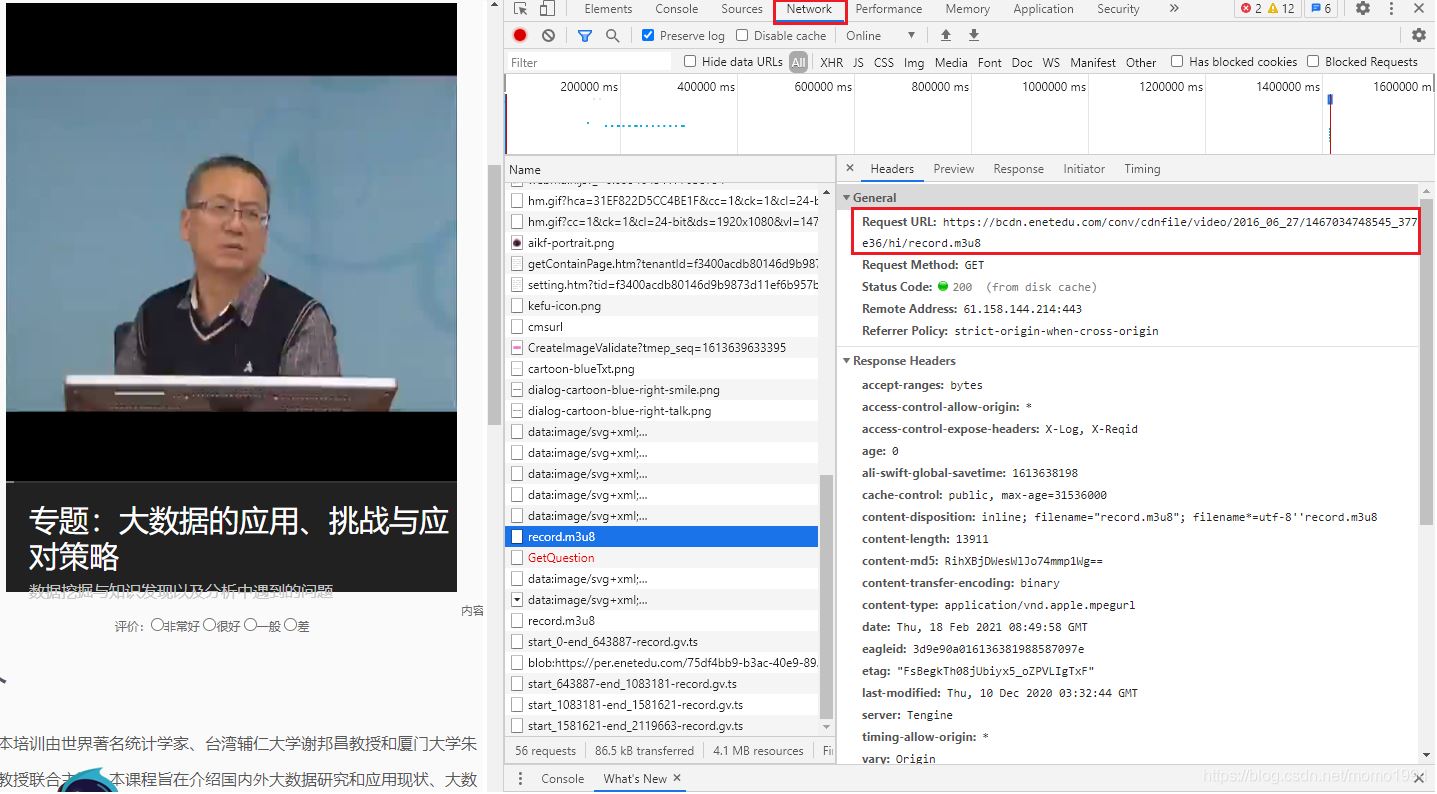
对比两个地址,可以发现文件名前的地址相同,视频下载地址即为"标红地址"+"m3u8文件中列出的视频段文件名":
https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi/record.m3u8
https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi/start_643887-end_1083181-record.gv.ts
因此可以将这部分地址设为:urlroot = https://bcdn.enetedu.com/conv/cdnfile/video/2016_06_27/1467034852884_f5821b/hi
为了方便下载其他视频时动态修改,改为动态截取:
url = input("请输入m3u8文件地址:")
urlRoot=self.url[0:url.rindex('/')]
2.批量下载ts视频片段
这一步使用上一步拼接的地址循环下载ts视频即可。下载时,使用登录时创建的session下载。
session是会话的意思,它可以让服务器“认得”客户端。简单理解就是,把每一个客户端和服务器的互动当作一个“会话”。既然在同一个“会话”里,服务器自然就能知道这个客户端是否登录过。代码如下:
client = requests.Session() client.post(PostUrl,postData) #登录 resp = client.get(download_path) #下载
碎片拼接的方法:下载完第一个ts片段后,直接在该文件后面继续写第二个ts片段,以此类推。而不是新建一个文件写入。与验证码登录结合起来,完整代码如下:
import requests
from PIL import Image
import sys
import m3u8
import time
import os
#用户名-密码-验证码方式,登录
CaptchaUrl = "https://per.enetedu.com/Common/CreateImage" #获取验证码地址
PostUrl = "https://per.enetedu.com/AdminIndex/LoginDo" #post登录信息地址
client = requests.Session()
username = '526257482@qq.com'
password = 'dashuju_9514'
qr_code = client.get(CaptchaUrl)
open('login.jpg', 'wb').write(qr_code.content) #将验证码图片保存至本地
img = Image.open('login.jpg')
img.show() #打开图片
code = input("请输入验证码: \n") #输入验证码
postData = { #构造POST表单
'email': username,
'pwd': password,
'validateCode': code,
'x': '56',
'y': '19'
}
result = client.post(PostUrl,postData) #向PostUrl提交表单
#循环下载ts视频
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.final_path=r"D:\Download\Film"
#下载并解析m3u8文件
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
realAdr = self.url #m3u8下载地址
urlList=self.get_url_from_m3u8(realAdr) #解析m3u8文件,获取下载地址
urlRoot=self.url[0:self.url.rindex('/')]
i=1
outputfile=open(os.path.join(self.final_path,'%s.ts'%self.fileName),'wb')#初始创建一个ts文件,之后每次循环将ts片段的文件流写入此文件中从而不需要在去合并ts文件
for url in urlList:
try:
download_path = "%s/%s" % (urlRoot, url.uri) #拼接地址
resp = client.get(download_path) #使用拼接地址去爬取数据
progess = i/len(urlList)#记录当前的爬取进度
outputfile.write(resp.content) #将爬取到ts片段的文件流写入刚开始创建的ts文件中
sys.stdout.write('\r正在下载:{},进度:{:.2%}'.format(self.fileName,progess))#通过百分比显示下载进度
sys.stdout.flush()#通过此方法将上一行代码刷新,控制台只保留一行
except Exception as e:
print("\n出现错误:%s",e.args)
continue#出现错误跳出当前循环,继续下次循环
i+=1
outputfile.close()
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("开始转换视频格式!")
success = os.system(r'copy /b D:\Download\Film\{0}.ts D:\Download\Film\{0}.mp4'.format(self.fileName)) #ts转成mp4格式
if (not success):
print("格式转换成功!")
os.remove(self.final_path+'\\'+self.fileName+".ts") #删除ts和m3u8临时文件
os.remove("temp.m3u8")
if __name__=='__main__':
m3u8_addr = input("输入m3u8文件下载地址:\n")
crawler=VideoCrawler(m3u8_addr)
crawler.fileName = input("输入文件名:\n")
crawler.run()
quitClick=input("请按Enter键确认退出!")
三、总结
代码可以实现分段加载视频的爬取功能,其中还有很多细节待完善如:
- 验证码可以通过图像识别的方法自动识别。
- 通过解析视频地址获取m3u8文件,非计算机专业人使用起来更加友好。
- 例子中的网站没有对m3u8文件进行加密,涉及到加密的m3u8还需要加一步解密的过程。
到此这篇关于Python爬虫爬取ts碎片视频+验证码登录功能的文章就介绍到这了,更多相关Python爬虫爬取视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫利用cookie实现模拟登陆实例详解
Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 举个例子,某些网站是需要登录后才能得到你想要的信息的,不登陆只能是游客模式,那么我们可以利用Urllib2库保存我们以前登录过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取.理解cookie主要是为我们快捷模拟登录抓取目标网页做出准备. 我之前的帖子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有ur
-
Python爬虫设置Cookie解决网站拦截并爬取蚂蚁短租的问题
我们在编写Python爬虫时,有时会遇到网站拒绝访问等反爬手段,比如这么我们想爬取蚂蚁短租数据,它则会提示"当前访问疑似黑客攻击,已被网站管理员设置为拦截"提示,如下图所示.此时我们需要采用设置Cookie来进行爬取,下面我们进行详细介绍.非常感谢我的学生承峰提供的思想,后浪推前浪啊! 一. 网站分析与爬虫拦截 当我们打开蚂蚁短租搜索贵阳市,反馈如下图所示结果. 我们可以看到短租房信息呈现一定规律分布,如下图所示,这也是我们要爬取的信息. 通过浏览器审查元素,我们可以看到需要爬取每条租
-
Python爬虫番外篇之Cookie和Session详解
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么是Cookie 其实简单的说就是当用户通过http协议访问一个服务器的时候,这个服务器会将一些Name/Value键值对返回给客户端浏览器,并将这些数据加上一些限制条件.在条件符合时,这个用户下次再访问服务器的时候,数据又被完整的带给服务器. 因为http是一种无状态协议,用户首次访问web站点的时
-
Python爬虫制作翻译程序的示例代码
上篇文章给大家介绍了Python爬虫实现百度翻译功能过程详解 Python爬虫学习之翻译小程序 感兴趣的朋友点击查看. 今天给大家介绍Python爬虫制作翻译程序的方法,具体内容如下所示: 此处我爬的是百度翻译,打开百度翻译的页面 我们要爬的是sug,爬它的响应信息 程序如下 import json import requests if __name__ == "__main__": url = "https://fanyi.baidu.com/sug" head
-
Python爬虫爬取微博热搜保存为 Markdown 文件的源码
什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫. 其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据 爬虫可以做什么? 你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到. 爬虫的本质是什么? 上面关于爬虫可以做什么,定义了一个前提
-
玩转python爬虫之cookie使用方法
之前一篇文章我们学习了爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了. 在此之前呢,我们必须先介绍一个opener的概念. 1.Opener 当你获取一个URL你
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此
-
python爬虫爬取某网站视频的示例代码
把获取到的下载视频的url存放在数组中(也可写入文件中),通过调用迅雷接口,进行自动下载.(请先下载迅雷,并在其设置中心的下载管理中设置为一键下载) 实现代码如下: from bs4 import BeautifulSoup import requests import os,re,time import urllib3 from win32com.client import Dispatch class DownloadVideo: def __init__(self): self.r = r
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
如何实现python爬虫爬取视频时实现实时进度条显示
目录 一.全部代码展示 二.解释 1.with closing with用法(实现上下文管理) closing用法(完美解决上述问题) 2.文件流stream 3.response.headers['content-length'] 4.response.iter_content() 5.\r和% 三.结果展示 四.总结 前言: 在爬取并下载网页上的视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度. 一.全部代码展示 from contextlib import clos
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python爬虫爬取淘宝商品比价(附淘宝反爬虫机制解决小办法)
因为评论有很多人说爬取不到,我强调几点 kv的格式应该是这样的: kv = {'cookie':'你复制的一长串cookie','user-agent':'Mozilla/5.0'} 注意都应该用 '' ,然后还有个英文的 逗号, kv写完要在后面的代码中添加 r = requests.get(url, headers=kv,timeout=30) 自己得先登录自己的淘宝账号才有自己登陆的cookie呀,没登录cookie当然没用 以下原博 本人是python新手,目前在看中国大学MOOC的嵩天
-
使用Python爬虫爬取小红书完完整整的全过程
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于Python进击者 ,作者kuls Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space.bilibili.com/523606542 小红书 首先,我们打开之前大家配置好的charles 我们来简单抓包一下小红书小程序(注意这里是小程序,不是app) 不选择app的原因是,小红书的App有点难度,参照网上的一些思路,还是选择了小程序 1
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'