如何利用python将Xmind用例转为Excel用例
目录
- 1、Xmind用例编写规范
- 2、转换代码
- 3、使用
1、Xmind用例编写规范
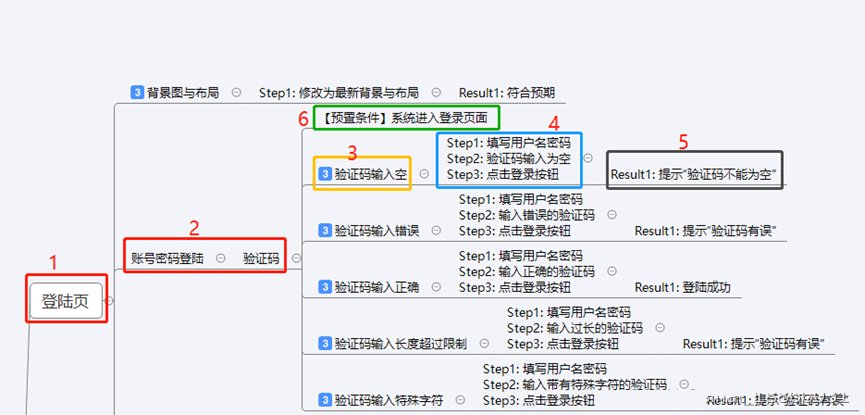
- 1:需求大模块
- 2:大模块中的小模块(需要根据需求来看需要多少层)
- 3:用例等级和用例名称
- 用例等级(转换成Excel文件后,1为High, 2 为 Middle, 3为Low)
- 转换成excel时,用例的名称为(框出来的1-2-3组合而成),意味着在标等级及之前的节点会组合成用例名称
- 4:步骤
- 5:期望结果
- 6:预置条件,转换成excel时相同层级下的用例会为同一个预置条件
2、转换代码
需要安装python3环境
需要安装 xlwt、xmindparser 这两个第三方包
XmindExcel.py 文件代码
# coding=utf-8
import time
import xlwt
from past.builtins import raw_input
from xmindparser import xmind_to_dict
def resolvePath(dict, lists, title):
# title去除首尾空格
title = title.strip()
# 如果title是空字符串,则直接获取value
if len(title) == 0:
concatTitle = dict['title'].strip()
elif "makers" in dict.keys():
if "priority-" in str(dict["makers"]):
concatTitle = title + '\t' + dict['title'].strip() + "\t" + str(dict["makers"])
else:
concatTitle = title + '\t' + dict['title'].strip()
else:
concatTitle = title + '\t' + dict['title'].strip()
if dict.__contains__('topics') == False:
lists.append(concatTitle)
else:
for d in dict['topics']:
resolvePath(d, lists, concatTitle
def xmind_cat(list, excelname, groupname):
f = xlwt.Workbook()
sheet = f.add_sheet(groupname, cell_overwrite_ok=True)
row0 = ["测试用例编号", "用例标题", "预置条件", "执行方式", "优先级", "测试步骤", "预期结果", "所属项目"]
# 生成第一行中固定表头内容
for i in range(0, len(row0)):
sheet.write(0, i, row0[i])
# 增量索引
index = 0
# case级别
case_leve_index = ""
# 前置条件
case_pre_condition = []
pre_num = 0
for h in range(0, len(list)):
# print("list:",list)
lists = []
resolvePath(list[h], lists, '')
for j in range(0, len(lists)):
# 将xmind转成excel
lists[j] = lists[j].split('\t')
try:
# print(index)
if "【预置条件】" in lists[j][-1] or "【前置条件】" in lists[j][-1]:
case_pre_condition.append(lists[j])
pre_num += 1
else:
case_leve = ""
for n in range(len(lists[j])):
if 'priority-' in str(lists[j][n]):
case_leve_index = n-1
if "priority-1" in str(lists[j][n]):
case_leve = "High"
elif "priority-2" in str(lists[j][n]):
case_leve = "Middle"
elif "priority-3" in str(lists[j][n]):
case_leve = "Low"
lists[j].pop(n)
break
case_name = "-".join(lists[j][:case_leve_index+1])
sheet.write(j + index + 1 - pre_num, 1, case_name) # 标题
if len(lists[j][case_leve_index:-1]) < 2:
sheet.write(j + index + 1 - pre_num, 6, lists[j][case_leve_index + 1]) # 期望结果
else:
sheet.write(j + index + 1- pre_num, 5, lists[j][case_leve_index + 1]) # 步骤
sheet.write(j + index + 1- pre_num, 6, lists[j][case_leve_index + 2]) # 期望结果
sheet.write(j + index + 1- pre_num, 3, "手动") # 执行方式
sheet.write(j + index + 1 - pre_num, 4, case_leve)
# 预置条件
if len(case_pre_condition) > 0:
for pre_list in case_pre_condition:
if set(pre_list[:-1]) < set(lists[j]):
sheet.write(j + index + 1 - pre_num, 2, pre_list[-1])
except:
print("请检查编写的用例是否符合规范:", lists[j])
# 遍历结束lists,给增量索引赋值,跳出for j循环,开始for h循环
if j == len(lists) - 1:
index += len(lists)
f.save(excelname)
def maintest(filename, excelname):
out = xmind_to_dict(filename)
groupname = out[0]['topic']['title']
xmind_cat(out[0]['topic']['topics'], excelname, groupname)
if __name__ == '__main__':
try:
path = raw_input("请输入Xmind用例文件路径,可将文件拖拽到此处:")
filename = path
excelname = path.rstrip('xmind') + 'xls'
maintest(filename, excelname)
print('SUCCESS!\n生成用例成功,用例目录:%s' % excelname)
except:
print('请确认后重试:\n1.用例文件路径中不能有空格换行符\n2.请使用python3运行\n3.检查xmind文件中不能有乱码或无法识别的字符(xmind自带表情字符除外)\n4.检查是否将已生成的excel文件未关闭')
3、使用
运行XmindExcel.py文件,输入文件目录运行即可。生成的Excel文件会在Xmind文件的同路径下,文件名称与Xmind文件名称一致

到此这篇关于如何利用python将Xmind用例转为Excel用例的文章就介绍到这了,更多相关python Excel用例内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
使用Python将xmind脑图转成excel用例的实现代码(一)
最近接到一个领导需求,将xmind脑图直接转成可以导入的excel用例,并且转换成gui可执行的exe文件,方便他人使用. 因为对Python比较熟悉,所以就想使用Python3来实现这个功能,先理一下思路,首先要将xmind转换成Python可用的数据格式,正好找到了一个xmindparser库可以做这个事情,然后就好办了,用xlwt库写成xls文件,再用Python自带的gui库 tkinter来写 gui界面,最后用pyinstaller来打包. 计划分两个py文件来写,一个文件写exce
-

使用Python 操作 xmind 绘制思维导图的详细方法
思维导图 思维导图:思维导图又叫心智导图是表达发散性思维的有效的图形思维工具,它简单却又很有效,是一种革命性的思维工具.思维导图运用图文并重的技巧,把各级主题的关系用相互隶属与相关的层级图表现出来,把主题关键词与图像.颜色等建立记忆链接.思维导图充分运用左右脑的机能,利用记忆.阅读.思维的规律,协助人们在科学与艺术.逻辑与想象之间平衡发展,从而开启人类大脑的无限潜能.思维导图因此具有人类思维的强大功能. 思维导图是一种将思维形象化的方法.简单来讲:思维导图就是能有层次感的展示我们想法的思维工具.
-
使用python把xmind转换成excel测试用例的实现代码
前言 因为写好了测试xmind脑图后,然后再编写测试用例,实在是太麻烦了,所以我写了一点测试用例后,就网上百度了下,怎么直接把xmind脑图转换成excel测试用例,纯个人学习笔记 本文参考: https://www.cnblogs.com/xu-xu/articles/11999960.html https://www.cnblogs.com/xu-xu/articles/12000205.html 提示:以下是本篇文章正文内容,下面可供参考 一.确定好自己的xmind的用例格式 因为xmin
-
python xmind 包使用详解(其中解决导出的xmind文件 xmind8可以打开 xmind2020及之后版本打开报错问题)
pip install xmind 使用 場景 xmind8 可以打开 xmind2020 报错 main_fest.xml(xmind8 打开另存后 更改后缀为.zip 里边包含META-INF/manifest.xml) ** 将xmind文件修改后缀为zip ---->解压---->放入main_fest.xml ->压缩为zip ->修改后缀为xmind** import xmind import os import re import shutil import zipf
-
如何利用python将Xmind用例转为Excel用例
目录 1.Xmind用例编写规范 2.转换代码 3.使用 1.Xmind用例编写规范 1:需求大模块 2:大模块中的小模块(需要根据需求来看需要多少层) 3:用例等级和用例名称 用例等级(转换成Excel文件后,1为High, 2 为 Middle, 3为Low) 转换成excel时,用例的名称为(框出来的1-2-3组合而成),意味着在标等级及之前的节点会组合成用例名称 4:步骤 5:期望结果 6:预置条件,转换成excel时相同层级下的用例会为同一个预置条件 2.转换代码 需要安装python
-
利用python实现.dcm格式图像转为.jpg格式
如下所示: import pydicom import matplotlib.pyplot as plt import scipy.misc import pandas as pd import numpy as np import os def Dcm2jpg(file_path): #获取所有图片名称 c = [] names = os.listdir(file_path) #路径 #将文件夹中的文件名称与后边的 .dcm分开 for name in names: index = name.
-
利用python将 Matplotlib 可视化插入到 Excel表格中
目录 数据可视化 图表插入Excel 前言: 在生活中工作中,我们经常使用Excel用于储存数据,Tableau等BI程序处理数据并进行可视化.我们也经常使用R.Python编程进行高质量的数据可视化,生成制作了不少精美优雅的图表. 但是如何将这些“优雅”延续要Excel中呢?Python绘图库有很多,我们就还是拿最基本的Matplotlib为例. 今天就为大家演示一下,如何将Matplotlib绘制的可视化图片,插入到Excel中. 其他可视化库生成的图片,也同样适用 数据可视化 目前Pyth
-
利用Python将时间或时间间隔转为ISO 8601格式方法示例
前言 大家都知道,Python自带的datetime库提供了将datetime转为ISO 8610格式的函数,但是对于时间间隔(inteval)并没有提供转换的函数,下面我们动手写一个. 下面话不多说了,来一起看看详细的介绍吧. 对于时间间隔,ISO 8601的表示形式如下: P表示的是时间间隔的前缀.YMDHMS分别表示年月日时分秒,W表示周.T表示后面的字符是精确到天的,也就是以小时表示开始的前缀. 英文解释如下 : [P] is used as time-interval (period)
-
利用Python将彩色图像转为灰度图像的两种方法
目录 第一种方法 第二种方法 python 批量将图片转为灰度图 总结 第一种方法 Python的cv2库中自带彩色转灰度的方法,而且非常简单,代码就9行,核心代码就1行. 大题思路就是先读取一张彩色图片,然后在窗口中显示出来,再然后就让cv2处理一下,转换成灰度图像,这时候它是个二维的灰度矩阵,所以,我们想保存得先将它从array转成image,最后在另一个窗口中显示出来,为了避免窗口一闪而过,我们需要加上waitKey(0)这一句. import cv2 from PIL import Im
-
如何利用Python将字典转为成员变量
目录 技术背景 使用__dict__定义成员变量 嵌套字典转成员变量 总结概要 参考链接 技术背景 当我们在Python中写一个class时,如果有一部分的成员变量需要用一个字典来命名和赋值,此时应该如何操作呢?这个场景最常见于从一个文件(比如json.npz之类的文件)中读取字典变量到内存当中,再赋值给一个类的成员变量,或者已经生成的实例变量. 使用__dict__定义成员变量 在python中直接支持了__dict__.update()这样的方法来操作,避免了对locals().vars()
-
如何利用Python将html转为pdf、word文件
目录 前言 转 pdf 安装 pdfkit 库 安装 wkhtmltopdf 文件 url 生成 pdf 本地 html 文件生成 pdf 转 word 安装 pypandoc 库 安装 pandoc 软件 使用 补充:用python把pdf文件转换为word文件 总结 前言 在日常中有时需将 html 文件转换为 pdf.word 文件.网上免费的大多数不支持多个文件转换的情况,而且在转换几个后就开始收费了. 转 pdf 转 pdf 中使用 pdfkit 库,它可以让 web 网页直接转为 p
-
利用Python实现Windows定时关机功能
是最初的几个爬虫,让我认识了Python这个新朋友,虽然才刚认识了几天,但感觉有种莫名的默契感.每当在别的地方找不到思路,总能在Python找到解决的办法.自动关机,在平时下载大文件,以及跑程序的时候能用到的,刚才写了个windows自动关机的小程序,程序过于简单,就当是玩玩吧,当然还有很多可改进的地方.下面正文: #ui制作: 照旧,笔者由Qt制作完成需要的ui,包括label,label_2,label_3,lable_4,lineEdit,lineEdit_2,pushButton组件.
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常