详解python数据结构之栈stack
前言
栈(Stack)是一种运算受限的线性表。
按照先进后出(FILO,First In Last Out)的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶。栈只能在一端进行插入和删除操作。
文章内容包含:
(1)栈的基本格式
(2)压栈 push_stack
(3)出栈 pop_stack
(4)取栈顶 peek_stack
一、栈的基本格式
class Stack():
def __init__ (self,size):
self.size = size #栈空间大小
self.top = -1 #栈中进入一个数据 top 加 1
self.stack = []
def display_stack(self):#栈stack的打印
print(self.stack)
if __name__ == "__main__":
stack = Stack(5) #设定栈空间
stack.display_stack() #打印栈数据
二、进栈与压栈 push_stack
class Stack():
def __init__ (self,size):
self.size = size
self.top = -1
self.stack = [] #进栈数据列表
def display_stack(self):
print(self.stack)
def push_stack(self,data):
if len(self.stack ) >= self.size: #当数据数量大于设置的空间,则栈溢出
print("stack over flow!")
return
self.stack.append(data) #没有栈溢出就将数据追加到列表中
self.top += 1 #栈中每增加一个数据就加 1
if __name__ == "__main__":
stack = Stack(5)
stack.push_stack(0)
stack.push_stack(1)
stack.push_stack(2)
stack.push_stack(3)
stack.push_stack(4)
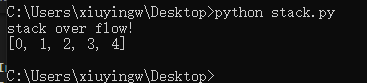
stack.push_stack(5) #stack空间是 5,这里进栈数据时 6 个,即提示栈溢出stack over flow!
stack.display_stack()
执行结果:
三、出栈 pop_stack
class Stack():
def __init__ (self,size):
self.size = size
self.top = -1
self.stack = [] #进栈数据列表
def display_stack(self):
print(self.stack)
def push_stack(self,data):
if len(self.stack ) >= self.size:
print("stack over flow!")
return
self.stack.append(data)
self.top += 1
def pop_stack(self):
if self.top <= -1: #当top小于等于初始值 -1 时说明stack数据列表为空
print("stack is empty!")
return
ret = self.stack.pop() #stack数据列表不为空就取出最后进的值,列表数据数量就少一个
self.top -= 1
return ret
if __name__ == "__main__":
stack = Stack(5)
stack.push_stack(0)
stack.push_stack(1)
stack.push_stack(2)
stack.push_stack(3)
stack.push_stack(4)
stack.display_stack()
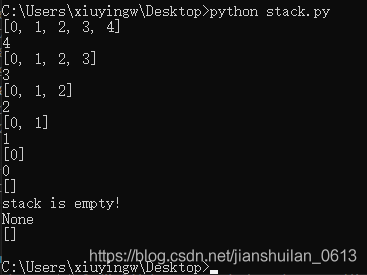
#进栈数据有 5 个,出栈函数调用了 6 次,就出现了提示stack is empty!
ret = stack.pop_stack()
print(ret)
stack.display_stack()
ret = stack.pop_stack()
print(ret)
stack.display_stack()
ret = stack.pop_stack()
print(ret)
stack.display_stack()
ret = stack.pop_stack()
print(ret)
stack.display_stack()
ret = stack.pop_stack()
print(ret)
stack.display_stack()
ret = stack.pop_stack()
print(ret)
stack.display_stack()
执行结果:
四、取栈顶 peek_stack
class Stack():
def __init__ (self,size):
self.size = size
self.top = -1
self.stack = []
def display_stack(self):
print(self.stack)
def push_stack(self,data):
if len(self.stack ) >= self.size:
print("stack over flow!")
return
self.stack.append(data)
self.top += 1
def peek_stack(self):
if self.top == -1: #当栈内没有数据时 提示 stack is empty!
print("stack is empty!")
return
peek = self.stack[self.top] #栈不为空时,将栈顶的数据提取出来
return peek
if __name__ == "__main__":
stack = Stack(5)
stack.push_stack(0)
stack.push_stack(1)
stack.push_stack(2)
stack.push_stack(3)
stack.push_stack(4)
stack.push_stack(5)
stack.display_stack()
peek = stack.peek_stack()
print(peek)
执行结果:

到此这篇关于详解python数据结构之栈stack的文章就介绍到这了,更多相关python 栈stack内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python学习之panda数据分析核心支持库
前言 Python是一门实现数据可视化很好的语言,他们里面的很多库可以很好的画出图形,形象明了. 今天我们就来说说:Pandas数据分析核心支持库 初识Pandas: Pandas 是 Python 语言的一个扩展程序库,用于数据分析. Pandas 是一个开放源码.BSD 许可的库,提供高性能.易于使用的数据结构和数据分析工具. Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分
-
python保存大型 .mat 数据文件报错超出 IO 限制的操作
python 保存 .mat 文件的大小是有限制的,似乎是 5G 以内,如果需要保存几十个 G 的数据的话,可以选用其他方式, 比如 h5 文件 import h5py def h5_data_write(train_data, train_label, test_data, test_label, shuffled_flag): print("h5py文件正在写入磁盘...") save_path = "../save_test/" + "train_t
-
python 存储json数据的操作
本篇我们将学习简单的json数据的存储 首先我们需要引入json模块: import json 这里我们模拟一个常见常见,我们让用户输入用户名.密码,在密码输入完成后提示用户再次输入密码来确认自己的输入,如果两次密码一致,那么我们将用户名和密码以json格式写入文件,否则提示用户再次输入密码. name = input("please enter your name:") password = input("please enter your password:")
-
Python入门之使用pandas分析excel数据
1.问题 在python中,读写excel数据方法很多,比如xlrd.xlwt和openpyxl,实际上限制比较多,不是很方便.比如openpyxl也不支持csv格式.有没有更好的方法? 2.方案 更好的方法可以使用pandas,虽然pandas不是专门处理excel数据,但处理excel数据确实很方便. 本文使用excel的数据来自网络,数据内容如下: 2.1.安装 使用pip进行安装. pip3 install pandas 导入pandas: import pandas as pd 下文使
-
Python基础之操作MySQL数据库
一.数据库操作 1.1 安装PyMySQL pip install PyMySQL 1.2 连接数据库 python连接test数据库 import pymysql host = 'localhost' # 主机地址 username = 'root' # 数据库用户名 password = '' # 数据库密码 db_name = 'test' # 数据库名称 # 创建connect对象 connect = pymysql.connect(host=host, user=username, p
-
python中必会的四大高级数据类型(字符,元组,列表,字典)
一. 字符串 生活中我们经常坐大巴车,每个座位一个编号,一个位置对应一个下标. 字符串中也有下标,要取出字符串中的部分数据,可以用下标取. python中使用切片来截取字符串其中的一段内容,切片截取的内容不包含结束下标对应的数据. 切片使用语法:[起始下标:结束下标:步长] ,步长指的是隔几个下标获取一个字符. 注意:下标会越界,切片不会 常用函数 练习: Test='rodma ' print(type(Test)) print('Test的一个字符串%s'%Test[0])#跟数组差不多 #
-
详解python数据结构之队列Queue
一.前言 队列Queue是一种先进先出(FIFO,First In First Out)的线性表.允许一端进行插入(rear),对应的另一段进行删除(front). 本篇包含以下内容: (1)Queue的基本格式 (2)入队列en_queue (3)删除数据函数 de_queue 二.Queue的基本格式 class Queue(): def __init__(self,size): self.size = size self.front = -1 #设置front初始值,每出队列一个数据就加
-
Python数据分析入门之数据读取与存储
一.图示 二.csv文件 1.读取csv文件read_csv(file_path or buf,usecols,encoding):file_path:文件路径,usecols:指定读取的列名,encoding:编码 data = pd.read_csv('d:/test_data/food_rank.csv',encoding='utf8') data.head() name num 0 酥油茶 219.0 1 青稞酒 95.0 2 酸奶 62.0 3 糌粑 16.0 4 琵琶肉 2.0 #指
-
python pickle存储、读取大数据量列表、字典数据的方法
先给大家介绍下python pickle存储.读取大数据量列表.字典的数据 针对于数据量比较大的列表.字典,可以采用将其加工为数据包来调用,减小文件大小 #列表 #存储 list1 = [123,'xiaopingguo',54,[90,78]] list_file = open('list1.pickle','wb') pickle.dump(list1,list_file) list_file.close() #读取 list_file = open('list1.pickle','rb')
-
Python数据分析入门之教你怎么搭建环境
一.Anaconda Anaconda(水蟒)是一个捆绑了Python.conda.其他相关依赖包的一个软件.包含了180多个可学计算包及其依赖.Anaconda3是集成了Python3的环境,Anaconda2是集成了Python2的环境.Anaconda默认集成的包,是属于内置的Python的包.并且支持绝大部分操作系统(比如:Windows.Mac.Linux等).下载地址如下:https://www.anaconda.com/distribution/(如果官网下载太慢,可以在清华大学开
-
python利用Excel读取和存储测试数据完成接口自动化教程
http_request2.py用于发起http请求 #读取多条测试用例 #1.导入requests模块 import requests #从 class_12_19.do_excel1导入read_data函数 from do_excel2 import read_data from do_excel2 import write_data from do_excel2 import count_case #定义http请求函数 COOKIE=None def http_request2(met