Python基础知识之变量的详解
一.定义
在python中,变量名只有在第一次出现的时候,才是定义变量。当再次出现时,不是定义变量,而是直接调用之前定义的变量。
二.命名方法
2.1小驼峰命名法
第一个单词以小写字母开始,后续单词的首字母大写
firstName , lastName
2.2大驼峰命名法
每一个单词的首字母都采用大写字母
FirstName , LastName
2.3下划线命名法
每个单词之间用下划线连接起来
first_name , last_name
三.命名规则
3.1标识符
开发人员自定义的一些符号和名称
如:变量名、函数名、类名
标识符命名规则
1.只能由数字、字母、下划线组成,且不能以数字开头
2.不能和python中的关键字重名
3.尽量做到见名知义
4.不能使用单字符(i,o)作为变量名,因为太像0和1了
5.函数首字母小写,类的首字母大写
3.2关键字
1.关键字就是在python内部已经使用的标识符
2.关键字具有特殊的功能和含义
3.开发者不允许定义和关键字相同的名字的标识符
注意:
1.命名规则可以被视为一种惯例,无绝对与强制,目的是为了增加代码的识别和可读性
2.python中的标识符是区分大小写的
3.在定义变量时,为了保证代码格式,遵循PEP8规范,等号(=)的左右两边该各保留一个空格
四.使用方法
4.1单变量赋值:
变量名 = 值
例:a = 1
在python中赋值语句总是建立对象的引用值,而不是复制对象。因此,python中的变量存储的是引用数据的内存地址,而不是数据存储区域。
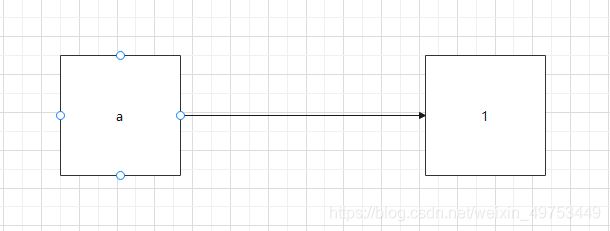
当涉及多个变量时:
a = 1 b = a c = b print(a) # 1 print(id(a)) # 140710098927888 print(b) # 1 print(id(b)) # 140710098927888 print(c) # 1 print(id(c)) # 140710098927888
a、b、c三个变量的值都等于1,即使在最初定义变量的时候b和c不是直接等于1的,但是他们仍然存储着指向“1”的内存地址。
4.2底层逻辑:
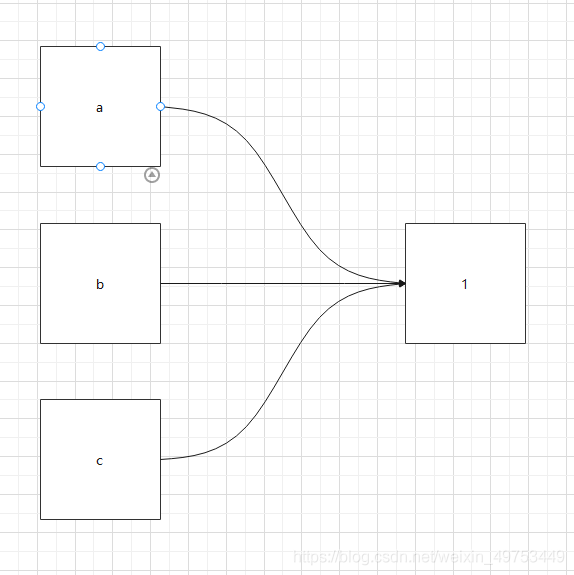
4.3总结:
可以说Python中没有赋值,只有引用。Python 没有“变量”,我们平时所说的变量其实只是“标签”,是引用。
当创建了无数个变量=1时,在内存中,只会开辟无数个空间存储变量,再开辟一个空间存储“1”,而这些变量中存储的内存地址都相同,全都指向“1”的内存地址。
在代码层面,看起来像是给变量赋值,但是在底层却是变量指向值,也就是变量引用了值。
相信大家还有疑问,那么请继续阅读
5.变量进阶
先提出一个问题:
a = [0, 1, 2] a[1] = a print(a)
猜想结果是:
[0, [0, 1, 2], 2]
但是真正的结果是:
[0, [...], 2]
为什么结果会赋值了无限次??
结合刚才得出的结论:Python中没有赋值,只有引用。
真相是:
这样相当于创建了一个引用自身的结构,所以导致了无限循环。
通过递归函数可能更好理解:
a = [0,1,2]
a[1] = a
def fun1(n1):
for i in n1:
if type(i) == list:
return fun1(n1)
else:
print(i)
print(fun1(a[1]))
结果:
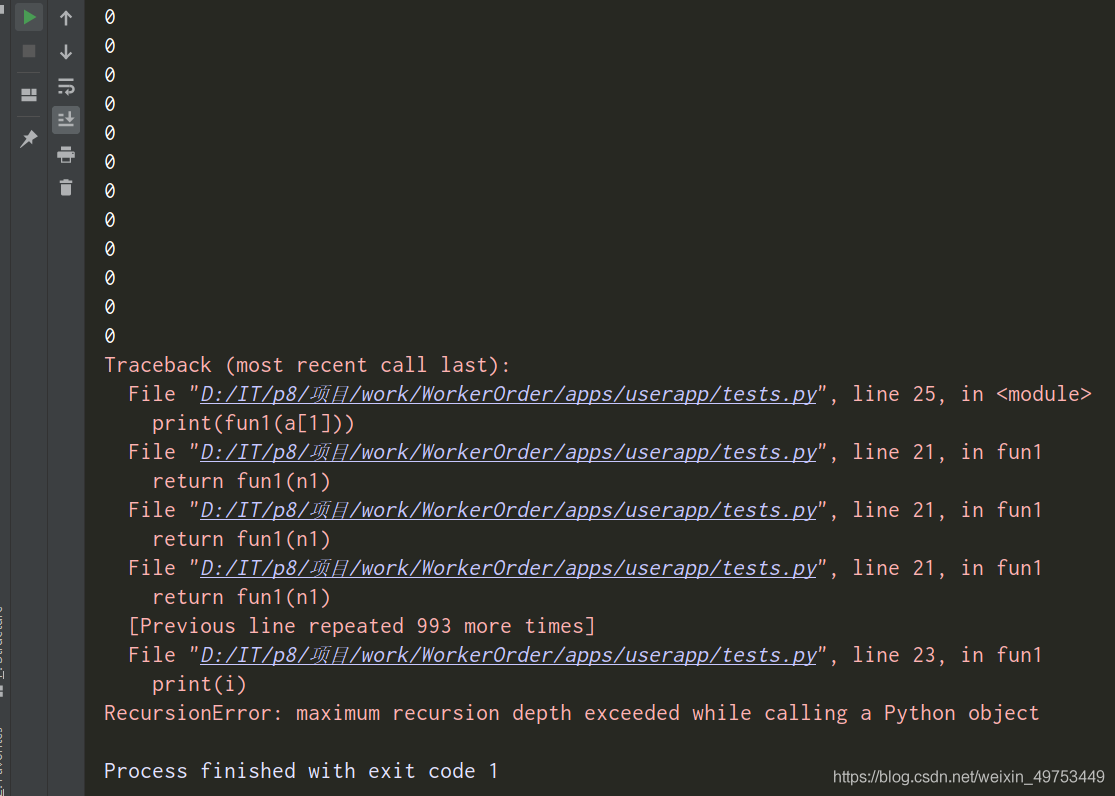
果然是:调用Python对象时超出最大递归深度。
底层逻辑:a[1] = a 造成了递归引用
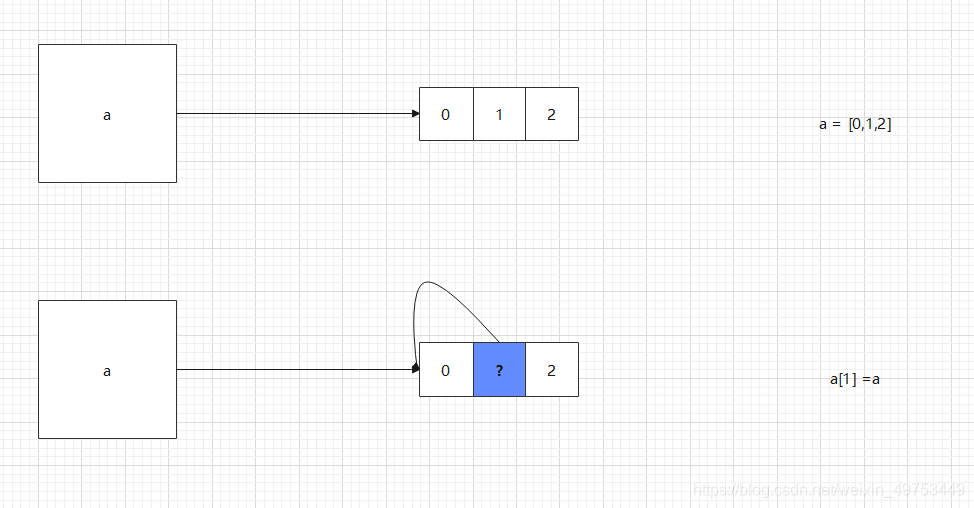
当调用变量a时,就是调用[0,1,2],此时 [0,1,2] 的结构变成了 [0,?,2] ,而 ? 又指向 [0,?,2] 本身,以此类推,造成了递归调用的情况。
所以在遍历a并输出的时候会引起超出最大递归深度的错误。
想得到 [0, [0, 1, 2], 2] 的结果并不难:
a = [0,1,2] a[1] = a[:] print(a) # [0, [0, 1, 2], 2]
a[:] = a[0:尾部索引值:1]
生成对象的浅拷贝或者是复制序列,不再是引用和共享变量,但此法只能顶层复制
6. a = a + 1 和 a += 1 的区别
既然谈到了赋值和引用的区别,那就捎带谈一下a = a + 1 和 a += 1 的区别:
直接上代码:
a = [1, 2]
b = a
print(id(a)) # 1878561149448
print(id(b)) # 1878561149448
a = a + [1, 2]
print(a, b) # [1, 2, 1, 2] [1, 2]
print(id(a)) # 1878593529288
print(id(b)) # 1878561149448
print ("-------------------")
a = [1, 2]
b = a
print(id(a)) # 1878561149960
print(id(b)) # 1878561149960
a += [1, 2]
print(a, b) # [1, 2, 1, 2] [1, 2, 1, 2]
print(id(a)) # 1878561149960
print(id(b)) # 1878561149960
通过对比发现问题:变量a通过“=” 和 “+=”运算,得到的变量b竟然是不同的,运算后变量a的id竟然也是不同的。
执行a = a + [1, 2] 后:
变量b指向的值并未发生改变,而变量a的id发生了变化,值也发生了变化
执行a += [1, 2] 后:
变量a和b的值都发生了改变,而二者的id却没有改变
具体原因,看图说话:
执行a = a + [1, 2] 后,会生成一个新对象,并在cpu上开辟一块空间存储 a + [1, 2] ,然后由a指向它。所以变量a的id发生了变化,值也发生了变化。此时变量b指向的值并未发生改变。
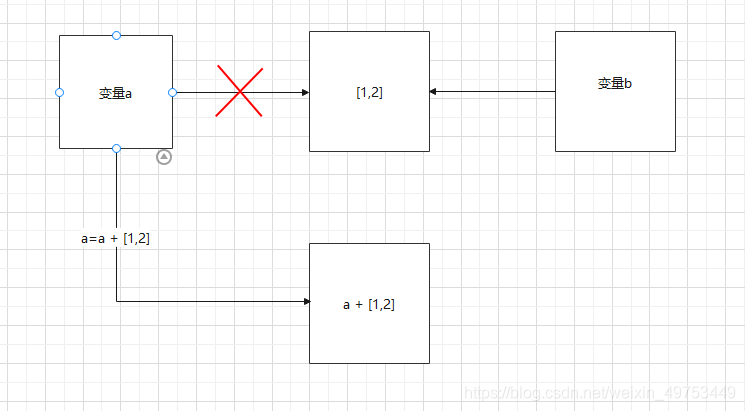
执行a += [1, 2] 后:并不会生成新对象,只是把a原本指向内存地址的对象的值改变成了 a + [1, 2],所以变量a和b的值都发生了改变,而二者的id却没有改变。

对于可变对象类型和不可变对象类型有不同的结果:
可变对象类型:+=改变了原本地址上对象的值,不改变原本的指向地址;=则改变了原本的指向地址,创建了新的对象,并指向新的地址
不可改变对象类型:都是改变原本的指向地址,指向新创建的对象地址
a = 'abc'
b = a
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
a = a + 'd'
print(a, b) # abcd abc
print(id(a)) # 1629835853168
print(id(b)) # 1629835782384
print ("-------------------")
a = 'abc'
b = a
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
a += 'd'
print(a, b) # abcd abc
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
到此这篇关于Python基础知识之变量的详解的文章就介绍到这了,更多相关python变量详解内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python基础知识(一)变量与简单数据类型详解
1.1变量 变量的命名规则: 1.只能包含字母.数字.下划线,且不能用数字开头 2.不能使用python关键字 3.简短且具有描述性 1.2字符串 python中用引号引起来的都是字符串,单引号双引号都可以 a.字符串的索引 s = 'ABCDEF' #索引 s1 = s[0] s2 = s[-1] s3 = s[0:4] print(s1) #A print(s2) #F print(s3) #ABC,左闭右开 #打印全部 s4 = s[:] #s[0:] print(s4) s5 = s[0
-

Python基础之高级变量类型实例详解
本文实例讲述了Python高级变量类型.分享给大家供大家参考,具体如下: 目标 列表 元组 字典 字符串 公共方法 变量高级 知识点回顾 Python 中数据类型可以分为 数字型 和 非数字型 数字型 整型 (int) 浮点型(float) 布尔型(bool) 真 True 非 0 数 -- 非零即真 假 False 0 复数型 (complex) 主要用于科学计算,例如:平面场问题.波动问题.电感电容等问题 非数字型 字符串 列表 元组 字典 在 Python 中,所有 非数字型变量 都支持以
-
python基础教程之简单入门说明(变量和控制语言使用方法)
简介有兴趣可以看看: 解释性语言+动态类型语言+强类型语言 交互模式:(主要拿来试验,可以试试 ipython) 复制代码 代码如下: $python>>> print 'hello world' 脚本 复制代码 代码如下: #!/usr/bin/env pythonprint 'hello world' 环境: 建议python2.7 + easy_install + pip + virtualenv + ipython 缩进Python 函数没有明显的 begin 和 end,没有标
-
python基础教程之基本数据类型和变量声明介绍
变量不需要声明 Python的变量不需要声明,你可以直接输入: 复制代码 代码如下: >>>a = 10 那么你的内存里就有了一个变量a, 它的值是10,它的类型是integer (整数). 在此之前你不需要做什么特别的声明,而数据类型是Python自动决定的. 复制代码 代码如下: >>>print a >>>print type(a) 那么会有如下输出: 复制代码 代码如下: 10 <type 'int'> 这里,我们学到一个内置函数t
-
Python基础之变量基本用法与进阶详解
本文实例讲述了Python基础之变量基本用法与进阶.分享给大家供大家参考,具体如下: 目标 变量的引用 可变和不可变类型 局部变量和全局变量 01. 变量的引用 变量 和 数据 都是保存在 内存 中的 在 Python 中 函数 的 参数传递 以及 返回值 都是靠 引用 传递的 1.1 引用的概念 在 Python 中 变量 和 数据 是分开存储的 数据 保存在内存中的一个位置 变量 中保存着数据在内存中的地址 变量 中 记录数据的地址,就叫做 引用 使用 id() 函数可以查看变量中保存数据所
-
Python基础知识之变量的详解
一.定义 在python中,变量名只有在第一次出现的时候,才是定义变量.当再次出现时,不是定义变量,而是直接调用之前定义的变量. 二.命名方法 2.1小驼峰命名法 第一个单词以小写字母开始,后续单词的首字母大写 firstName , lastName 2.2大驼峰命名法 每一个单词的首字母都采用大写字母 FirstName , LastName 2.3下划线命名法 每个单词之间用下划线连接起来 first_name , last_name 三.命名规则 3.1标识符 开发人员自定义的一些符号和
-
Python基础教程之pytest参数化详解
目录 前言 源代码分析 装饰测试类 装饰测试函数 单个数据 一组数据 组合数据 标记用例 嵌套字典 增加测试结果可读性 总结 前言 上篇博文介绍过,pytest是目前比较成熟功能齐全的测试框架,使用率肯定也不断攀升.在实际 工作中,许多测试用例都是类似的重复,一个个写最后代码会显得很冗余.这里,我们来了解一下 @pytest.mark.parametrize装饰器,可以很好的解决上述问题. 源代码分析 def parametrize(self,argnames, argvalues, indir
-
Vue 2.0入门基础知识之内部指令详解
1.Vue.js介绍 当前前端三大主流框架:Angular.React.Vue.React前段时间由于许可证风波,使得Vue的热度蹭蹭地上升.另外,Vue友好的API文档更是一大特色.Vue.js是一个非常轻量级的工具,与其说是一个MVVM框架,不如说是一个js库.Vue.js具有响应式编程和组件化的特点.响应式编程,即保持状态和视图的同步,状态也可以说是数据吧:而其组件化的理念与React则一样,即"一切都是组件,组件化思想方便于模块化的开发,是前端领域的一大趋势. 2.内部指令 2-1.v-
-
Java集合基础知识 List/Set/Map详解
一.List Set 区别 List 有序,可重复: Set 无序,不重复: 二.List Set 实现类间区别及原理 Arraylist 底层实现使用Object[],数组查询效率高 扩容机制 1.6采用(capacity * 3)/ 2 + 1,默认容量为10: 1.7采用(capacity >> 2 + capacity)实现,位移动效率高于数学运算,右移一位等于乘以2倍: 读取速度快,写入会涉及到扩容,所以相对较慢. LinkedList底层采用双向链表,只记录 first 和 las
-
Python基础必备之语法结构详解
目录 Python 语句 续行 隐式续行的方式 显式续行的方式 每行多语句 注释 空白字符 空格作为缩进 Python 语句 语句是 Python 解释器解析和处理的基本指令单元.通常解释器按顺序一个接一个的执行语句. 在 REPL 会话中,语句在输入时执行,直到解释器终止.当执行脚本文件时,解释器从文件中读取语句并执行直到遇到文件结尾. 通常每个语句占用一行,语句的结尾由标记行尾的换行符分隔. print('真・三國無双') 真・三國無双 x = ['劉備', '関羽','張飛'] print
-
Python基础Lists和tuple实例详解
目录 Lists 索引和切片 增删改 增 删除 改 连接/拼接 tuple 解包 元素是可变的仍然可变 namedtuple Lists 列表可以包含不同类型的元素,甚至是Lists,但是通常是同一个类型的. if __name__ == '__main__': squares = [1, 4, [1, 2], "whf", 25] print(squares) 索引和切片 列表支持使用下标索引元素,支持切片. if __name__ == '__main__': squares =
-
Python基础学习之基本数据结构详解【数字、字符串、列表、元组、集合、字典】
本文实例讲述了Python基础学习之基本数据结构.分享给大家供大家参考,具体如下: 前言 相比于PHP,Python同样也是脚本解析语言,所以在使用Python的时候,变量和数据结构相对于编译语言来说都会简单许多,但是Python相比于PHP来说,变量类型的定义会比较严格:string->int的转换没有PHP那么方便.但这也让程序稳定性有所提升,例如和客户端交互的时候,数据库取出来的数字int和缓存取出来的数字(默认是string)需要手动进行转换(否则会有报错提示),而PHP不需要手动转换的
-
Python基础之函数用法实例详解
本文以实例形式较为详细的讲述了Python函数的用法,对于初学Python的朋友有不错的借鉴价值.分享给大家供大家参考之用.具体分析如下: 通常来说,Python的函数是由一个新的语句编写,即def,def是可执行的语句--函数并不存在,直到Python运行了def后才存在. 函数是通过赋值传递的,参数通过赋值传递给函数 def语句将创建一个函数对象并将其赋值给一个变量名,def语句的一般格式如下: def <name>(arg1,arg2,arg3,--,argN): <stateme
-
Django基础知识 URL路由系统详解
MVC和MTV框架 MVC Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的.松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示: MTV Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值: M 代表模型(Model):
-
python基础之函数和面向对象详解
目录 函数 函数参数 变量作用域 内嵌函数和闭包 lambda 表达式 面向对象 三大特性 类.类对象 和 实例对象 类属性 和 对象属性 私有 魔法方法 基本的魔法方法 算术运算符 属性访问 描述符 迭代器和生成器 迭代器 生成器 总结 函数 python中『一切皆对象』, 函数也不例外. 在之前所学的C++或Java中, 可以发现函数的返回值要么为空, 要么是某种数据类型, 但是在python中, 返回值可以是任何对象, 包括函数. 函数参数 函数的参数种类比较多, 主要有: 1.位置参数