python 多维高斯分布数据生成方式
我就废话不多说了,直接上代码吧!
import numpy as np
import matplotlib.pyplot as plt
def gen_clusters():
mean1 = [0,0]
cov1 = [[1,0],[0,10]]
data = np.random.multivariate_normal(mean1,cov1,100)
mean2 = [10,10]
cov2 = [[10,0],[0,1]]
data = np.append(data,
np.random.multivariate_normal(mean2,cov2,100),
0)
mean3 = [10,0]
cov3 = [[3,0],[0,4]]
data = np.append(data,
np.random.multivariate_normal(mean3,cov3,100),
0)
return np.round(data,4)
def save_data(data,filename):
with open(filename,'w') as file:
for i in range(data.shape[0]):
file.write(str(data[i,0])+','+str(data[i,1])+'\n')
def load_data(filename):
data = []
with open(filename,'r') as file:
for line in file.readlines():
data.append([ float(i) for i in line.split(',')])
return np.array(data)
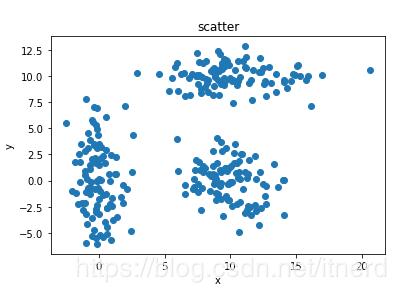
def show_scatter(data):
x,y = data.T
plt.scatter(x,y)
plt.axis()
plt.title("scatter")
plt.xlabel("x")
plt.ylabel("y")
data = gen_clusters()
save_data(data,'3clusters.txt')
d = load_data('3clusters.txt')
show_scatter(d)
以上这篇python 多维高斯分布数据生成方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python使用numpy产生正态分布随机数的向量或矩阵操作示例
本文实例讲述了Python使用numpy产生正态分布随机数的向量或矩阵操作.分享给大家供大家参考,具体如下: 简单来说,正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力.一般的正态分布可以通过标准正态分布配合数学期望向量和协方差矩阵得到.如下代码,可以得到满足一维和二维正态分布的样本. 示例1(一维正态分布): # coding=utf-8 '''
-
python实现高斯(Gauss)迭代法的例子
我就废话不多说了,直接上代码大家一起看吧! #Gauss迭代法 输入系数矩阵mx.值矩阵mr.迭代次数n(以list模拟矩阵 行优先) def Gauss(mx,mr,n=100): if len(mx) == len(mr): #若mx和mr长度相等则开始迭代 否则方程无解 x = [] #迭代初值 初始化为单行全0矩阵 for i in range(len(mr)): x.append([0]) count = 0 #迭代次数计数 while count < n: for i in rang
-
在python中画正态分布图像的实例
1.正态分布简介 正态分布(normal distribtution)又叫做高斯分布(Gaussian distribution),是一个非常重要也非常常见的连续概率分布.正态分布大家也都非常熟悉,下面做一些简单的介绍. 假设随机变量XX服从一个位置参数为μμ.尺度参数为σσ的正态分布,则可以记为: 而概率密度函数为 2.在python中画正态分布直方图 先直接上代码 import numpy as np import matplotlib.mlab as mlab import matplot
-
Python求解正态分布置信区间教程
正态分布和置信区间 正态分布(Normal Distribution)又叫高斯分布,是一种非常重要的概率分布.其概率密度函数的数学表达如下: 置信区间是对该区间能包含未知参数的可置信的程度的描述. 使用SciPy求解置信区间 import numpy as np import matplotlib.pyplot as plt from scipy import stats N = 10000 x = np.random.normal(0, 1, N) # ddof取值为1是因为在统计学中样本的标
-
python实现高斯判别分析算法的例子
高斯判别分析算法(Gaussian discriminat analysis) 高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客).在这个算法中,我们假设p(x|y)p(x|y)服从多元正态分布. 注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所以对于XX的条件概率建模时要取多维正态分布. 多元正态分布 多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn
-
Python数据可视化正态分布简单分析及实现代码
Python说来简单也简单,但是也不简单,尤其是再跟高数结合起来的时候... 正态分布(Normaldistribution),也称"常态分布",又名高斯分布(Gaussiandistribution),最早由A.棣莫弗在求二项分布的渐近公式中得到.C.F.高斯在研究测量误差时从另一个角度导出了它.P.S.拉普拉斯和高斯研究了它的性质.是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力. 正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人
-
python 多维高斯分布数据生成方式
我就废话不多说了,直接上代码吧! import numpy as np import matplotlib.pyplot as plt def gen_clusters(): mean1 = [0,0] cov1 = [[1,0],[0,10]] data = np.random.multivariate_normal(mean1,cov1,100) mean2 = [10,10] cov2 = [[10,0],[0,1]] data = np.append(data, np.random.mu
-
Python多维/嵌套字典数据无限遍历的实现
最近拾回Django学习,实例练习中遇到了对多维字典类型数据的遍历操作问题,Google查询没有相关资料-毕竟是新手,到自己动手时发现并非想象中简单,颇有两次曲折才最终实现效果,将过程记录下来希望对大家有用. 实例数据(多重嵌套): person = {"male":{"name":"Shawn"}, "female":{"name":"Betty","age":23
-
Python 图像处理: 生成二维高斯分布蒙版的实例
在图像处理以及图像特效中,经常会用到一种成高斯分布的蒙版,蒙版可以用来做图像融合,将不同内容的两张图像结合蒙版,可以营造不同的艺术效果. 这里II 表示合成后的图像,FF 表示前景图,BB 表示背景图,MM 表示蒙版,或者直接用 蒙版与图像相乘, 形成一种渐变映射的效果.如下所示. 这里介绍一下高斯分布蒙版的特性,并且用Python实现. 高斯分布的蒙版,简单来说,就是一个从中心扩散的亮度分布图,如下所示: 亮度的范围从 1 到 0, 从中心到边缘逐渐减弱,中心的亮度值最高为1,边缘的亮度值最低
-
Python机器学习入门(三)数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来. 从纯文本格式文件 "file_in"中读取数据,格式如下: 需要输出成"file_out",格式如下: 数据的原格式是"类别:内容",以空行"\n"为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容. 建议读取后,使用pandas,把数据建立称DataFrame的表格.这样方便以后处理数据.但是原格式并不是通常的表格格式,所以要先做一些简单的处理
-
基于python 二维数组及画图的实例详解
1.二维数组取值 注:不管是二维数组,还是一维数组,数组里的数据类型要一模一样,即若是数值型,全为数值型 #二维数组 import numpy as np list1=[[1.73,1.68,1.71,1.89,1.78], [54.4,59.2,63.6,88.4,68.7]] list3=[1.73,1.68,1.71,1.89,1.78] list4=[54.4,59.2,63.6,88.4,68.7] list5=np.array([1.73,1.68,1.71,1.89,1.78])
-
python 读入多行数据的实例
一.前言 本文主要使用python 的raw_input() 函数读入多行不定长的数据,输入结束的标志就是不输入数字情况下直接回车,并填充特定的数作为二维矩阵 二.代码 def get2DlistData(): res = [] inputLine = raw_input() #以字符串的形式读入一行 #如果不为空字符串作后续读入 while inputLine != '': listLine = inputLine.split(' ') #以空格划分就是序列的形式了 listLine = [i
-
python二维码操作:对QRCode和MyQR入门详解
python是所有编程语言中模块最丰富的 生活中常见的二维码功能在使用python第三方库来生成十分容易 三个大矩形是定位图案,用于标记二维码的大小.这三个定位图案有白边,通过这三个矩形就可以标识一个二维码了. QRCode 生成这个二维码只用一行 import qrcode qrcode.make("不睡觉干嘛呢").get_image().show() #设置URL必须添加http:// 安装导入QRCode pip install qrcode #方法多,体量小 安装导入MyQR
-
python 二维数组90度旋转的方法
如下所示: #!/usr/bin/env python #-*- coding: utf-8 -*- """ [0, 1, 2, 3] [0, 1, 2, 3] [0, 1, 2, 3] [0, 1, 2, 3] 2维数组顺时针90度旋转后结果如下 [0, 0, 0, 0] [1, 1, 1, 1] [2, 2, 2, 2] [3, 3, 3, 3] [0][1] <==> [1][0] [0][2] <==> [2][0] [0][3] <==
-
python实现维吉尼亚算法
本文实例为大家分享了python实现维吉尼亚算法的具体代码,供大家参考,具体内容如下 1 Virginia加密算法.解密算法 Vigenenre密码是最著名的多表代换密码,是法国著名密码学家Vigenenre发明的.Vigenenre密码使用一个词组作为密钥,密钥中每一个字母用来确定一个代换表,每一个密钥字母被用来加密一个明文字母,第一个密钥字母加密第一个明文字母,第二个密钥字母加密第二个明文字母,等所有密钥字母使用完后,密钥再次循环使用,于是加解密前需先将明密文按照密钥长度进行分组. 密码算法