pytorch查看torch.Tensor和model是否在CUDA上的实例
今天训练faster R-CNN时,发现之前跑的很好的程序(是指在运行程序过程中,显卡利用率能够一直维持在70%以上),今天看的时候,显卡利用率很低,所以在想是不是我的训练数据torch.Tensor或者模型model没有加载到GPU上训练,于是查找如何查看tensor和model所在设备的命令。
import torch import torchvision.models as models model=models.vgg11(pretrained=False) print(next(model.parameters()).is_cuda)#False data=torch.ones((5,10)) print(data.device)#cpu
上述是我在自己的笔记本上(显然没有GPU)的打印情况。
上次被老板教授了好久,出现西安卡利用率一直很低的情况千万不能认为它不是问题,而一定要想办法解决。比如可以在加载训练图像的过程中(__getitem__方法中)设定数据增强过程中每个步骤的时间点,对每个步骤的时间点进行打印,判断花费时间较多的是哪些步骤,然后尝试对代码进行优化,因为torhc.utils.data中的__getitem__方法是由CPU上的一个num_workers执行一遍的,如果__getitem__方法执行太慢,则会导致IO速度变慢,即GPU在大多数时间都处于等待CPU读取数据并处理成torch.cuda.tensor的过程,一旦CPU读取一个batch size的数据完毕,GPU很快就计算结束,从而看到的现象是:GPU在绝大多数时间都处于利用率很低的状态。
所以我总结的是,如果GPU显卡利用率比较低,最可能的就是CPU数据IO耗费时间太多(我之前就是由于数据增强的裁剪过程为了裁剪到object使用了for循环,导致这一操作很耗时间),还有可能的原因是数据tensor或者模型model根本就没有加载到GPU cuda上面。其实还有一种可能性很小的原因就是,在网络前向传播的过程中某些特殊的操作对GPU的利用率不高,当然指的是除了网络(卷积,全连接)操作之外的其他的对于tensor的操作,比如我之前的faster R-CNN显卡利用率低就是因为RPN中的NMS算法速度太慢,大约2-3秒一张图,虽然这时候tensor特征图在CUDA上面,而且NMS也使用了CUDA kernel编译后的代码,也就是说NMS的计算仍然是利用的CPU,但是由于NMS算法并行度不高,所以对于GPU的利用不多,导致了显卡利用率低,之前那个是怎么解决的呢?
哈哈,说到底还是环境的问题非常重要,之前的faster R-CNN代码在python2 CUDA9.0 pytorch 0.4.0 环境下编译成功我就没有再仔细纠结环境问题,直接运行了,直到后来偶然换成python3 CUDA9.0 pytorch 0.4.1 环境才极大地提高了显卡利用率,并且通过设置了几十个打印时间点之后发现,真的就是NMS的速度现在基本能维持在0.02-0.2数量级范围内。
下图分别表示之前(显卡利用率很低)时的NMS处理单张图像所消耗的时间(之所以会有长有短是因为我支持不同分辨率的图像训练),后面一张图是GPU利用率一直能维持在很高的情况下NMS处理时间,由于数据增强部分的代码完全没有修改,故而换了环境之后我就没有再打印数据增强每个步骤所消耗的时间了。
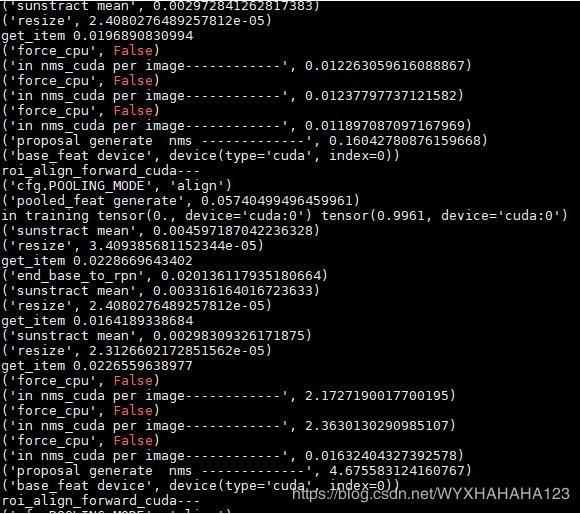
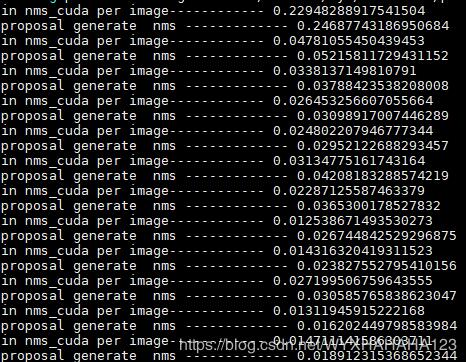
以上这篇pytorch查看torch.Tensor和model是否在CUDA上的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在pytorch中为Module和Tensor指定GPU的例子
pytorch指定GPU 在用pytorch写CNN的时候,发现一运行程序就卡住,然后cpu占用率100%,nvidia-smi 查看显卡发现并没有使用GPU.所以考虑将模型和输入数据及标签指定到gpu上. pytorch中的Tensor和Module可以指定gpu运行,并且可以指定在哪一块gpu上运行,方法非常简单,就是直接调用Tensor类和Module类中的 .cuda() 方法. import torch from PIL import Image import torch.nn as
-
pytorch查看torch.Tensor和model是否在CUDA上的实例
今天训练faster R-CNN时,发现之前跑的很好的程序(是指在运行程序过程中,显卡利用率能够一直维持在70%以上),今天看的时候,显卡利用率很低,所以在想是不是我的训练数据torch.Tensor或者模型model没有加载到GPU上训练,于是查找如何查看tensor和model所在设备的命令. import torch import torchvision.models as models model=models.vgg11(pretrained=False) print(next(mod
-
PyTorch中torch.tensor与torch.Tensor的区别详解
PyTorch最近几年可谓大火.相比于TensorFlow,PyTorch对于Python初学者更为友好,更易上手. 众所周知,numpy作为Python中数据分析的专业第三方库,比Python自带的Math库速度更快.同样的,在PyTorch中,有一个类似于numpy的库,称为Tensor.Tensor自称为神经网络界的numpy. 一.numpy和Tensor二者对比 对比项 numpy Tensor 相同点 可以定义多维数组,进行切片.改变维度.数学运算等 可以定义多维数组,进行切片.改变
-
pytorch中torch.max和Tensor.view函数用法详解
torch.max() 1. torch.max()简单来说是返回一个tensor中的最大值. 例如: >>> si=torch.randn(4,5) >>> print(si) tensor([[ 1.1659, -1.5195, 0.0455, 1.7610, -0.2064], [-0.3443, 2.0483, 0.6303, 0.9475, 0.4364], [-1.5268, -1.0833, 1.6847, 0.0145, -0.2088], [-0.86
-
Pytorch中的modle.train,model.eval,with torch.no_grad解读
目录 modle.train,model.eval,with torch.no_grad解读 model.eval()与torch.no_grad()的作用 model.eval() torch.no_grad() 异同 总结 modle.train,model.eval,with torch.no_grad解读 1. 最近在学习pytorch过程中遇到了几个问题 不理解为什么在训练和测试函数中model.eval(),和model.train()的区别,经查阅后做如下整理 一般情况下,我们训练
-
pytorch查看模型weight与grad方式
在用pdb debug的时候,有时候需要看一下特定layer的权重以及相应的梯度信息,如何查看呢? 1. 首先把你的模型打印出来,像这样 2. 然后观察到model下面有module的key,module下面有features的key, features下面有(0)的key,这样就可以直接打印出weight了,在pdb debug界面输入p model.module.features[0].weight,就可以看到weight,输入 p model.module.features[0].weig
-

pytorch查看网络参数显存占用量等操作
1.使用torchstat pip install torchstat from torchstat import stat import torchvision.models as models model = models.resnet152() stat(model, (3, 224, 224)) 关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数.我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数. 2.使用torchsummary pip in
-
pytorch查看通道数 维数 尺寸大小方式
查看tensor x.shape # 尺寸 x.size() # 形状 x.ndim # 维数 例如 import torch parser = argparse.ArgumentParser(description='PyTorch') parser.add_argument('--img_w', default=144, type=int, metavar='imgw', help='img width') parser.add_argument('--img_h', default=288
-
pytorch cuda上tensor的定义 以及减少cpu的操作详解
cuda上tensor的定义 a = torch.ones(1000,1000,3).cuda() 某一gpu上定义 cuda1 = torch.device('cuda:1') b = torch.randn((1000,1000,1000),device=cuda1) 删除某一变量 del a 在cpu定义tensor然后转到gpu torch.zeros().cuda() 直接在gpu上定义,这样就减少了cpu的损耗 torch.cuda.FloatTensor(batch_size, s
-
pytorch Variable与Tensor合并后 requires_grad()默认与修改方式
pytorch更新完后合并了Variable与Tensor torch.Tensor()能像Variable一样进行反向传播的更新,返回值为Tensor Variable自动创建tensor,且返回值为Tensor,(所以以后不需要再用Variable) Tensor创建后,默认requires_grad=Flase 可以通过xxx.requires_grad_()将默认的Flase修改为True 下面附代码及官方文档代码: import torch from torch.autograd im
-
Pytorch中torch.flatten()和torch.nn.Flatten()实例详解
torch.flatten(x)等于torch.flatten(x,0)默认将张量拉成一维的向量,也就是说从第一维开始平坦化,torch.flatten(x,1)代表从第二维开始平坦化. import torch x=torch.randn(2,4,2) print(x) z=torch.flatten(x) print(z) w=torch.flatten(x,1) print(w) 输出为: tensor([[[-0.9814, 0.8251], [ 0.8197, -1.0426], [-