回归预测分析python数据化运营线性回归总结
目录
- 内容介绍
- 一般应用场景
- 线性回归的常用方法
- 线性回归实现
- 线性回归评估指标
- 线性回归效果可视化
- 数据预测
内容介绍
以 Python 使用 线性回归 简单举例应用介绍回归分析。
线性回归是利用线性的方法,模拟因变量与一个或多个自变量之间的关系;
对于模型而言,自变量是输入值,因变量是模型基于自变量的输出值,适用于x和y满足线性关系的数据类型的应用场景。
用于预测输入变量和输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值也随之发生变化。
回归模型正是表示从输入变量到输出变量之间映射的函数。
线性回归几乎是最简单的模型了,它假设因变量和自变量之间是线性关系的,一条直线简单明了。
一般应用场景
连续性数据的预测:例如房价预测、销售额度预测、贷款额度预测。
简单来说就是用历史的连续数据去预测未来的某个数值。
线性回归的常用方法
最小二乘法、贝叶斯岭回归、弹性网络回归、支持向量机回归、支持向量机回归等。
线性回归实现
import numpy as np # numpy库
from sklearn.linear_model import BayesianRidge, LinearRegression, ElasticNet,Lasso # 批量导入要实现的回归算法
from sklearn.svm import SVR # SVM中的回归算法
from sklearn.ensemble.gradient_boosting import GradientBoostingRegressor # 集成算法
from sklearn.model_selection import cross_val_score # 交叉检验
from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score # 批量导入指标算法
import pandas as pd # 导入pandas
import matplotlib.pyplot as plt # 导入图形展示库
import random
# 随机生成100组包含5组特征的数据
feature = [[random.random(),random.random(),random.random(),random.random(),random.random()] for i in range(100)]
dependent = [round(random.uniform(1,100),2) for i in range(100)]
# 训练回归模型
n_folds = 6 # 设置交叉检验的次数
model_br = BayesianRidge() # 建立贝叶斯岭回归模型对象
model_lr = LinearRegression() # 建立普通线性回归模型对象
model_etc = ElasticNet() # 建立弹性网络回归模型对象
model_svr = SVR() # 建立支持向量机回归模型对象
model_la = Lasso() # 建立支持向量机回归模型对象
model_gbr = GradientBoostingRegressor() # 建立梯度增强回归模型对象
model_names = ['BayesianRidge', 'LinearRegression', 'ElasticNet', 'SVR', 'Lasso','GBR'] # 不同模型的名称列表
model_dic = [model_br, model_lr, model_etc, model_svr,model_la, model_gbr] # 不同回归模型对象的集合
cv_score_list = [] # 交叉检验结果列表
pre_y_list = [] # 各个回归模型预测的y值列表
for model in model_dic: # 读出每个回归模型对象
scores = cross_val_score(model, feature, dependent, cv=n_folds) # 将每个回归模型导入交叉检验模型中做训练检验
cv_score_list.append(scores) # 将交叉检验结果存入结果列表
pre_y_list.append(model.fit(feature, dependent).predict(feature)) # 将回归训练中得到的预测y存入列表
线性回归评估指标
model_gbr:拟合贝叶斯岭模型,以及正则化参数lambda(权重的精度)和alpha(噪声的精度)的优化。
model_lr:线性回归拟合系数w=(w1,…)的线性模型,wp)将观测到的目标与线性近似预测的目标之间的残差平方和降到最小。
model_etc:以L1和L2先验组合为正则元的线性回归。
model_svr:线性支持向量回归。
model_la:用L1先验作为正则化器(又称Lasso)训练的线性模型
# 模型效果指标评估
model_metrics_name = [explained_variance_score, mean_absolute_error, mean_squared_error, r2_score] # 回归评估指标对象集
model_metrics_list = [] # 回归评估指标列表
for i in range(6): # 循环每个模型索引
tmp_list = [] # 每个内循环的临时结果列表
for m in model_metrics_name: # 循环每个指标对象
tmp_score = m(dependent, pre_y_list[i]) # 计算每个回归指标结果
tmp_list.append(tmp_score) # 将结果存入每个内循环的临时结果列表
model_metrics_list.append(tmp_list) # 将结果存入回归评估指标列表
df1 = pd.DataFrame(cv_score_list, index=model_names) # 建立交叉检验的数据框
df2 = pd.DataFrame(model_metrics_list, index=model_names, columns=['ev', 'mae', 'mse', 'r2']) # 建立回归指标的数据框


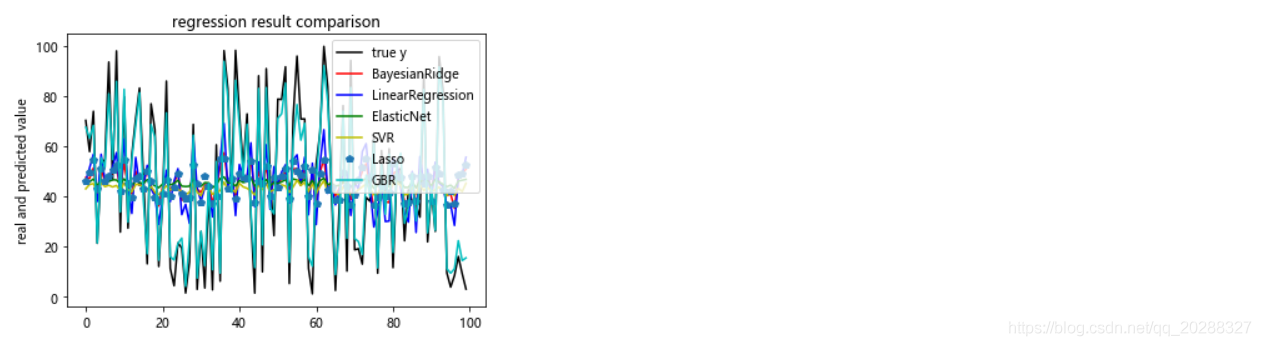
线性回归效果可视化
# 模型效果可视化
plt.figure() # 创建画布
plt.plot(np.arange(len(feature)), dependent, color='k', label='true y') # 画出原始值的曲线
color_list = ['r', 'b', 'g', 'y', 'p','c'] # 颜色列表
linestyle_list = ['-', '.', 'o', 'v',':', '*'] # 样式列表
for i, pre_y in enumerate(pre_y_list): # 读出通过回归模型预测得到的索引及结果
plt.plot(np.arange(len(feature)), pre_y_list[i], color_list[i], label=model_names[i]) # 画出每条预测结果线
plt.title('regression result comparison') # 标题
plt.legend(loc='upper right') # 图例位置
plt.ylabel('real and predicted value') # y轴标题
plt.show() # 展示图像
数据预测
# 模型应用
new_point_set = [[random.random(),random.random(),random.random(),random.random(),random.random()],
[random.random(),random.random(),random.random(),random.random(),random.random()],
[random.random(),random.random(),random.random(),random.random(),random.random()],
[random.random(),random.random(),random.random(),random.random(),random.random()]] # 要预测的新数据集
print("贝叶斯岭回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_gbr.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("普通线性回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_lr.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("弹性网络回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_etc.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("支持向量机回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_svr.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("拉索回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_la.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息

以上就是回归预测分析python数据化运营线性回归总结的详细内容,更多关于python数据化运营线性回归的资料请关注我们其它相关文章!
相关推荐
-

8种用Python实现线性回归的方法对比详解
前言 说到如何用Python执行线性回归,大部分人会立刻想到用sklearn的linear_model,但事实是,Python至少有8种执行线性回归的方法,sklearn并不是最高效的. 今天,让我们来谈谈线性回归.没错,作为数据科学界元老级的模型,线性回归几乎是所有数据科学家的入门必修课.抛开涉及大量数统的模型分析和检验不说,你真的就能熟练应用线性回归了么?未必! 在这篇文章中,文摘菌将介绍8种用Python实现线性回归的方法.了解了这8种方法,就能够根据不同需求,灵活选取最为高效的方法实现线
-
如何在python中实现线性回归
线性回归是基本的统计和机器学习技术之一.经济,计算机科学,社会科学等等学科中,无论是统计分析,或者是机器学习,还是科学计算,都有很大的机会需要用到线性模型.建议先学习它,然后再尝试更复杂的方法. 本文主要介绍如何逐步在Python中实现线性回归.而至于线性回归的数学推导.线性回归具体怎样工作,参数选择如何改进回归模型将在以后说明. 回归 回归分析是统计和机器学习中最重要的领域之一.有许多可用的回归方法.线性回归就是其中之一.而线性回归可能是最重要且使用最广泛的回归技术之一.这是最简单的回归方法之
-
Python编程实现使用线性回归预测数据
本文中,我们将进行大量的编程--但在这之前,我们先介绍一下我们今天要解决的实例问题. 1) 预测房子价格 房价大概是我们中国每一个普通老百姓比较关心的问题,最近几年保障啊,小编这点微末工资着实有点受不了. 我们想预测特定房子的价值,预测依据是房屋面积. 2) 预测下周哪个电视节目会有更多的观众 闪电侠和绿箭侠是我最喜欢的电视节目,特别是绿箭侠,当初追的昏天黑地的,不过后来由于一些原因,没有接着往下看.我想看看下周哪个节目会有更多的观众. 3) 替换数据集中的缺失值 我们经常要和带有缺失值的数据集
-
python实现简单的单变量线性回归方法
线性回归是机器学习中的基础算法之一,属于监督学习中的回归问题,算法的关键在于如何最小化代价函数,通常使用梯度下降或者正规方程(最小二乘法),在这里对算法原理不过多赘述,建议看吴恩达发布在斯坦福大学上的课程进行入门学习. 这里主要使用python的sklearn实现一个简单的单变量线性回归. sklearn对机器学习方法封装的十分好,基本使用fit,predict,score,来训练,预测,评价模型, 一个简单的事例如下: from pandas import DataFrame from pan
-
回归预测分析python数据化运营线性回归总结
目录 内容介绍 一般应用场景 线性回归的常用方法 线性回归实现 线性回归评估指标 线性回归效果可视化 数据预测 内容介绍 以 Python 使用 线性回归 简单举例应用介绍回归分析. 线性回归是利用线性的方法,模拟因变量与一个或多个自变量之间的关系: 对于模型而言,自变量是输入值,因变量是模型基于自变量的输出值,适用于x和y满足线性关系的数据类型的应用场景. 用于预测输入变量和输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值也随之发生变化. 回归模型正是表示从输入变量到输出变量之
-
总结分析python数据化运营关联规则
目录 内容介绍 一般应用场景 关联规则实现 关联规则应用举例 内容介绍 以 Python 使用 关联规则 简单举例应用关联规则分析. 关联规则 也被称为购物篮分析,用于分析数据集各项之间的关联关系. 一般应用场景 关联规则分析:最早的案例啤酒和尿布:据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起:结果这两个品类的销量都有明显的增长:分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品.
-
分析总结Python数据化运营KMeans聚类
内容介绍 以 Python 使用 Keans 进行聚类分析的简单举例应用介绍聚类分析. 聚类分析 或 聚类 是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上). 它是探索性数据挖掘的主要任务,也是统计数据分析的常用技术,用于许多领域,包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算机图形学. 一般应用场景 目标用户的群体分类: 根据运营或商业目的挑选出来的变量,对目标群体进行聚类,将目标群体分成几个有明显
-
python数据化运营的重要意义
python数据化运营 数据化运营的核心是运营,所有数据工作都是围绕运营工作链条展开的,逐步强化数据对于运营工作的驱动作用.数据化运营的价值体现在对运营的辅助.提升和优化上,甚至某些运营工作已经逐步数字化.自动化.智能化. 具体来说,数据化运营的意义如下: 1)提高运营决策效率.在信息瞬息万变的时代,抓住转瞬即逝的机会对企业而言至关重要.决策效率越高意味着可以在更短的时间内做出决策,从而跟上甚至领先竞争对手.数据化运营可使辅助决策更便捷,使数据智能引发主动决策思考,从而提前预判决策时机,并提高决
-
Python 数据化运营之KMeans聚类分析总结
目录 Python 数据化运营 1.内容介绍 2.一般应用场景 3.聚类的常见方法 4.Keans聚类实现 5.聚类的评估指标 6.聚类效果可视化 7.数据预测 Python 数据化运营 1.内容介绍 以 Python 使用 Keans 进行聚类分析的简单举例应用介绍聚类分析. 聚类分析 或 聚类 是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上).它是探索性数据挖掘的主要任务,也是统计数据分析的常用技术,用于许多领域,包括机
-
Python 机器学习之线性回归详解分析
为了检验自己前期对机器学习中线性回归部分的掌握程度并找出自己在学习中存在的问题,我使用C语言简单实现了单变量简单线性回归. 本文对自己使用C语言实现单变量线性回归过程中遇到的问题和心得做出总结. 线性回归 线性回归是机器学习和统计学中最基础和最广泛应用的模型,是一种对自变量和因变量之间关系进行建模的回归分析. 代码概述 本次实现的线性回归为单变量的简单线性回归,模型中含有两个参数:变量系数w.偏置q. 训练数据为自己使用随机数生成的100个随机数据并将其保存在数组中.采用批量梯度下降法训练模型,
-
如何用Python徒手写线性回归
对于大多数数据科学家而言,线性回归方法是他们进行统计学建模和预测分析任务的起点.这种方法已经存在了 200 多年,并得到了广泛研究,但仍然是一个积极的研究领域.由于良好的可解释性,线性回归在商业数据上的用途十分广泛.当然,在生物数据.工业数据等领域也不乏关于回归分析的应用. 另一方面,Python 已成为数据科学家首选的编程语言,能够应用多种方法利用线性模型拟合大型数据集显得尤为重要. 如果你刚刚迈入机器学习的大门,那么使用 Python 从零开始对整个线性回归算法进行编码是一次很有意义的尝试,
-
python数据分析之线性回归选择基金
目录 1 前言 2 基金趋势分析 3 数据抓取与分析 3.1 基金数据抓取 3.2 数据分析 4 总结 1 前言 在前面的章节中我们牛刀小试,一直在使用python爬虫去抓取数据,然后把数据信息存放在数据库中,至此已经完成了基本的基本信息的处理,接下来就来处理高级一点儿的内容,今天就从基金的趋势分析开始. 2 基金趋势分析 基金的趋势,就是选择一些表现强势的基金,什么样的才是强势呢?那就是要稳定的,逐步的一路北上.通常情况下,基金都会沿着一条趋势线向上或者向下,基金的趋势形成比股票的趋势更加确定
-
Python编程实现线性回归和批量梯度下降法代码实例
通过学习斯坦福公开课的线性规划和梯度下降,参考他人代码自己做了测试,写了个类以后有时间再去扩展,代码注释以后再加,作业好多: import numpy as np import matplotlib.pyplot as plt import random class dataMinning: datasets = [] labelsets = [] addressD = '' #Data folder addressL = '' #Label folder npDatasets = np.zer
-
分析Python读取文件时的路径问题
Python在读取文件内容时的路径问题,值得深究一下.我想讨论的重点还是在绝对路径上面.在这之前我们先看一下 1:相对路径 这张图演示了在相对路径下寻找查找指定文件. open('相对路径演示'\'相对路径示例'.txt)打开的是相对当前运行的程序所在目录. 而我当前运行的程序相对位置在桌面. 所以直接print(lines) 可以看到这个结果 2:绝对路径. 绝对路径的查找方法就不演示了,相信每个人都会找到.但是我想讨论的是几个关于路径中的编码问题,相信这对初学者们有很大的帮助. 2.1:你