python清洗疫情历史数据的过程详解
目录
- 1. 数据获取
- 2. 使用python读取csv
- 3.使用pyhon进行数据清洗
- 4. 将清洗的数据自动导入MySql
在我2020年大三的一个实训的大作业中,我整了一个新冠肺炎疫情的数据采集和可视化分析系统,大致就是先找数据,然后将数据导入hive中,然后使用hive对数据进行清洗,然后将清洗后的数据使用hql导入MySql,之后就是用ssm开发后台数据接口,然后前端使用echarts和表格对数据进行可视化。具体可以查看:https://qkongtao.cn/?p=514。由于那时候主要要求使用hive处理数据,但那时的数据是来自于某位大佬的数据接口中获取的,最后用hive处理再导入数据库的确是大材小用。因此只是在数据的处理上不太妥,其他对数据的处理和数据的可视化做的还是不错的。
这次是有位小伙伴也想做一个疫情的数据采集和可视化系统,想借鉴我之前做的,并且让我指点。那么问题就来了:之前的数据是比较少的,直接从网上提供的免费接口就可以直接获取,而现在疫情已经过去了两年多,如果要整理出历史各省份、 城市每一天的数据,那这个数据就相对庞大,再想找现成的符合功能的接口几乎是没有,因此我做了以下的工作获取数据和处理数据:
1. 数据获取
数据的来源是用了GitHub上这个我收藏了很久的项目:https://lab.isaaclin.cn/nCoV/
数据仓库链接:https://github.com/BlankerL/DXY-COVID-19-Data/releases

这个另外部署了一个数据仓库,每天0点,程序将准时执行,数据会被推送至Release中。
我们就可以从大佬的那个数据仓库直接下载现成爬虫爬取的数据,数据直接下载csv格式的DXYArea.csv就好了,方便用于做处理。
下载后打开,会发现这个92MB的的文件里面有近100W条数据。直接读取的话肯定会有点慢了。
因此这时候我就想到可以尝试使用python的pandas分块读取数据,这个工具对数据处理很方便,对数据的读取也贼快。
2. 使用python读取csv
读取csv选择使用pandas模块,使用原生读取很对很慢
注:py脚本文件和csv文件放在同一目录下
import pandas as pd
import numpy as np
# 读取的文件
filePath = "DXYArea.csv"
# 获取数据
def read_csv_feature(filePath):
# 读取文件
f = open(filePath, encoding='utf-8')
reader = pd.read_csv(f, sep=',', iterator=True)
loop = True
chunkSize = 1000000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
df = pd.concat(chunks, axis=0, ignore_index=True)
f.close()
return df
data = read_csv_feature(filePath)
print('数据读取成功---------------')
csv数据读取成功之后,就全部存在data里面了,而这个data是一个数据集。
可以使用numpy模块工具对数据集进行筛选、导出转换成list,方便对数据进行操作
countryName = np.array(data["countryName"]) countryEnglishName = np.array(data["countryEnglishName"]) provinceName = np.array(data["provinceName"]) province_confirmedCount = np.array(data["province_confirmedCount"]) province_curedCount = np.array(data["province_curedCount"]) province_deadCount = np.array(data["province_deadCount"]) updateTime = np.array(data["updateTime"]) cityName = np.array(data["cityName"]) city_confirmedCount = np.array(data["city_confirmedCount"]) city_curedCount = np.array(data["city_curedCount"]) city_deadCount = np.array(data["city_deadCount"])
这样就把所有需要用到的数据筛选出来了。
3.使用pyhon进行数据清洗
这里的清洗我还是使用了笨方法,很直接暴力的把数据装进对应的list中:
# 全国历史数据
historyed = list()
# 全国最新数据
totaled = list()
# province最新数据
provinceed = list()
# area最新数据
areaed = list()
for i in range(len(data)):
if(countryName[i] == "中国"):
updatetimeList = str(updateTime[i]).split(' ')
updatetime = updatetimeList[0]
# 处理historyed
historyed_temp = list()
if(provinceName[i] == "中国"):
# 处理totaled
if(len(totaled) == 0):
totaled.append(str(updateTime[i]))
totaled.append(int(province_confirmedCount[i]))
totaled.append(int(province_curedCount[i]))
totaled.append(int(province_deadCount[i]))
if((len(historyed) > 0) and (str(updatetime) != historyed[len(historyed) - 1][0])):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed) == 0):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed_temp) > 0):
historyed.append(historyed_temp)
# 处理areaed
areaed_temp = list()
if(provinceName[i] != "中国"):
if(provinceName[i] != "内蒙古自治区" and provinceName[i] != "黑龙江省"):
provinceName[i] = provinceName[i][0:2]
else:
provinceName[i] = provinceName[i][0:3]
flag = 1
for item in areaed:
if(item[1] == str(cityName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed.append(areaed_temp)
flag = 1
for item in areaed_tmp:
if(item[0] == str(provinceName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed_tmp.append(areaed_temp)
# 处理provinceed(需要根据areaed获取)
province_temp = list()
for temp in areaed_tmp:
if(len(provinceed) == 0 and len(province_temp) == 0):
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
else:
if(temp[0] == province_temp[0]):
province_temp[1] = province_temp[1] + temp[2]
province_temp[1] = province_temp[2] + temp[3]
province_temp[1] = province_temp[3] + temp[4]
else:
provinceed.append(province_temp)
province_temp = list()
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
provinceed.append(province_temp)
print('数据清洗成功---------------')
这里没有什么说的,完全是体力活,将上面筛选出来的数据进行清洗,需要注意的是要仔细的观察读取出来的数据的数据格式,有些数据格式不是很标准,需要手动处理。
4. 将清洗的数据自动导入MySql
将数据导入Mysql这里还是使用python,使用了python的pymysql模块
import pymysql
"""
将数据导入数据库
"""
# 打开数据库连接
db=pymysql.connect(host="localhost",user="root",password="123456",database="yq")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
#创建yq数据库
cursor.execute('CREATE DATABASE IF NOT EXISTS yq DEFAULT CHARSET utf8 COLLATE utf8_general_ci;')
print('创建yq数据库成功')
#创建相关表表
cursor.execute('drop table if exists areaed')
sql="""
CREATE TABLE IF NOT EXISTS `areaed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`cityName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedCount` int(11) NULL DEFAULT NULL,
`deadCount` int(11) NULL DEFAULT NULL,
`curedCount` int(11) NULL DEFAULT NULL,
`currentCount` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists provinceed')
sql="""
CREATE TABLE `provinceed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`confirmedNum` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists totaled')
sql="""
CREATE TABLE `totaled` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`diagnosed` int(11) NULL DEFAULT NULL,
`death` int(11) NULL DEFAULT NULL,
`cured` int(11) NULL DEFAULT NULL,
`current` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
cursor.execute('drop table if exists historyed')
sql="""
CREATE TABLE `historyed` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedNum` int(11) NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
print('创建相关表成功')
# 导入historyed
for item in historyed:
sql='INSERT INTO historyed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入historyed成功-------------")
# 导入areaed
for item in areaed:
sql='INSERT INTO areaed VALUES(%s,"%s","%s","%s","%s","%s")'
try:
cursor.execute(sql,(item[0],item[1],item[2],item[4],item[3],item[2]-item[3]-item[4]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入areaed成功-------------")
# 导入provinceed
for item in provinceed:
sql='INSERT INTO provinceed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入provinceed成功-------------")
# 导入totaled
sql='INSERT INTO totaled VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(totaled[0]),totaled[1],totaled[3],totaled[2],totaled[1]-totaled[2]-totaled[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
print("导入totaled成功-------------")
cursor.close()#先关闭游标
db.close()#再关闭数据库连接
这里为了脚本的使用方便,首先进行了建库、然后建表、最后将清洗的数据导入MySql
完整代码
import pandas as pd
import numpy as np
import pymysql
"""
@ProjectName: cleanData
@FileName: cleanData.py
@Author: tao
@Date: 2022/05/03
"""
# 读取的文件
filePath = "DXYArea.csv"
# 全国历史数据
historyed = list()
# 全国最新数据
totaled = list()
# province最新数据
provinceed = list()
# area最新数据
areaed = list()
# 获取数据
def read_csv_feature(filePath):
# 读取文件
f = open(filePath, encoding='utf-8')
reader = pd.read_csv(f, sep=',', iterator=True)
loop = True
chunkSize = 1000000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
df = pd.concat(chunks, axis=0, ignore_index=True)
f.close()
return df
data = read_csv_feature(filePath)
print('数据读取成功---------------')
areaed_tmp = list()
countryName = np.array(data["countryName"])
countryEnglishName = np.array(data["countryEnglishName"])
provinceName = np.array(data["provinceName"])
province_confirmedCount = np.array(data["province_confirmedCount"])
province_curedCount = np.array(data["province_curedCount"])
province_deadCount = np.array(data["province_deadCount"])
updateTime = np.array(data["updateTime"])
cityName = np.array(data["cityName"])
city_confirmedCount = np.array(data["city_confirmedCount"])
city_curedCount = np.array(data["city_curedCount"])
city_deadCount = np.array(data["city_deadCount"])
for i in range(len(data)):
if(countryName[i] == "中国"):
updatetimeList = str(updateTime[i]).split(' ')
updatetime = updatetimeList[0]
# 处理historyed
historyed_temp = list()
if(provinceName[i] == "中国"):
# 处理totaled
if(len(totaled) == 0):
totaled.append(str(updateTime[i]))
totaled.append(int(province_confirmedCount[i]))
totaled.append(int(province_curedCount[i]))
totaled.append(int(province_deadCount[i]))
if((len(historyed) > 0) and (str(updatetime) != historyed[len(historyed) - 1][0])):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed) == 0):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed_temp) > 0):
historyed.append(historyed_temp)
# 处理areaed
areaed_temp = list()
if(provinceName[i] != "中国"):
if(provinceName[i] != "内蒙古自治区" and provinceName[i] != "黑龙江省"):
provinceName[i] = provinceName[i][0:2]
else:
provinceName[i] = provinceName[i][0:3]
flag = 1
for item in areaed:
if(item[1] == str(cityName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed.append(areaed_temp)
flag = 1
for item in areaed_tmp:
if(item[0] == str(provinceName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed_tmp.append(areaed_temp)
# 处理provinceed(需要根据areaed获取)
province_temp = list()
for temp in areaed_tmp:
if(len(provinceed) == 0 and len(province_temp) == 0):
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
else:
if(temp[0] == province_temp[0]):
province_temp[1] = province_temp[1] + temp[2]
province_temp[1] = province_temp[2] + temp[3]
province_temp[1] = province_temp[3] + temp[4]
else:
provinceed.append(province_temp)
province_temp = list()
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
provinceed.append(province_temp)
print('数据清洗成功---------------')
# print(historyed)
# print(areaed)
print(totaled)
# print(provinceed)
"""
print(len(provinceed))
for item in provinceed:
print(item[1]-item[2]-item[3])
"""
"""
将数据导入数据库
"""
# 打开数据库连接
db=pymysql.connect(host="localhost",user="root",password="123456",database="yq")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
#创建yq数据库
cursor.execute('CREATE DATABASE IF NOT EXISTS yq DEFAULT CHARSET utf8 COLLATE utf8_general_ci;')
print('创建yq数据库成功')
#创建相关表表
cursor.execute('drop table if exists areaed')
sql="""
CREATE TABLE IF NOT EXISTS `areaed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`cityName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedCount` int(11) NULL DEFAULT NULL,
`deadCount` int(11) NULL DEFAULT NULL,
`curedCount` int(11) NULL DEFAULT NULL,
`currentCount` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists provinceed')
sql="""
CREATE TABLE `provinceed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`confirmedNum` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists totaled')
sql="""
CREATE TABLE `totaled` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`diagnosed` int(11) NULL DEFAULT NULL,
`death` int(11) NULL DEFAULT NULL,
`cured` int(11) NULL DEFAULT NULL,
`current` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
cursor.execute('drop table if exists historyed')
sql="""
CREATE TABLE `historyed` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedNum` int(11) NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
print('创建相关表成功')
# 导入historyed
for item in historyed:
sql='INSERT INTO historyed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入historyed成功-------------")
# 导入areaed
for item in areaed:
sql='INSERT INTO areaed VALUES(%s,"%s","%s","%s","%s","%s")'
try:
cursor.execute(sql,(item[0],item[1],item[2],item[4],item[3],item[2]-item[3]-item[4]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入areaed成功-------------")
# 导入provinceed
for item in provinceed:
sql='INSERT INTO provinceed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入provinceed成功-------------")
# 导入totaled
sql='INSERT INTO totaled VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(totaled[0]),totaled[1],totaled[3],totaled[2],totaled[1]-totaled[2]-totaled[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
print("导入totaled成功-------------")
cursor.close()#先关闭游标
db.close()#再关闭数据库连接
脚本运行效果

数据库可以看到以下表和数据

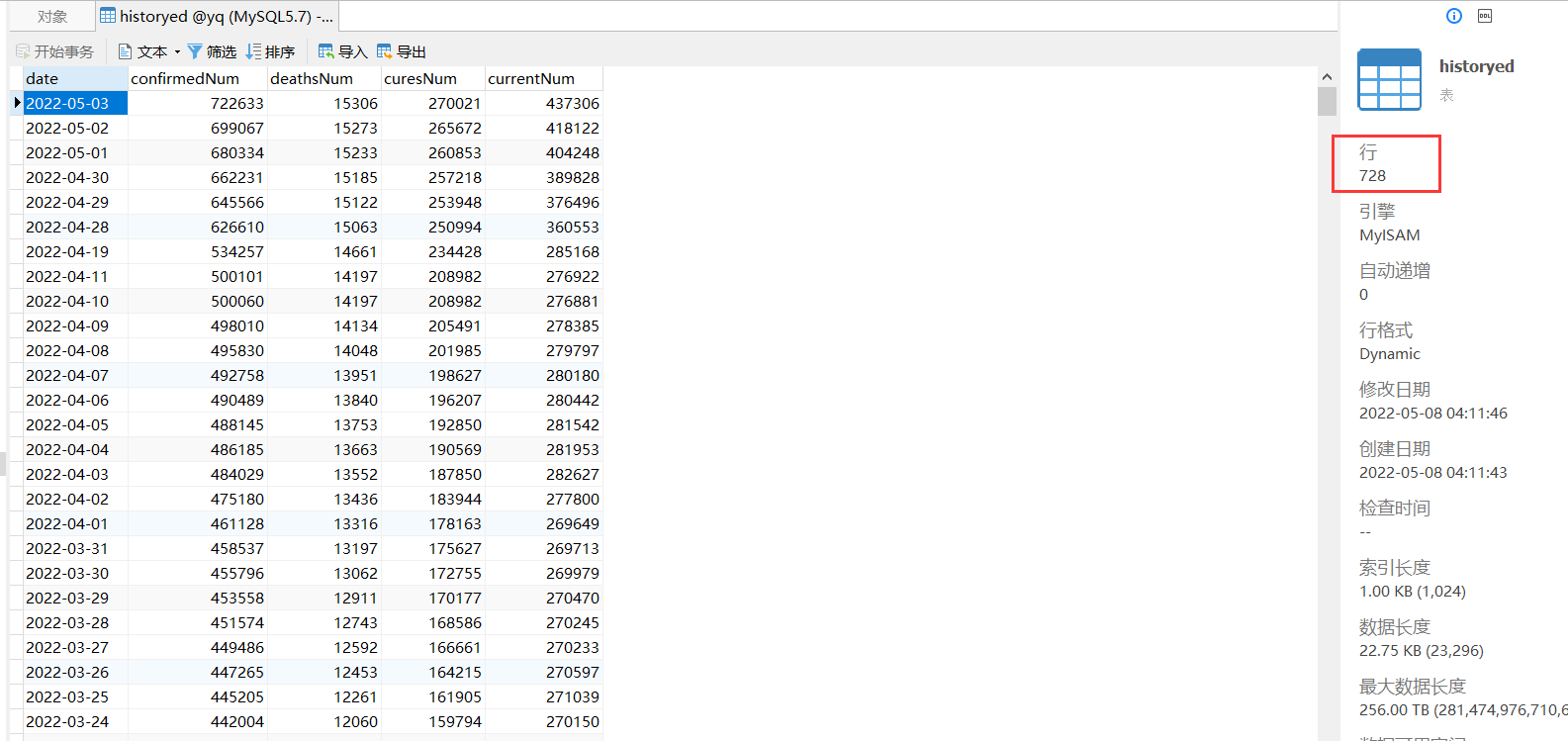
最后我们的数据就已经有了,此时的数据处理的格式还是参照我之前整的新冠肺炎疫情的数据采集和可视化分析系统对接的,集体后台和可视化的实现可以参考:https://qkongtao.cn/?p=514
到此这篇关于python清洗疫情历史数据的文章就介绍到这了,更多相关python疫情历史数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫爬取疫情数据并可视化展示
目录 知识点 开发环境 爬虫完整代码 导入模块 分析网站 发送请求 获取数据 解析数据 保存数据 数据可视化 导入模块 读取数据 死亡率与治愈率 各地区确诊人数与死亡人数情况 知识点 爬虫基本流程 json requests 爬虫当中 发送网络请求 pandas 表格处理 / 保存数据 pyecharts 可视化 开发环境 python 3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写数据分析代码 专业性 pycharm 专业代码编辑器 按照年份与月
-
Python实现Excel文件的合并(以新冠疫情数据为例)
目录 一.单目录下面的数据合并 二.使用函数进行数据合并 三.处理港澳台数据 注:本篇文章以新冠疫情数据文件的合并为例. 需要相关数据的请移步:>2020-2022年新冠疫情数据 一.单目录下面的数据合并 将2020下的所有文件进行合并,成一个文件: import requests import json import openpyxl import datetime import datetime as dt import time import pandas as pd import csv
-
Python获取江苏疫情实时数据及爬虫分析
目录 1.引言 2.获取目标网站 3.爬取目标网站 4.解析爬取内容 4.1. 解析全国今日总况 4.2. 解析全国各省份疫情情况 4.3. 解析江苏各地级市疫情情况 5.结果可视化 6. 代码 7. 参考 1.引言 最近江苏南京.湖南张家界陆续爆发疫情,目前已波及8省22市,全国共有2个高风险地区,52个中风险地区.身在南京,作为兢兢业业的打工人,默默地成为了"苏打绿".为了关注疫情状况,今天我们用python来爬一爬疫情的实时数据. 2.获取目标网站 为了使用python来获取疫情
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
用Python可视化新冠疫情数据
目录 前言 数据获取 数据可视化 python的特色 总结 前言 不知道大伙有没有看到过这一句话:“中国(疫苗研发)非常困难,因为在中国我们没有办法做第三期临床试验,因为没有病人了.”这句话是中国工程院院士钟南山在上海科技大学2021届毕业典礼上提出的.这句话在全网流传,被广大网友称之为“凡尔赛”发言. 今天让我们用数据来看看这句话是不是“凡尔赛”本赛.在开始之前我们先来说说今天要用到的python库吧! 1.数据获取部分 requests lxml json openpyxl 2.数据可视化部
-
python清洗疫情历史数据的过程详解
目录 1. 数据获取 2. 使用python读取csv 3.使用pyhon进行数据清洗 4. 将清洗的数据自动导入MySql 在我2020年大三的一个实训的大作业中,我整了一个新冠肺炎疫情的数据采集和可视化分析系统,大致就是先找数据,然后将数据导入hive中,然后使用hive对数据进行清洗,然后将清洗后的数据使用hql导入MySql,之后就是用ssm开发后台数据接口,然后前端使用echarts和表格对数据进行可视化.具体可以查看:https://qkongtao.cn/?p=514.由于那时候主
-
python DataFrame转dict字典过程详解
这篇文章主要介绍了python DataFrame转dict字典过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景:将商品id以及商品类别作为字典的键值映射,生成字典,原为DataFrame # 创建一个DataFrame # 列值类型均为int型 import pandas as pd item = pd.DataFrame({'item_id': [100120, 10024504, 1055460], 'item_categor
-
python函数定义和调用过程详解
这篇文章主要介绍了python函数定义和调用过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 我们可以创建一个函数来列出费氏数列 >>> def fib(n): # write Fibonacci series up to n ... """Print a Fibonacci series up to n.""" ... a, b = 0, 1 ... while a &
-
Python对象的属性访问过程详解
只想回答一个问题: 当编译器要读取obj.field时, 发生了什么? 看似简单的属性访问, 其过程还蛮曲折的. 总共有以下几个step: 1. 如果obj 本身(一个instance )有这个属性, 返回. 如果没有, 执行 step 2 2. 如果obj 的class 有这个属性, 返回. 如果没有, 执行step 3. 3. 如果在obj class 的父类有这个属性, 返回. 如果没有, 继续执行3, 直到访问完所有的父类. 如果还是没有, 执行step 4. 4. 执行obj.__ge
-
python元组打包和解包过程详解
1.在将多个以逗号分隔的值赋给一个变量时,多个值被打包成一个元组类型.当我们将一个元组赋给多个变量时,它将解包成多个值,然后分别将其赋给相应的变量. # 打包 a = 1, 10, 100 print(type(a), a) # <class 'tuple'> (1, 10, 100) # 解包 i, j, k = a print(i, j, k) # 1 10 100 2.解包时,如果解包出来的元素数目与变量数目不匹配,就会引发ValueError异常.错误信息为:too many valu
-
Python实现自动化邮件发送过程详解
使用Python实现自动化邮件发送,可以让你摆脱繁琐的重复性业务,可以节省非常多的时间. 操作前配置(以较为复杂的QQ邮箱举例,其他邮箱操作类似) 单击设置-账号,滑倒下方协议处,开启IMAP/SMTP协议(IMAP,即Internet Message Access Protocol(互联网邮件访问协议),可以通过这种协议从邮件服务器上获取邮件的信息.下载邮件等.IMAP与POP类似,都是一种邮件获取协议.) (ps.开启需要验证) 记住端口号,后续写代码发送邮件时候需要 生成授权码,前期配置完
-
python调用动态链接库的基本过程详解
动态链接库在Windows中为.dll文件,在linux中为.so文件.以linux平台为例说明python调用.so文件的使用方法. 本例中默认读者已经掌握动态链接库的生成方法,如果不太清楚的可以参考动态链接库的使用 调用上例动态链接库的使用中的sum.so import ctypes so = ctypes.CDLL('./sum.so') print "so.sum(50) = %d" % so.sum(50) so.display("hello world!"
-
Python Django Vue 项目创建过程详解
1.创建项目 打开pycharm 终端,输入如下,创建项目 # 进入pycharm 项目目录下 cd pyWeb django-admin startproject pyweb_dome # pyweb_dome 是django项目名称 2.创建应用 # 进入项目根目录 pyweb_dome 下 cd pyweb_dome python manage.py startapp webserver # webserver 为应用名 3.创建前端项目 使用vue-cli在根目录创建一个名称叫[fron
-
python连接PostgreSQL数据库的过程详解
1. 常用模块 # 连接数据库 connect()函数创建一个新的数据库连接对话并返回一个新的连接实例对象 PG_CONF_123 = { 'user':'emma', 'port':123, 'host':'192.168.1.123', 'password':'emma', 'database':'dbname'} conn = psycopg2.connect(**PG_CONF_123) # 打开一个操作整个数据库的光标 连接对象可以创建光标用来执行SQL语句 cur = conn.cu
-
手机使用python操作图片文件(pydroid3)过程详解
起因 前几天去国图拍了一本书,一本心理学方面的书,也许你问我为什么不去买一本,或者去网上找pdf. 其实吧,关于心理学方面的书可以说在市面上一抓就是一堆,至于拍这本书两个原因,一个是没有什么收藏价值不值得我去买,只适合应急用,然后就是这本书的作者写作特点和其他大众的不太一样,可以说是有特点或者偏门,于是我就在手机上拍了一堆的图片,后来整理成了pdf,但是昨天我看的时候原图片文件还在快上千了吧,一个一个选择删除真是删烦了,也许你会说为什么不导入到电脑上进行删除,没办法我就是想整点不一样的,学了py