Python连接Oracle之环境配置、实例代码及报错解决方法详解
Oracle Client 安装
1、环境
日期:2019年8月1日
公司已经安装好Oracle服务端
Windows版本:Windows10专业版
系统类型:64位操作系统,基于x64的处理器
Python版本:Python 3.6.4 :: Anaconda, Inc.

2、下载网址
https://www.oracle.com/database/technologies/instant-client/downloads.html
3、解压至目录

解压后(这里放D盘)

4、配置环境变量
控制面板\系统和安全\系统 -> 高级系统设置 -> 环境变量
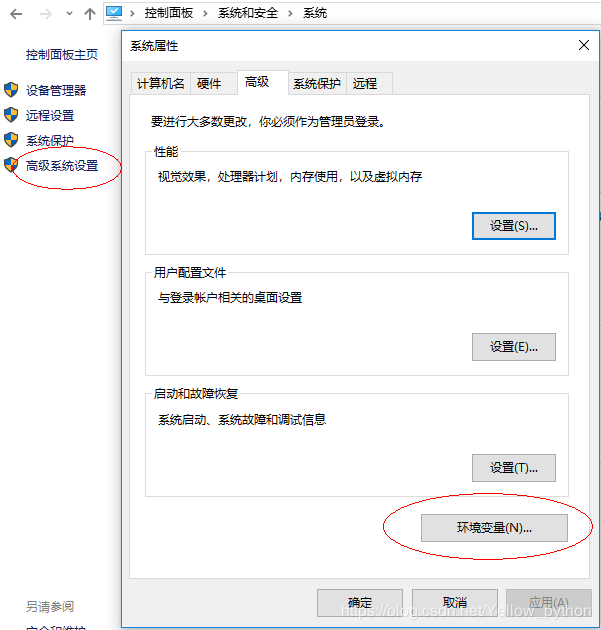
新建ORACLE_HOME,值为包解压的路径
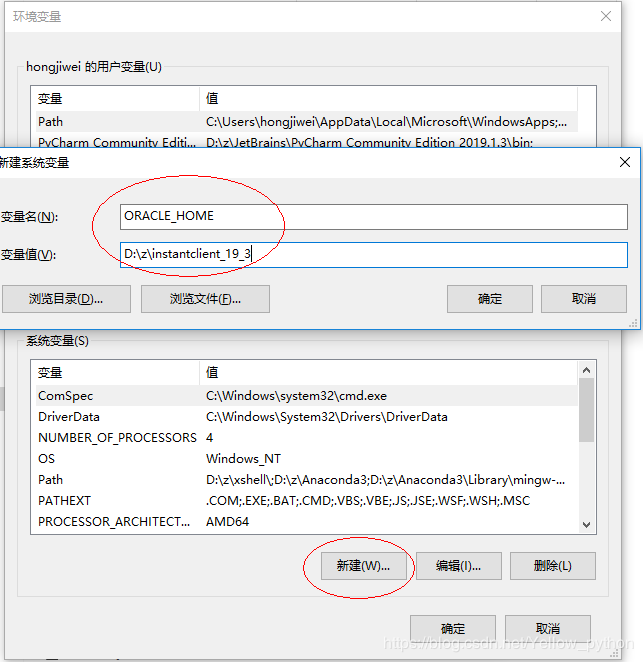
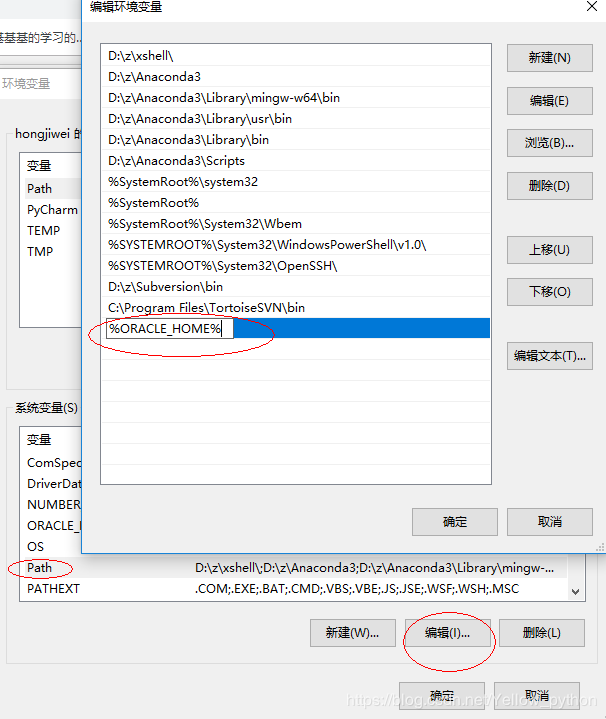
编辑PATH,添加%ORACLE_HOME%
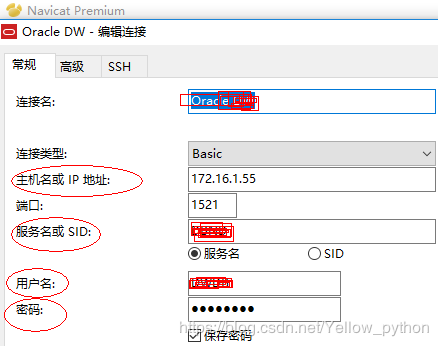
Navicat连接测试
cx_Oracle
安装命令
conda install cx_Oracle
基础代码
import cx_Oracle
def execute(query):
db = cx_Oracle.connect('用户名/密码@IP/ServiceName')
cursor = db.cursor()
cursor.execute(query)
result = cursor.fetchall()
cursor.close()
db.close()
return result
def commit(sql):
db = cx_Oracle.connect('用户名/密码@IP/ServiceName')
cursor = db.cursor()
cursor.execute(sql)
db.commit()
cursor.close()
db.close()
封装成类
from cx_Oracle import Connection # conda install cx_Oracle
from conf import CONN, Color
class Oracle(Color):
def __init__(self, conn=CONN):
self.db = Connection(*conn, encoding='utf8') # 用户名 密码 IP/ServiceName
self.cursor = self.db.cursor()
def __del__(self):
self.cursor.close()
self.db.close()
def commit(self, sql):
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.red(e)
def fetchall(self, query):
self.cursor.execute(query)
return self.cursor.fetchall()
def fetchone(self, query, n=9999999):
self.cursor.execute(query)
for _ in range(n):
one = self.cursor.fetchone()
if one:
yield one
def fetchone_dt(self, query, n=9999999):
self.cursor.execute(query)
columns = [i[0] for i in self.cursor.description]
length = len(columns)
for _ in range(n):
one = self.cursor.fetchone() # tuple
yield {columns[i]: one[i] for i in range(length)}
def read_clob(self, query):
self.cursor.execute(query)
one = self.cursor.fetchone()
while one:
try:
yield one[0].read()
except Exception as e:
self.red(e)
one = self.cursor.fetchone()
def db2sheet(self, query, prefix):
df = pd.read_sql_query(query, self.db)
if 'url' in df.columns:
df['url'] = "'" + df['url']
df.to_excel(prefix.replace('.xlsx', '')+'.xlsx', index=False)
def db2sheets(self, queries, prefix):
writer = pd.ExcelWriter(prefix.replace('.xlsx', '')+'.xlsx')
for sheet_name, query in queries.items():
df = pd.read_sql_query(query, self.db)
if 'url' in df.columns:
df['url'] = "'" + df['url']
df.to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
def tb2sheet(self, table):
sql = "SELECT * FROM " + table
self.db2sheet(sql, table)
def insert(self, dt, tb):
for k, v in dt.items():
if isinstance(v, str):
dt[k] = v.replace("'", '').strip()
ls = [(k, v) for k, v in dt.items() if v is not None]
sql = 'INSERT INTO %s (' % tb + ','.join(i[0] for i in ls) + \
') VALUES (' + ','.join('%r' % i[1] for i in ls) + ')'
self.commit(sql)
def insert_clob(self, dt, tb, clob):
for k, v in dt.items():
if isinstance(v, str):
dt[k] = v.replace("'", '').strip()
# 把超长文本保存在一个变量中
# declare = "DECLARE variate CLOB := '%s';\n" % dt[clob]
join = lambda x: '||'.join("'%s'" % x[10922*i: 10922*(i+1)] for i in range(len(x)//10922+1)) # 32768//3
declare = "DECLARE variate CLOB := %s;\n" % join(dt[clob])
dt[clob] = 'variate'
ls = [(k, v) for k, v in dt.items() if v is not None]
sql = 'INSERT INTO %s (' % tb + ','.join(i[0] for i in ls) + ') VALUES (' +\
','.join('%r' % i[1] for i in ls) + ');'
sql = declare + 'BEGIN\n%s\nEND;' % sql.replace("'variate'", 'variate')
self.commit(sql)
def update(self, dt_update, dt_condition, table):
sql = 'UPDATE %s SET ' % table + ','.join('%s=%r' % (k, v) for k, v in dt_update.items()) \
+ ' WHERE ' + ' AND '.join('%s=%r' % (k, v) for k, v in dt_condition.items())
self.commit(sql)
def truncate(self, tb):
self.commit('truncate table ' + tb)
db_read = Oracle()
fetchall = db_read.fetchall
fetchone = db_read.fetchone
read_clob = db_read.read_clob
if __name__ == '__main__':
query = '''
'''.strip()
for i in fetchone(query, 99):
print(i)
conf
CONN = ('用户名', '密码', 'IP/ServiceName')
conn = '用户名/密码@IP/ServiceName'
文本字符串查询
class INSTR(Oracle):
"""文本字符串查询"""
def highlight_instr(self, table, field, keyword, clob=True):
sql = "SELECT %s FROM %s WHERE INSTR(%s,'%s')>0" % (field, table, field, keyword)
if clob:
for i in self.read_clob(sql):
self.highlight(i, keyword)
else:
for i, in self.fetchone(sql):
self.highlight(i, keyword)
def regexp_instr(self, table, field, pattern, regexp=True, clob=True):
sql = "SELECT %s FROM %s WHERE INSTR(%s,'%s')>0" % (field, table, field, pattern)
sql = sql.replace('INSTR', 'REGEXP_INSTR') if regexp else sql
if clob:
for i in self.read_clob(sql):
yield i
else:
for i, in self.fetchone(sql):
yield i
一个简单的建表示例
-- 建表
CREATE TABLE table_name
(
serial_number NUMBER(10),
collect_date DATE,
url VARCHAR2(255),
long_text CLOB,
price NUMBER(10)-- 若需要精确到小数点2位,按分存储,/100还原到元
);
-- 给表添加备注
COMMENT ON TABLE table_name IS '中文表名';
-- 给表字段添加备注
COMMENT ON COLUMN table_name.serial_number IS '编号';
COMMENT ON COLUMN table_name.collect_date IS '日期';
COMMENT ON COLUMN table_name.url IS 'URL';
COMMENT ON COLUMN table_name.long_text IS '长文本';
COMMENT ON COLUMN table_name.price IS '价钱';
-- 插入
INSERT INTO table_name(collect_date) VALUES (DATE'2019-08-23');
INSERT INTO table_name(long_text) VALUES ('a');
INSERT INTO table_name(long_text) VALUES ('b');
-- 查询
SELECT * FROM table_name WHERE TO_CHAR(long_text) in ('a','b');
-- 查建表语句(表名大写)
SELECT dbms_metadata.get_ddl('TABLE','TABLE_NAME') FROM dual;
-- 删表
DROP TABLE table_name;
sqlalchemy
import os # 解决【UnicodeEncodeError: 'ascii' codec can't encode character】问题 os.environ['NLS_LANG'] = 'AMERICAN_AMERICA.AL32UTF8' # os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' from cx_Oracle import makedsn from sqlalchemy import create_engine, Column, String, Integer from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # 连接数据库(ORA-12505: TNS:listener does not currently know of SID given in connect descriptor) ip = '' port = '' tnsname = '' # 实例名 uname = '' # 用户名 pwd = '' # 密码 dsnStr = makedsn(ip, port, service_name=tnsname) connect_str = "oracle://%s:%s@%s" % (uname, pwd, dsnStr) # 创建连接引擎,这个engine是lazy模式,直到第一次被使用才真实创建 engine = create_engine(connect_str, encoding='utf-8') # 创建对象的基类 Base = declarative_base() class Student(Base): # 表名 __tablename__ = 'student' # 表字段 sid = Column(String(20), primary_key=True) age = Column(Integer) # 建表(继承Base的所有表) Base.metadata.create_all(bind=engine) # 使用ORM操作数据库 Session = sessionmaker(bind=engine) # 创建ORM基类 session = Session() # 创建ORM对象 tb_obj = Student(sid='a6', age=18) # 创建表对象 session.add(tb_obj) # 添加到ORM对象(插入数据) session.commit() # 提交 session.close() # 关闭ORM对象 # 删表(继承Base的所有表) Base.metadata.drop_all(engine)
报错处理
DPI-1047: 64-bit Oracle Client library cannot be loaded
首先操作系统位数、python位数、cx_Oracle版本要对应上;另外可能缺【Visual C++】
每次装完后,要重启pycharm和python
ORA-12170: TNS:Connect timeout occurred
打开终端ping一下
检查【主机名或IP地址】、【服务名或SID】、【用户名】和【密码】是否填对
中文乱码
encoding=‘utf8'
ORA-00972: identifier is too long
insert语句中出现'之类的字符
解决方法:将可能报错的字符替换掉
ORA-64203: Destination buffer too small to hold CLOB data after character set conversion.
select TO_CHAR(long_text) from table_name,目标缓冲区太小,无法储存CLOB转换字符后的数据
解决方法:不在SQL用TO_CHAR,改在Python中用read(如上代码所示)
ORA-01704: string literal too long
虽然CLOB可以保存长文本,但是SQL语句有长度限制
解决方法:把超长文本保存在一个变量中(如上代码所示)
PLS-00172: string literal too long
字符串长度>32767(215-1)
解决方法:使用'||'来连接字符串(如上代码所示)
ORA-00928: missing SELECT keyword
INSERT操作时,表字段命名与数据库内置名称冲突,如:ID、LEVEL、DATE等
解决方法:建立命名规范
cx_Oracle.DatabaseError: ORA-12505: TNS:listener does not currently know of SID given in connect descriptor
使用sqlalchemy时的报错
原因可能是目标数据库是集群部署的,可以咨询一下DBA,或见上面代码from cx_Oracle import makedsn
UnicodeEncodeError: 'ascii' codec can't encode character
使用sqlalchemy时的报错,插入中文字符引起
解决方法是设置os.environ['NLS_LANG']
更多关于Python连接Oracle之环境配置、实例代码及报错解决方法请查看下面的相关链接
相关推荐
-
python操作oracle的完整教程分享
1. 连接对象 操作数据库之前,首先要建立数据库连接. 有下面几个方法进行连接. >>>import cx_Oracle >>>db = cx_Oracle.connect('hr', 'hrpwd', 'localhost:1521/XE') >>>db1 = cx_Oracle.connect('hr/hrpwd@localhost:1521/XE') >>>dsn_tns = cx_Oracle.makedsn('localho
-
解决python3捕获cx_oracle抛出的异常错误问题
最近一直在用python写点监控oracle的程序,一直没有用到异常处理这一块,然后日常监控中一些错误笼统的抛出数据库连接异常,导致后续处理的时候无法及时定位问题. 于是早上抽点时间看了下python3关于cx_oracle的异常处理形式. 其实,我只是想在python抛出oracle错误的时候,捕获到具体ora-信息. 写法很简单,这里记录下,以备后用. try: oracle_check(dbname) except cx_Oracle.DatabaseError as msg: print
-
python cx_Oracle的基础使用方法(连接和增删改查)
问题 使用python操作oracle数据库,获取表的某几个字段作为变量值使用. 使用Popen+sqlplus的方法需要对格式进行控制,通过流获取这几个字段值不简洁(个人观点--).(优点是能够使用sqlplus的方法直接访问sql文件,不需要考虑打开/关闭连接,并且通过流向文件中写入还挺好用的.不过优点不是这次所关注的) 使用cx-Oracle将查询结果返回为tuple格式,对返回结果的操作简洁,满足需求.(要注意数据库连接创建与关闭.sql的编写.预处理与提交等等,看起来也不简洁(同样个人
-
python安装oracle扩展及数据库连接方法
本文实例讲述了python安装oracle扩展及数据库连接方法.分享给大家供大家参考,具体如下: 下载: cx_Oracle下载地址:http://cx-oracle.sourceforge.net/ instantclient-basic下载地址:http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html window环境: python27 oracle10 需要软件: cx_Ora
-
Python3.6连接Oracle数据库的方法详解
本文实例讲述了Python3.6连接Oracle数据库的方法.分享给大家供大家参考,具体如下: 下载cx_Oracle模块模块: https://pypi.python.org/pypi/cx_Oracle/5.2.1#downloads 这里下载的是源码进行安装 [root@oracle oracle]# tar xf cx_Oracle-5.2.1.tar.gz [root@oracle oracle]# cd cx_Oracle-5.2.1 [root@oracle cx_Oracle-5
-
python链接oracle数据库以及数据库的增删改查实例
初次使用python链接oracle,所以想记录下我遇到的问题,便于向我这样初次尝试的朋友能够快速的配置好环境进入开发环节. 1.首先,python链接oracle数据库需要配置好环境. 我的相关环境如下: 1)python:Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 17:26:49) [MSC v.1900 32 bit (Intel)] on win32 2)oracle:11.2.0.1.0 64bit.这个是server版本号,在链接oracle
-
解决python通过cx_Oracle模块连接Oracle乱码的问题
用python连接Oracle是总是乱码,最有可能的是oracle客户端的字符编码设置不对. 本人是在进行数据插入的时候总是报关键字"From"不存在,打印插入的Sql在pl/sql中进行插入,没有问题.所以,后来从字符集编码上去考虑和解决问题. 编写的python脚本中需要加入: import os os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' 这样可以保证select出来的中文显示没有问题. 要能够正常的inser
-
windows下python连接oracle数据库
python连接oracle数据库的方法,具体如下 1.首先安装cx_Oracle包 2.解压instantclient-basic-windows.x64-11.2.0.4.0.zip到c:\oracle 3.拷贝instantclient_11_2下所有.dll文件到c:\python34\Lib\site-packages\下(根据自己的python版本拷贝到相应的site-packages文件夹下) python连接示例代码: # -*- coding: utf-8 -*- import
-
使用Python脚本zabbix自定义key监控oracle连接状态
目的:此次实验目的是为了zabbix服务端能够实时监控某服务器上oracle实例能否正常连接 环境:1.zabbix_server 2.zabbix_agent(含有oracle) 主要知识点: 1.zabbix_get用法 2.python中cx_Oracle模块使用 ------------------------------------------------------------------------------ 1.zabbix_get用法 常用用法 zabbix_get -s h
-
python实现自动化报表功能(Oracle/plsql/Excel/多线程)
日常会有很多固定报表需要手动更新,本文将利用python实现多线程运行oracle代码,并利用xlwings包和numpy包将结果写入到指定excel模版(不改变模版内容),并自动生成带日期命名的新excel.此外还添加了logging模块记录运行日志,以及利用try-except实现遇到错误自动重新运行.下面将介绍整个自动化的实现过程. # -*- coding: utf-8 -*- # Create time: 2019-10-16 # Update time: 2019-11-28 # V
-
Python编程实战之Oracle数据库操作示例
本文实例讲述了Python编程实战之Oracle数据库操作.分享给大家供大家参考,具体如下: 1. 要想使Python可以操作Oracle数据库,首先需要安装cx_Oracle包,可以通过下面的地址来获取安装包 http://cx-oracle.sourceforge.net/ 2. 另外还需要oracle的一些类库,此时需要在运行python的机器上安装Oracle Instant Client软件包,可以通过下面地址获得 http://www.oracle.com/technetwork/d
-
Python使用cx_Oracle调用Oracle存储过程的方法示例
本文实例讲述了Python使用cx_Oracle调用Oracle存储过程的方法.分享给大家供大家参考,具体如下: 这里主要测试在Python中通过cx_Oracle调用PL/SQL. 首先,在数据库端创建简单的存储过程. create or replace procedure test_msg(i_user in varchar2, o_msg out varchar2) is begin o_msg := i_user ||', Good Morning!'; end; 然后,开始在Pytho
-
Python3连接SQLServer、Oracle、MySql的方法
环境: python3.4 64bit pycharm2018社区版 64bit Oracle 11 64bit SQLServer· Mysql 其中三种不同的数据库安装在不同的服务器上,通过局域网相连 步骤1:在pycharm上安装相应的包,可通过pip或者其他方式 步骤2:import这些包 import pymysql,pymssql,cx_Oracle #导入数据库相关包 步骤3: db_sqls = pymssql.connect(host='192.168.10.172',port
-
Python操作Oracle数据库的简单方法和封装类实例
本文实例讲述了Python操作Oracle数据库的简单方法和封装类.分享给大家供大家参考,具体如下: 最近工作有接触到Oracle,发现很多地方用Python脚本去做的话,应该会方便很多,所以就想先学习下Python操作Oracle的基本方法. 考虑到Oracle的使用还有一个OracleClient的NetConfig的存在,我觉得连接起来就应该不是个简单的事情. 果然,网上找了几个连接方法,然后依葫芦却画了半天,却也不得一个瓢. 方法1:用户名,密码和监听分别作为参数 conn=cx_Ora
-
Python如何应用cx_Oracle获取oracle中的clob字段问题
最近在用Python编写连接数据库获取记录的脚本,其中用到了cx_Oracle模块.它的语法主要如下: cx_Oracle.connect('username','pwd','IP/HOSTNAME:PORT/TNSNAME') import cx_Oracle db1=cx_Oracle.connect('yang','yang','127.0.0.1:1523/yangdb') db2=cx_Oracle.connect('yang/yang@127.0.0.1:1523/yangdb')
-

Python读写及备份oracle数据库操作示例
本文实例讲述了Python读写及备份oracle数据库操作.分享给大家供大家参考,具体如下: 最近项目中需要用到Python调用oracle实现读写操作,踩过很多坑,历尽艰辛终于实现了.性能怎样先不说,有方法后面再调优嘛.现在把代码和注意点记录一下. 1. 所需Python工具库 cx_Oracle,pandas,可以使用通过控制台使用pip进行安装(电脑中已经安装) 2. 实现查询操作 #工具库导入 import pandas as pd import cx_Oracle # 注:设置环境编码
-
Python使用cx_Oracle模块操作Oracle数据库详解
本文实例讲述了Python使用cx_Oracle模块操作Oracle数据库.分享给大家供大家参考,具体如下: ORACLE_SID参数,这个参数是操作系统中用到的,它是描述我们要默认连接的数据库实例,对于一个机器上有多个实例的情况下,要修改后才能通过 conn / as sysdba连接,因为这里用到了默认的实例名. 简而言之,打个比方,你的名字叫小明,但是你有很多外号.你父母叫你小明,但是朋友都叫你的外号. 这里你的父母就是oracle实例,小明就是sid,service name就是你的外号
-
python使用 cx_Oracle 模块进行查询操作示例
本文实例讲述了python使用 cx_Oracle 模块进行查询操作.分享给大家供大家参考,具体如下: # !/usr/bin/env python # -*- coding: utf-8 -*- import cx_Oracle from pprint import pprint import csv import time import re import binascii print time.ctime() try: conn = cx_Oracle.connect('tlcbuser/