C#构建树形结构数据(全部构建,查找构建)
摘要:
最近在做任务管理,任务可以无限派生子任务且没有数量限制,前端采用Easyui的Treegrid树形展示控件。
一、遇到的问题
获取全部任务拼接树形速度过慢(数据量大约在900条左右)且查询速度也并不快;
二、解决方法
1、Tree转化的JSON数据格式
a.JSON数据格式:
[
{
"children":[
{
"children":[
],
"username":"username2",
"password":"password2",
"id":"2",
"pId":"1",
"name":"节点2"
},
{
"children":[
],
"username":"username2",
"password":"password2",
"id":"A2",
"pId":"1",
"name":"节点2"
}
],
"username":"username1",
"password":"password1",
"id":"1",
"pId":"0",
"name":"节点1"
},
{
"children":[
],
"username":"username1",
"password":"password1",
"id":"A1",
"pId":"0",
"name":"节点1"
}
]
b.定义实体必要字段
为了Tree结构的通用性,我们可以定义一个抽象的公用实体TreeObject以保证后续涉及到的List<T>转化树形JSON
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace MyTree.Abs
{
public abstract class TreeObejct
{
public string id { set; get; }
public string pId { set; get; }
public string name { set; get; }
public IList<TreeObejct> children = new List<TreeObejct>();
public virtual void Addchildren(TreeObejct node)
{
this.children.Add(node);
}
}
}
c.实际所需实体TreeModel让它继承TreeObject,这样对于id,pId,name,children我们就可以适用于其它实体了,这也相当于我们代码的特殊约定:
using MyTree.Abs;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace MyTree.Models
{
public class TreeModel : TreeObejct
{
public string username { set; get; }
public string password { set; get; }
}
}
2、递归遍历
获取全部任务并转化为树形
获取全部任务转化为树形是比较简单的,我们首先获取到pId=0的顶级数据(即不存在父级的任务),我们通过顶级任务依次递归遍历它们的子节点。
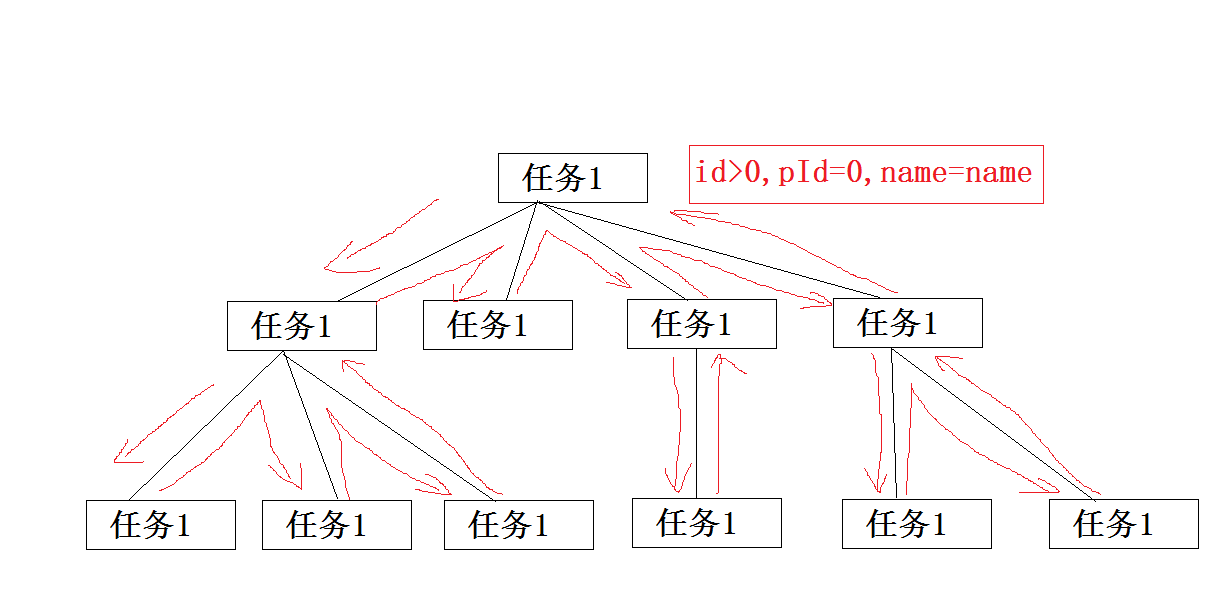
b.我们暂时id以1开始则pId=0的都为顶级任务
我们首先写一段生成数据的方法:
public static IList<TreeObejct> GetData(int number = 11)
{
IList<TreeObejct> datas = new List<TreeObejct>();
for (int i = 1; i < number; i++)
{
datas.Add(new TreeModel
{
id = i.ToString(),
pId = (i - 1).ToString(),
name = "节点" + i,
username = "username" + i,
password = "password" + i
});
datas.Add(new TreeModel
{
id = "A" + i.ToString(),
pId = (i - 1).ToString(),
name = "节点" + i,
username = "username" + i,
password = "password" + i
});
}
return datas;
}
其次我们定义一些变量:
private static IList<TreeObejct> models;
private static IList<TreeObejct> models2;
private static Thread t1;
private static Thread t2;
static void Main(string[] args)
{
int count = 21;
Console.WriteLine("生成任务数:"+count+"个");
Console.Read();
}
我们再写一个递归获取子节点的递归方法:
public static IList<TreeObejct> GetChildrens(TreeObejct node)
{
IList<TreeObejct> childrens = models.Where(c => c.pId == node.id.ToString()).ToList();
foreach (var item in childrens)
{
item.children = GetChildrens(item);
}
return childrens;
}
编写调用递归方法Recursion:
public static void Recursion()
{
#region 递归遍历
System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch();
sw.Start();
var mds_0 = models.Where(c => c.pId == "0");//获取顶级任务
foreach (var item in mds_0)
{
item.children = GetChildrens(item);
}
sw.Stop();
Console.WriteLine("----------递归遍历用时:" + sw.ElapsedMilliseconds + "----------线程名称:"+t1.Name+",线程ID:"+t1.ManagedThreadId);
#endregion
}
编写main函数启动测试:
private static IList<TreeObejct> models;
private static IList<TreeObejct> models2;
private static Thread t1;
private static Thread t2;
static void Main(string[] args)
{
int count = 1001;
Console.WriteLine("生成任务数:"+count+"个");
models = GetData(count);
t1 = new Thread(Recursion);
t1.Name = "递归遍历";
t1.Start();
Console.Read();
}
输出结果:

递归遍历至此结束。
3、非递归遍历
非递归遍历在操作中不需要递归方法的参与即可实现Tree的拼接
对于以上的代码,我们不需要修改,只需要定义一个非递归遍历方法NotRecursion:
public static void NotRecursion()
{
#region 非递归遍历
System.Diagnostics.Stopwatch sw2 = new System.Diagnostics.Stopwatch();
sw2.Start();
Dictionary<string, TreeObejct> dtoMap = new Dictionary<string, TreeObejct>();
foreach (var item in models)
{
dtoMap.Add(item.id, item);
}
IList<TreeObejct> result = new List<TreeObejct>();
foreach (var item in dtoMap.Values)
{
if (item.pId == "0")
{
result.Add(item);
}
else
{
if (dtoMap.ContainsKey(item.pId))
{
dtoMap[item.pId].AddChilrden(item);
}
}
}
sw2.Stop();
Console.WriteLine("----------非递归遍历用时:" + sw2.ElapsedMilliseconds + "----------线程名称:" + t2.Name + ",线程ID:" + t2.ManagedThreadId);
#endregion
}
编写main函数:
private static IList<TreeObejct> models;
private static IList<TreeObejct> models2;
private static Thread t1;
private static Thread t2;
static void Main(string[] args)
{
int count = 6;
Console.WriteLine("生成任务数:"+count+"个");
models = GetData(count);
models2 = GetData(count);
t1 = new Thread(Recursion);
t2 = new Thread(NotRecursion);
t1.Name = "递归遍历";
t2.Name = "非递归遍历";
t1.Start();
t2.Start();
Console.Read();
}
启动查看执行结果:

发现一个问题,递归3s,非递归0s,随后我又进行了更多的测试:
执行时间测试
| 任务个数 | 递归(ms) | 非递归(ms) |
| 6 | 3 | 0 |
| 6 | 1 | 0 |
| 6 | 1 | 0 |
| 101 | 1 | 0 |
| 101 | 4 | 0 |
| 101 | 5 | 0 |
| 1001 | 196 | 5 |
| 1001 | 413 | 1 |
| 1001 | 233 | 7 |
| 5001 | 4667 | 5 |
| 5001 | 4645 | 28 |
| 5001 | 5055 | 7 |
| 10001 | StackOverflowException | 66 |
| 10001 | StackOverflowException | 81 |
| 10001 | StackOverflowException | 69 |
| 50001 | - | 46 |
| 50001 | - | 47 |
| 50001 | - | 42 |
| 100001 | - | 160 |
| 100001 | - | 133 |
| 100001 | - | 129 |
StackOverflowException:因包含的嵌套方法调用过多而导致执行堆栈溢出时引发的异常。 此类不能被继承。
StackOverflowException 执行堆栈溢出发生错误时引发,通常发生非常深度或无限递归。
-:没有等到结果。
当然这个测试并不专业,但是也展示出了它的效率的确满足了当前的需求。
4、查找构建树形结果
原理同上述非递归相同,不同之处是我们通过查找的数据去构建树形
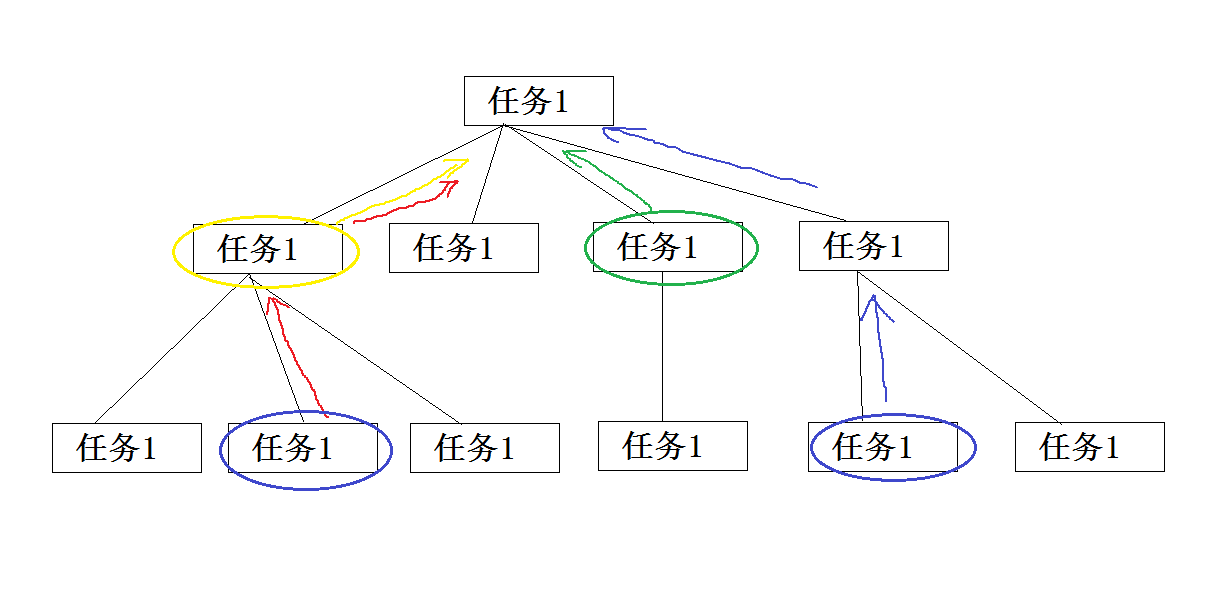
我们通过查找获取到圈中的任务,再通过当前节点获取到父级节点,因为当时没考虑到任务层级的关系,因此为添加层级编号,为此可能会有重复的存在,因此我们使用HashSet<T>来剔除我们的重复数据,最终获取到有用数据再通过非递归遍历方法,我们便可以再次构建出树形(tree),来转化为JSON数据。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

C#数据结构之单链表(LinkList)实例详解
本文实例讲述了C#数据结构之单链表(LinkList)实现方法.分享给大家供大家参考,具体如下: 这里我们来看下"单链表(LinkList)".在上一篇<C#数据结构之顺序表(SeqList)实例详解>的最后,我们指出了:顺序表要求开辟一组连续的内存空间,而且插入/删除元素时,为了保证元素的顺序性,必须对后面的元素进行移动.如果你的应用中需要频繁对元素进行插入/删除,那么开销会很大. 而链表结构正好相反,先来看下结构: 每个元素至少具有二个属性:data和next.data
-
C#数据结构与算法揭秘一
这里,我们 来说一说C#的数据结构了. ①什么是数据结构.数据结构,字面意思就是研究数据的方法,就是研究数据如何在程序中组织的一种方法.数据结构就是相互之间存在一种或多种特定关系的数据元素的集合. 程序界有一点很经典的话,程序设计=数据结构+算法.用源代码来体现,数据结构,就是编程.他有哪些具体的关系了, (1) 集合(Set):如图 1.1(a)所示,该结构中的数据元素除了存在"同属于一个集合"的关系外,不存在任何其它关系. 集合与数学的集合类似,有无序性,唯一性,确定性. (2)
-
C#数据结构之循环链表的实例代码
复制代码 代码如下: public class Node { public object Element; public Node Link; public Node() { Element = null; Link = null; } public Node(object theElement) { Element = theElement;
-
C#数据结构揭秘一
这里,我们 来说一说C#的数据结构了. ①什么是数据结构.数据结构,字面意思就是研究数据的方法,就是研究数据如何在程序中组织的一种方法.数据结构就是相互之间存在一种或多种特定关系的数据元素的集合. 程序界有一点很经典的话,程序设计=数据结构+算法.用源代码来体现,数据结构,就是编程.他有哪些具体的关系了, (1) 集合(Set):如图 1.1(a)所示,该结构中的数据元素除了存在"同属于一个集合"的关系外,不存在任何其它关系. 集合与数学的集合类似,有无序性,唯一性,确定性. (2)
-
C#数据结构与算法揭秘四 双向链表
首先,明白什么是双向链表.所谓双向链表是如果希望找直接前驱结点和直接后继结点的时间复杂度都是 O(1),那么,需要在结点中设两个引用域,一个保存直接前驱结点的地址,叫 prev,一个直接后继结点的地址,叫 next,这样的链表就是双向链表(Doubly Linked List).双向链表的结点结构示意图如图所示. 双向链表结点的定义与单链表的结点的定义很相似, ,只是双向链表多了一个字段 prev.其实,双向链表更像是一根链条一样,你连我,我连你,不清楚,请看图. 双向链表结点类的实现如下所示
-
C#数据结构与算法揭秘五 栈和队列
这节我们讨论了两种好玩的数据结构,栈和队列. 老样子,什么是栈, 所谓的栈是栈(Stack)是操作限定在表的尾端进行的线性表.表尾由于要进行插入.删除等操作,所以,它具有特殊的含义,把表尾称为栈顶(Top) ,另一端是固定的,叫栈底(Bottom) .当栈中没有数据元素时叫空栈(Empty Stack).这个类似于送饭的饭盒子,上层放的是红烧肉,中层放的水煮鱼,下层放的鸡腿.你要把这些菜取出来,这就引出来了栈的特点先进后出(First in last out). 具体叙述,加下图. 栈通常记
-
C#常用数据结构和算法总结
1.数据 数据(Data)是外部世界信息的载体, 是能够被计算机识别,加工,存储的.在现实生活中也就是我们的产品原材料. 计算机中的数据包括数值数据,图片,影音资料等. 2. 数据元素和数据项 数据元素(Data Element)是数据的基本单位,在计算机处理的过程中通常是作为一个整体来作为处理的. 数据项(Data Item):一个数据元素通常由一个或多个数据项组成. 比如数据库表:(Student),它有Id,Name,Sex,Age,Address等字段,而这张表又有多行数据.我们通常将这
-
C#数据结构与算法揭秘三 链表
上文我们讨论了一种最简单的线性结构--顺序表,这节我们要讨论另一种线性结构--链表. 什么是链表了,不要求逻辑上相邻的数据元素在物理存储位置上也相邻存储的线性结构称之为链表.举个现实中的例子吧,假如一个公司召开了视频会议的吧,能在北京总公司人看到上海分公司的人,他们就好比是逻辑上相邻的数据元素,而物理上不相连.这样就好比是个链表. 链表分为①单链表,②单向循环链表,③双向链表,④双向循环链表. 介绍各种各样链表之前,我们要明白这样一个概念.什么是结点.在存储数据元素时,除了存储数据元素本身的信息
-
C#构建树形结构数据(全部构建,查找构建)
摘要: 最近在做任务管理,任务可以无限派生子任务且没有数量限制,前端采用Easyui的Treegrid树形展示控件. 一.遇到的问题 获取全部任务拼接树形速度过慢(数据量大约在900条左右)且查询速度也并不快: 二.解决方法 1.Tree转化的JSON数据格式 a.JSON数据格式: [ { "children":[ { "children":[ ], "username":"username2", "passwor
-
Java构建树形菜单的实例代码(支持多级菜单)
效果图:支持多级菜单. 菜单实体类: public class Menu { // 菜单id private String id; // 菜单名称 private String name; // 父菜单id private String parentId; // 菜单url private String url; // 菜单图标 private String icon; // 菜单顺序 private int order; // 子菜单 private List<Menu> children;
-
springboot构造树形结构数据并查询的方法
因为项目需要,页面上需要树形结构的数据进行展示(类似下图这样),因此需要后端返回相应格式的数据. 不说废话,直接开干!!! 我这里用的是springboot+mybatis-plus+mysql,示例的接口是查询一级权限以及二级权限.三级权限整个权限树- 下面是导入的maven依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-
-
JS使用reduce()方法处理树形结构数据
定义 reduce() 方法对数组中的每个元素执行一个由您提供的reducer函数(升序执行),将其结果汇总为单个返回值. reduce() 与forEach().map().filter()这些方法一样,也会对数组中的每一项进行遍历,但是reduce() 可以将遍历的前一个数组项产生的结果与当前遍历项进行运算. 语法 array.reduce(function(prev, cur, index, array){ ... }, init); 回调函数中的参数: prev 必需.表示调用回调时的返
-
JSON复杂数据处理之Json树形结构数据转Java对象并存储到数据库的实现
在网站开发中经常遇到级联数据的展示,比如选择城市的时候弹出的省市县选择界面.很多前端制作人员习惯于从JSON中而不是从数据库中获取省市县数据.那么在选择了省市县中的某一个城市 ,存储到数据库中需要存储所选城市的代码.所以需要一个能将JSON数据(一般存储在javascript脚本中)结构全部导入到数据库中的功能. JSON的特点是支持层级结构.支持数组表示的对象 .下面的示例介绍如何将JSON的省市县数据保存到数据库中,实现原理非常简单,就是利用JSON的java工具包API,将层次结构的JSO
-
Go语言实现的树形结构数据比较算法实例
本文实例讲述了Go语言实现的树形结构数据比较算法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: // Two binary trees may be of different shapes, // but have the same contents. For example: // // 4 6 // 2 6 4 7 // 1 3 5 7 2 5 //
-
php实现的树形结构数据存取类实例
本文实例讲述了php实现的树形结构数据存取类.分享给大家供大家参考. 具体实现代码如下: 复制代码 代码如下: <?php /** * Tanphp framework * * * @category Tanphp * @package Data_structure * @version $Id: Tree.php 25024 2012-11-26 22:22:22 tanbo $ */ /** * 树形结构数据存取类 * * 用于对树形结构数据进行快速
-
Java 递归查询部门树形结构数据的实践
说明:在开发中,我们经常使用树形结构来展示菜单选项,如图: 那么我们在后端怎么去实现这样的一个功能呢? 1.数据库表:department 2.编写sql映射语句 <select id="selectDepartmentTrees" resultType="com.welb.entity.Department"> select * from department <where> <if test="updepartmentco
-
Java树形结构数据生成导出excel文件方法记录
目录 什么是树形结构数据 效果 用法 源码 总结 什么是树形结构数据 效果 用法 String jsonStr = "{\"name\":\"aaa\",\"children\":[{\"name\":\"bbb\",\"children\":[{\"name\":\"eee\"},{\"name\":\"f
-
JavaScript数组扁平转树形结构数据(Tree)的实现
前言 之前面试有遇到过这个问题,面试官问:如何把一个数组数据扁平,然后转化为Tree结构数据,工作中刚好也用到了,在这里总结一下. 需求大致如下 把这个数组转为树形结构数据(Tree) const flatArr = [ { id: '01', parentId: 0, name: '节点1' }, { id: '011', parentId: '01', name: '节点1-1' }, { id: '0111', parentId: '011', name: '节点1-1-1' }, { i