Redis Cluster集群数据分片机制原理
Redis Cluster数据分片机制
Redis 集群简介
Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求。
Redis Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。

如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
一般来说,主 Redis 节点会处理 Clients 的读写操作,而从节点只处理读操作。
数据分片策略
分布式数据存储方案中最为重要的一点就是数据分片,也就是所谓的 Sharding。
为了使得集群能够水平扩展,首要解决的问题就是如何将整个数据集按照一定的规则分配到多个节点上,常用的数据分片的方法有:范围分片,哈希分片,一致性哈希算法和虚拟哈希槽等。
范围分片假设数据集是有序,将顺序相临近的数据放在一起,可以很好的支持遍历操作。范围分片的缺点是面对顺序写时,会存在热点。比如日志类型的写入,一般日志的顺序都是和时间相关的,时间是单调递增的,因此写入的热点永远在最后一个分片。

对于关系型的数据库,因为经常性的需要表扫描或者索引扫描,基本上都会使用范围的分片策略。
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:slot = CRC16(key) & 16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
Redis 虚拟槽分区的特点:
解耦数据和节点之间的关系,简化了节点扩容和收缩难度。节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据支持节点、槽和键之间的映射查询,用于数据路由,在线集群伸缩等场景。
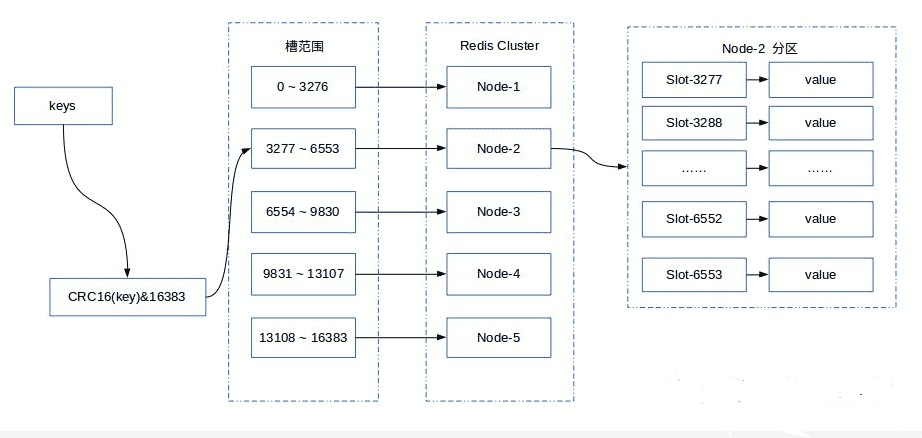
Redis 集群提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容。可以说,槽是 Redis 集群管理数据的基本单位,集群伸缩就是槽和数据在节点之间的移动。
下面我们就先来看一下 Redis 集群伸缩的原理。然后再了解当 Redis 节点数据迁移过程中或者故障恢复时如何保证集群可用。
扩容集群
为了让读者更好的理解上线节点时的扩容操作,我们通过 Redis Cluster 的命令来模拟整个过程。

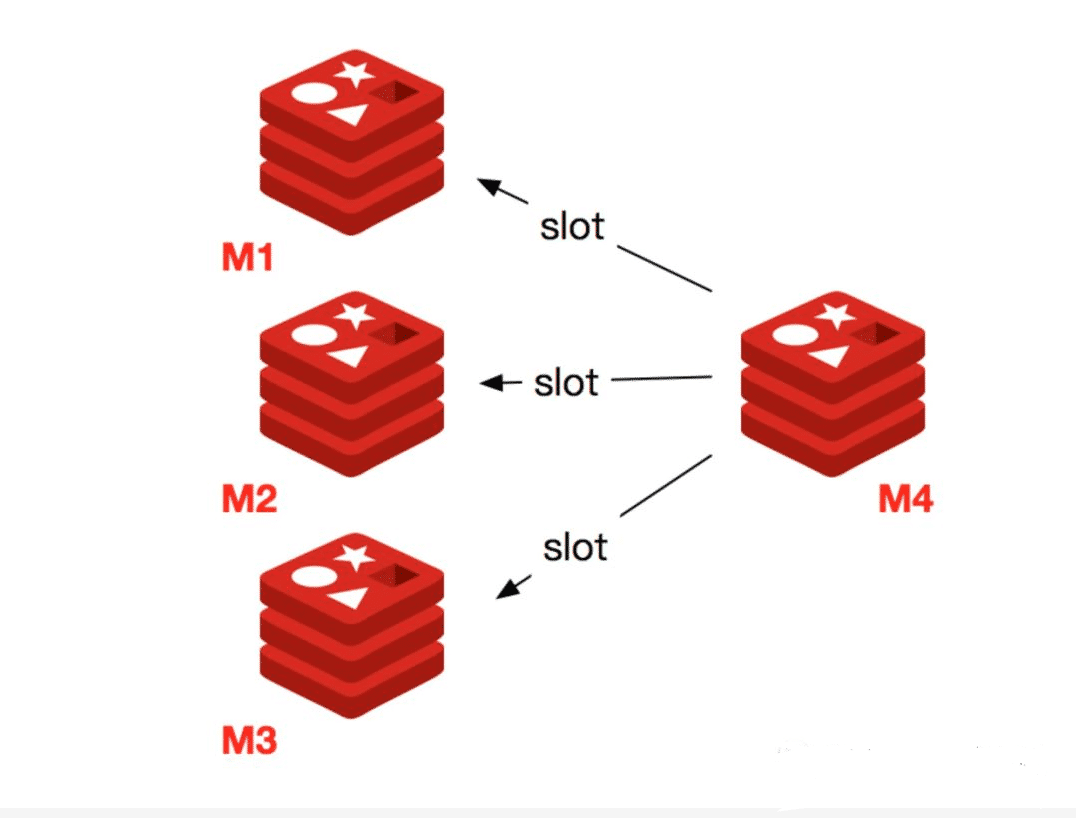
当一个 Redis 新节点运行并加入现有集群后,我们需要为其迁移槽和数据。首先要为新节点指定槽的迁移计划,确保迁移后每个节点负责相似数量的槽,从而保证这些节点的数据均匀。
1) 首先启动一个 Redis 节点,记为 M4。
2) 使用 cluster meet 命令,让新 Redis 节点加入到集群中。新节点刚开始都是主节点状态,由于没有负责的>槽,所以不能接受任何读写操作,后续我们就给他迁移槽和填充数据。
3) 对 M4 节点发送 cluster setslot { slot } importing { sourceNodeId } 命令,让目标节点准备导入槽的数据。
4) 对源节点,也就是 M1,M2,M3 节点发送 cluster setslot { slot } migrating { targetNodeId } 命令,让源节>点准备迁出槽的数据。
5) 源节点执行 cluster getkeysinslot { slot } { count } 命令,获取 count 个属于槽 { slot } 的键,然后执行步骤>六的操作进行迁移键值数据。
6) 在源节点上执行 migrate { targetNodeIp} " " 0 { timeout } keys { key... } 命令,把获取的键通过 pipeline 机制>批量迁移到目标节点,批量迁移版本的 migrate 命令在 Redis 3.0.6 以上版本提供。
7) 重复执行步骤 5 和步骤 6 直到槽下所有的键值数据迁移到目标节点。
8) 向集群内所有主节点发送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配给目标节点。为了>保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽执行新节点。
收缩集群
收缩节点就是将 Redis 节点下线,整个流程需要如下操作流程。
1) 首先需要确认下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
2) 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记改节点后可以正常关闭。
下线节点需要将节点自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。
迁移完槽后,还需要通知集群内所有节点忘记下线的节点,也就是说让其他节点不再与要下线的节点进行 Gossip 消息交换。
Redis 集群使用 cluster forget { downNodeId } 命令来讲指定的节点加入到禁用列表中,在禁用列表内的节点不再发送 Gossip 消息。
客户端路由
在集群模式下,Redis 节点接收任何键相关命令时首先计算键对应的槽,在根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复 MOVED 重定向错误,通知客户端请求正确的节点。这个过程称为 MOVED 重定向。
需要注意的是 Redis 计算槽时并非只简单的计算键值内容,当键值内容包括大括号时,则只计算括号内的内容。比如说,key 为 user:{10000}:books时,计算哈希值只计算10000。
MOVED 错误示例显示的信息如下,键 x 所属的哈希槽 3999 ,以及负责处理这个槽的节点的 IP 和端口号 127.0.0.1:6381 。 客户端需要根据这个 IP 和端口号, 向所属的节点重新发送一次 GET 命令请求。
<codeclass="hljs"></code>
由于请求重定向会增加 IO 开销,这不是 Redis 集群高效的使用方式,而是要使用 Smart 集群客户端。Smart 客户端通过在内部维护 slot 到 Redis 节点的映射关系,本地就可以实现键到节点的查找,从而保证 IO 效率的最大化,而 MOVED 重定向负责协助客户端更新映射关系。
Redis 集群支持在线迁移槽( slot ) 和数据来完成水平伸缩,当 slot 对应的数据从源节点到目标节点迁移过程中,客户端需要做到智能迁移,保证键命令可正常执行。例如当 slot 数据从源节点迁移到目标节点时,期间可能出现一部分数据在源节点,而另一部分在目标节点。

所以,综合上述情况,客户端命令执行流程如下所示:
- 客户端根据本地 slot 缓存发送命令到源节点,如果存在键对应则直接执行并返回结果给客户端。
- 如果节点返回 MOVED 错误,更新本地的 slot 到 Redis 节点的映射关系,然后重新发起请求。
- 如果数据正在迁移中,节点会回复 ASK 重定向异常。格式如下: ( error ) ASK { slot } { targetIP } : { targetPort }
客户端从 ASK 重定向异常提取出目标节点信息,发送 asking 命令到目标节点打开客户端连接标识,再执行键命令。
ASK 和 MOVED 虽然都是对客户端的重定向控制,但是有着本质区别。ASK 重定向说明集群正在进行 slot 数据迁移,客户端无法知道什么时候迁移完成,因此只能是临时性的重定向,客户端不会更新 slot 到 Redis 节点的映射缓存。但是 MOVED 重定向说明键对应的槽已经明确指定到新的节点,因此需要更新 slot 到 Redis 节点的映射缓存。
故障转移
当 Redis 集群内少量节点出现故障时通过自动故障转移保证集群可以正常对外提供服务。
当某一个 Redis 节点客观下线时,Redis 集群会从其从节点中通过选主选出一个替代它,从而保证集群的高可用性。这块内容并不是本文的核心内容,感兴趣的同学可以自己学习。
但是,有一点要注意。默认情况下,当集群 16384 个槽任何一个没有指派到节点时整个集群不可用。执行任何键命令返回 CLUSTERDOWN Hash slot not served 命令。当持有槽的主节点下线时,从故障发现到自动完成转移期间整个集群是不可用状态,对于大多数业务无法忍受这情况,因此建议将参数 cluster-require-full-coverage 配置为 no ,当主节点故障时只影响它负责槽的相关命令执行,不会影响其他主节点的可用性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Redis Cluster添加、删除的完整操作步骤
前言 最近学习了Redis,发现Redis还是挺好玩的,今天测试了集群的添加.删除节点.重分配slot等.更深入的理解redis的游戏规则.步骤繁多,但是详细,话不多说了,来一起看看详细的介绍吧. 环境解释: 我是在一台Centos 6.9上测试的,各个redis节点以端口号区分.文中针对各个redis,我只是以端口号代表. ~~~~Master Node~~~~~ 172.16.32.116:7000 172.16.32.116:7001 172.16.32.116:7002 ~~~~Slav
-
Spring-data-redis操作redis cluster的示例代码
Redis 3.X版本引入了集群的新特性,为了保证所开发系统的高可用性项目组决定引用Redis的集群特性.对于Redis数据访问的支持,目前主要有二种方式:一.以直接调用jedis来实现:二.使用spring-data-redis,通过spring的封装来调用.下面分别对这二种方式如何操作Redis进行说明. 一.利用Jedis来实现 通过Jedis操作Redis Cluster的模型可以参考Redis官网,具体如下: Set<HostAndPort> jedisClusterNodes =
-
Windows环境下Redis Cluster环境搭建(图文)
搭建 Redis集群,三个主节点,三个从节点,多主节点为了分布集群,从节点是为了高可用性. 1. 下载redis 地址:https://github.com/MicrosoftArchive/redis/releases 此次案例中使用的版本为3.0.503 Source code可以一起下载,下文会用到. 2. 安装redis 解压Redis-x64-3.0.503.zip,并复制,如下图 3. 修改每台redis.windows.conf,修改里面的端口号,以及集群的配置 port 6380
-
spring集成redis cluster详解
客户端采用最新的jedis 2.7 1.maven依赖: <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.7.3</version> </dependency> 2.增加spring 配置 <bean name="genericObjectPoolConfig"
-

Redis Cluster的图文讲解
1.1 Redis-Cluster简介 1.1.1 什么是Redis-Cluster 为何要搭建Redis集群.Redis是在内存中保存数据的,而我们的电脑一般内存都不大,这也就意味着Redis不适合存储大数据,适合存储大数据的是Hadoop生态系统的Hbase或者是MogoDB.Redis更适合处理高并发,一台设备的存储能力是很有限的,但是多台设备协同合作,就可以让内存增大很多倍,这就需要用到集群. Redis集群搭建的方式有多种,例如使用客户端分片.Twemproxy.Codis等,但从re
-
php成功操作redis cluster集群的实例教程
前言 java操作redis cluster集群可使用jredis php要操作redis cluster集群有两种方式: 1.使用phpredis扩展,这是个c扩展,性能更高,但是phpredis2.x扩展不行,需升级phpredis到3.0,但这个方案参考资料很少 2.使用predis,纯php开发,使用了命名空间,需要php5.3+,灵活性高 我用的是predis,下载地址:点击这里 步骤如下: 下载好后重命名为predis, server1:192.168.1.198 server2:1
-
Redis cluster集群的介绍
1.前言 Redis集群模式主要有2种: 主从集群.分布式集群. 前者主要是为了高可用或是读写分离,后者为了更好的存储数据,负载均衡. redis集群提供了以下两个好处 1.将数据自动切分(split)到多个节点 2.当集群中的某一个节点故障时,redis还可以继续处理客户端的请求. 一个 redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个.集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽.集群中
-
如何用docker部署redis cluster的方法
前言 由于本人是个docker控,不喜欢安装各种环境,而且安装redis-trib也有点繁琐,索性用docker来做redis cluster. 本文用的是伪集群,真正的集群放到不同的机器即可.端口是7001-7006. 工作目录: /data/redis 创建文件夹 首先创建一堆对应端口的文件夹,下面是脚本 create.sh for i in `seq 7001 7006` do mkdir -p ${i}/data done 添加执行权限并执行 chmod 777 create.sh ./
-
Redis Cluster集群数据分片机制原理
Redis Cluster数据分片机制 Redis 集群简介 Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求. Redis Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点.三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点. 如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S
-
Redis Cluster集群动态扩容的实现
目录 一.引言 二.Cluster集群增加操作 1.动态增加Master主服务器节点 2.动态增加Slave从服务器节点 三.Cluster集群删除操作 1.动态删除Slave从服务器节点 2.动态删除Master主服务器节点 四.总结 一.引言 上一篇文章我们一步一步的教大家搭建了Redis的Cluster集群环境,形成了3个主节点和3个从节点的Cluster的环境.当然,大家可以使用 Cluster info 命令查看Cluster集群的状态,也可以使用Cluster Nodes 命令来详细
-
分布式Redis Cluster集群搭建与Redis基本用法
目录 Redis集群搭建 Redis是啥 集群(Cluster) RedisCluster说明 RedisCluster节点 RedisCluster集群模式 不能保证一致性 创建和使用Redis集群 部署三个主节点 非docker docker安装 创建集群 Redis入门 Redis中的数据类型 字符串(string) 哈希(Hash) 列表(Lists) 集合(Set) 有序集合(sortedset) Redis 集群搭建 Redis 是啥 Redis(全称 REmote DIctiona
-
基于Redis6.2.6版本部署Redis Cluster集群的问题
目录 1.Redis6.2.6简介以及环境规划 2.二进制安装Redis程序 2.1.二进制安装redis6.2.6 2.2.创建Reids Cluster集群目录 3.配置Redis Cluster三主三从交叉复制集群 3.1.准备六个节点的redis配置文件 3.2.将六个节点全部启动 3.3.配置集群节点之间相互发现 3.4.为集群中的充当Master的节点分配槽位 3.5.配置三主三从交叉复制模式 4.快速搭建Redis Cluster集群 1.Redis6.2.6简介以及环境规划 在R
-
k8s部署redis cluster集群的实现
Redis 介绍 Redis代表REmote DIctionary Server是一种开源的内存中数据存储,通常用作数据库,缓存或消息代理.它可以存储和操作高级数据类型,例如列表,地图,集合和排序集合. 由于Redis接受多种格式的密钥,因此可以在服务器上执行操作,从而减少了客户端的工作量. 它仅将磁盘用于持久性,而将数据完全保存在内存中. Redis是一种流行的数据存储解决方案,并被GitHub,Pinterest,Snapchat,Twitter,StackOverflow,Flickr等技
-
Redis Cluster 集群搭建你会吗
三台机器 201.202.203,每台机器装两个 redis 实例,构建 redis cluster 集群. 1. 安装 添加 redis-cluster 目录,将 redis 压缩包拷贝到该目录下,解压压缩包. 解压完后,将文件夹 redis-5.0.3 重命名为 redis1. [root@test201 redis-cluster]# mv redis-5.0.3 redis1 需要在 redis1 目录下使用 make 命令进行编译. [root@test201 redis-cluste
-
Redis Cluster集群收缩主从节点详细教程
目录 1.Cluster集群收缩概念 2.将6390主节点从集群中收缩 2.1.计算需要分给每一个节点的槽位数 2.2.分配1365个槽位给192.168.81.210的6380节点 2.3.分配1365个槽位给192.168.81.220的6380节点 2.4.分配1365个槽位给192.168.81.230的6380节点 2.5.查看当前集群槽位分配 3.验证数据迁移过程是否导致数据异常 4.将下线的主节点从集群中删除 4.1.删除节点 4.2.调整主从交叉复制 4.3.当节点存在数据无法删
-
Redis cluster集群模式的原理解析
redis cluster redis cluster是Redis的分布式解决方案,在3.0版本推出后有效地解决了redis分布式方面的需求 自动将数据进行分片,每个master上放一部分数据 提供内置的高可用支持,部分master不可用时,还是可以继续工作的 支撑N个redis master node,每个master node都可以挂载多个slave node 高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave