Python 并行化执行详细解析
目录
- 例子:N体问题
- 普通计算方法
- 效果图
- Python 并行化执行
- 再举一个例子
前言:
并行编程比程序编程困难,除非正常编程需要创建大量数据,计算耗时太长,物理行为模拟困难
例子:N体问题
物理前提:
- 牛顿定律
- 时间离散运动方程
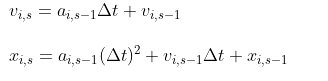
普通计算方法
import numpy as np
import time
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
Ns = [2**i for i in range(1,10)]
runtimes = []
def remove_i(x,i):
"从所有粒子中去除本粒子"
shape = (x.shape[0]-1,)+x.shape[1:]
y = np.empty(shape,dtype=float)
y[:i] = x[:i]
y[i:] = x[i+1:]
return y
def a(i,x,G,m):
"计算加速度"
x_i = x[i]
x_j = remove_i(x,i)
m_j = remove_i(m,i)
diff = x_j - x_i
mag3 = np.sum(diff**2,axis=1)**1.5
result = G * np.sum(diff * (m_j / mag3)[:,np.newaxis],axis=0)
return result
def timestep(x0,v0,G,m,dt):
N = len(x0)
x1 = np.empty(x0.shape,dtype=float)
v1 = np.empty(v0.shape,dtype=float)
for i in range(N):
a_i0 = a(i,x0,G,m)
v1[i] = a_i0 * dt + v0[i]
x1[i] = a_i0 * dt**2 + v0[i] * dt + x0[i]
return x1,v1
def initial_cond(N,D):
x0 = np.array([[1,1,1],[10,10,10]])
v0 = np.array([[10,10,1],[0,0,0]])
m = np.array([10,10])
return x0,v0,m
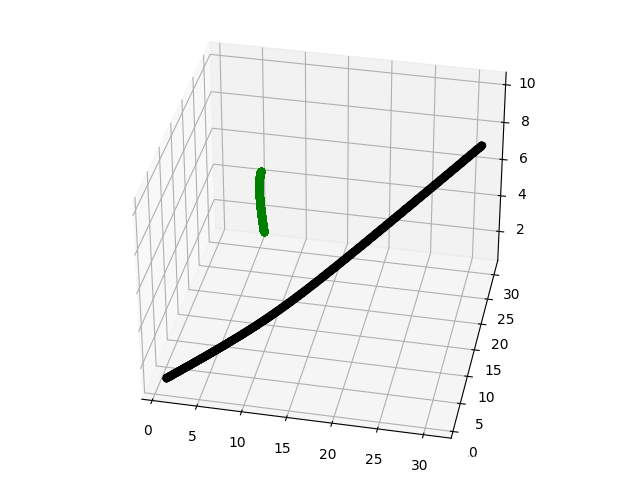
def stimulate(N,D,S,G,dt):
fig = plt.figure()
ax = Axes3D(fig)
x0,v0,m = initial_cond(N,D)
for s in range(S):
x1,v1 = timestep(x0,v0,G,m,dt)
x0,v0 = x1,v1
t = 0
for i in x0:
ax.scatter(i[0],i[1],i[2],label=str(s*dt),c=["black","green","red"][t])
t += 1
t = 0
plt.show()
start = time.time()
stimulate(2,3,3000,9.8,1e-3)
stop = time.time()
runtimes.append(stop - start)
效果图
Python 并行化执行
首先我们给出一个可以用来写自己的并行化程序的,额,一串代码
import datetime
import multiprocessing as mp
def accessional_fun():
f = open("accession.txt","r")
result = float(f.read())
f.close()
return result
def final_fun(name, param):
result = 0
for num in param:
result += num + accessional_fun() * 2
return {name: result}
if __name__ == '__main__':
start_time = datetime.datetime.now()
num_cores = int(mp.cpu_count())
print("你使用的计算机有: " + str(num_cores) + " 个核,当然了,Intel 7 以上的要除以2")
print("如果你使用的 Python 是 32 位的,注意数据量不要超过两个G")
print("请你再次检查你的程序是否已经改成了适合并行运算的样子")
pool = mp.Pool(num_cores)
param_dict = {'task1': list(range(10, 300)),
'task2': list(range(300, 600)),
'task3': list(range(600, 900)),
'task4': list(range(900, 1200)),
'task5': list(range(1200, 1500)),
'task6': list(range(1500, 1800)),
'task7': list(range(1800, 2100)),
'task8': list(range(2100, 2400)),
'task9': list(range(2400, 2700)),
'task10': list(range(2700, 3000))}
results = [pool.apply_async(final_fun, args=(name, param)) for name, param in param_dict.items()]
results = [p.get() for p in results]
end_time = datetime.datetime.now()
use_time = (end_time - start_time).total_seconds()
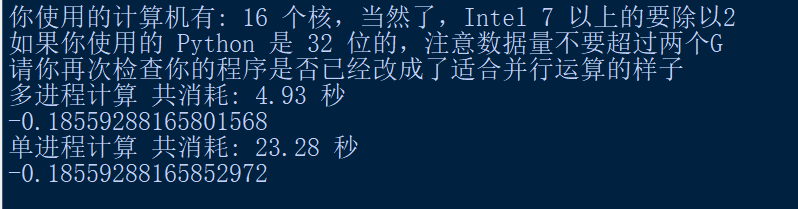
print("多进程计算 共消耗: " + "{:.2f}".format(use_time) + " 秒")
print(results)
运行结果:如下:

accession.txt 里的内容是2.5 这就是一个累加的问题,每次累加的时候都会读取文件中的2.5
如果需要运算的问题是类似于累加的问题,也就是可并行运算的问题,那么才好做出并行运算的改造
再举一个例子
import math
import time
import multiprocessing as mp
def final_fun(name, param):
result = 0
for num in param:
result += math.cos(num) + math.sin(num)
return {name: result}
if __name__ == '__main__':
start_time = time.time()
num_cores = int(mp.cpu_count())
print("你使用的计算机有: " + str(num_cores) + " 个核,当然了,Intel 7 以上的要除以2")
print("如果你使用的 Python 是 32 位的,注意数据量不要超过两个G")
print("请你再次检查你的程序是否已经改成了适合并行运算的样子")
pool = mp.Pool(num_cores)
param_dict = {'task1': list(range(10, 3000000)),
'task2': list(range(3000000, 6000000)),
'task3': list(range(6000000, 9000000)),
'task4': list(range(9000000, 12000000)),
'task5': list(range(12000000, 15000000)),
'task6': list(range(15000000, 18000000)),
'task7': list(range(18000000, 21000000)),
'task8': list(range(21000000, 24000000)),
'task9': list(range(24000000, 27000000)),
'task10': list(range(27000000, 30000000))}
results = [pool.apply_async(final_fun, args=(name, param)) for name, param in param_dict.items()]
results = [p.get() for p in results]
end_time = time.time()
use_time = end_time - start_time
print("多进程计算 共消耗: " + "{:.2f}".format(use_time) + " 秒")
result = 0
for i in range(0,10):
result += results[i].get("task"+str(i+1))
print(result)
start_time = time.time()
result = 0
for i in range(10,30000000):
result += math.cos(i) + math.sin(i)
end_time = time.time()
print("单进程计算 共消耗: " + "{:.2f}".format(end_time - start_time) + " 秒")
print(result)
运行结果:
力学问题改进:
import numpy as np
import time
from mpi4py import MPI
from mpi4py.MPI import COMM_WORLD
from types import FunctionType
from matplotlib import pyplot as plt
from multiprocessing import Pool
def remove_i(x,i):
shape = (x.shape[0]-1,) + x.shape[1:]
y = np.empty(shape,dtype=float)
y[:1] = x[:1]
y[i:] = x[i+1:]
return y
def a(i,x,G,m):
x_i = x[i]
x_j = remove_i(x,i)
m_j = remove_i(m,i)
diff = x_j - x_i
mag3 = np.sum(diff**2,axis=1)**1.5
result = G * np.sum(diff * (m_j/mag3)[:,np.newaxis],axis=0)
return result
def timestep(x0,v0,G,m,dt,pool):
N = len(x0)
takes = [(i,x0,v0,G,m,dt) for i in range(N)]
results = pool.map(timestep_i,takes)
x1 = np.empty(x0.shape,dtype=float)
v1 = np.empty(v0.shape,dtype=float)
for i,x_i1,v_i1 in results:
x1[i] = x_i1
v1[i] = v_i1
return x1,v1
def timestep_i(args):
i,x0,v0,G,m,dt = args
a_i0 = a(i,x0,G,m)
v_i1 = a_i0 * dt + v0[i]
x_i1 = a_i0 * dt ** 2 +v0[i]*dt + x0[i]
return i,x_i1,v_i1
def initial_cond(N,D):
x0 = np.random.rand(N,D)
v0 = np.zeros((N,D),dtype=float)
m = np.ones(N,dtype=float)
return x0,v0,m
class Pool(object):
def __init__(self):
self.f = None
self.P = COMM_WORLD.Get_size()
self.rank = COMM_WORLD.Get_rank()
def wait(self):
if self.rank == 0:
raise RuntimeError("Proc 0 cannot wait!")
status = MPI.Status()
while True:
task = COMM_WORLD.recv(source=0,tag=MPI.ANY_TAG,status=status)
if not task:
break
if isinstance(task,FunctionType):
self.f = task
continue
result = self.f(task)
COMM_WORLD.isend(result,dest=0,tag=status.tag)
def map(self,f,tasks):
N = len(tasks)
P = self.P
Pless1 = P - 1
if self.rank != 0:
self.wait()
return
if f is not self.f:
self.f = f
requests = []
for p in range(1,self.P):
r = COMM_WORLD.isend(f,dest=p)
requests.append(r)
MPI.Request.waitall(requests)
results = []
for i in range(N):
result = COMM_WORLD.recv(source=(i%Pless1)+1,tag=i)
results.append(result)
return results
def __del__(self):
if self.rank == 0:
for p in range(1,self.p):
COMM_WORLD.isend(False,dest=p)
def simulate(N,D,S,G,dt):
x0,v0,m = initial_cond(N,D)
pool = Pool()
if COMM_WORLD.Get_rank()==0:
for s in range(S):
x1,v1 = timestep(x0,v0,G,m,dt,pool)
x0,v0 = x1,v1
else:
pool.wait()
if __name__ == '__main__':
simulate(128,3,300,1.0,0.001)
Ps = [1,2,4,8]
runtimes = []
for P in Ps:
start = time.time()
simulate(128,3,300,1.0,0.001)
stop = time.time()
runtimes.append(stop - start)
print(runtimes)
到此这篇关于Python 并行化执行详细解析的文章就介绍到这了,更多相关Python 并行化执行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 基于Appium控制多设备并行执行
前言: 如何做到,控制多设备并行执行测试用例呢. 思路篇 我们去想下,我们可以获取参数的信息,和设备的信息,那么我们也可以针对每台设备开启不一样的端口服务.那么每个服务都对应的端口,我们在获取设备列表的时候,要和 每个服务对应起来,这样,我们开启一个进城池,我们在进程池里去控制设备,每个进程池 控制不一样的设备即可. 实现篇 首先实现对应的参数篇和对应的设备端口, def startdevicesApp(): l_devices_list=[] port_list=[]
-
python 串行执行和并行执行实例
我就废话不多说了,大家还是直接看代码吧! #coding=utf-8 import threading import time import cx_Oracle from pprint import pprint import csv print time.asctime() table_name = "dbtest.csv" f = open(table_name + ".csv", "w") conn = cx_Oracle.connect(
-

Python 并行化执行详细解析
目录 例子:N体问题 普通计算方法 效果图 Python 并行化执行 再举一个例子 前言: 并行编程比程序编程困难,除非正常编程需要创建大量数据,计算耗时太长,物理行为模拟困难 例子:N体问题 物理前提: 牛顿定律 时间离散运动方程 普通计算方法 import numpy as np import time import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D Ns = [2**i for i in ran
-
Python 对象序列化与反序列化之pickle json详细解析
目录 引言 pickle json 尾语 引言 将对象的状态信息转换为可以存储或传输的形式的过程叫作序列化 类似地从序列化后的数据转换成相对应的对象叫作 反序列化 本文介绍 Python 将对象序列化和反序化的两个模块 picklejson pickle pickle # 序列化 In [19]: num = 66 In [20]: s = 'python' In [21]: pi = 3.14 In [22]: li = [1, 2, 3] In [27]: b_num = pickle.du
-
python 日志 logging模块详细解析
Python 中的 logging 模块可以让你跟踪代码运行时的事件,当程序崩溃时可以查看日志并且发现是什么引发了错误.Log 信息有内置的层级--调试(debugging).信息(informational).警告(warnings).错误(error)和严重错误(critical).你也可以在 logging 中包含 traceback 信息.不管是小项目还是大项目,都推荐在 Python 程序中使用 logging.本文给大家介绍python 日志 logging模块 介绍. 1 基本使用
-
Python内置函数详细解析
目录 1.abs 2.all 3.any 4.callable 5.dir 6.id 7.locals 和 globals 8.hash 9.sum 10.getattr.setattr.delattr 前言: Python 自带了很多的内置函数,极大地方便了我们的开发,下面就来挑几个内置函数,看看底层是怎么实现的.内置函数位于 Python/bitlinmodule.c 中. 1.abs abs 的功能是取一个整数的绝对值,或者取一个复数的模. static PyObject * builti
-
python 特殊属性及方法详细解析
目录 概述 特殊属性 1. _ _ name _ _ 2._ _ bases _ _ 和_ _ base _ _ 以及 _ _ mro _ _ 3._ _ class _ _ 4._ _ dict _ _ 特殊方法 1. _ _ subclasses _ _ () 2._ _ new _ _ (). _ _ init _ _ ()和 _ _ del _ _ () 3._ _ repr _ _ ()和 _ _ str _ _ () 4._ _ call _ _ () 5._ _ lt _ _ ()
-
Python多重继承的方法解析执行顺序实例分析
本文实例讲述了Python多重继承的方法解析执行顺序.分享给大家供大家参考,具体如下: 任何实现多重继承的语言都要处理潜在的命名冲突, 这种冲突由不相关的祖先类实现同名方法引起 class A: def say(self): print("A Hello:", self) class B(A): def eat(self): print("B Eating:", self) class C(A): def eat(self): print("C Eatin
-
python 远程执行命令的详细代码
1.简单版 # coding: utf-8 import paramiko import re from time import sleep def ssh(): ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #指定当对方主机没有本机公钥的情况时应该怎么办,AutoAddPolicy表示自动在对方主机保存下本机的秘钥 ssh.connect('172.16.1.5',22,
-
python构造函数init实例方法解析
这篇文章主要介绍了python构造函数init实例方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.创建对象,我们需要定义构造函数__init__()方法.构造方法用于执行"实例对象的初始化工作",即对象创建后,初始化当前对象的属性,无返回值. __init__()要点如下: 1.名称固定,必须为__init__() 2.第一个参数固定,必须为self.self指的就是刚刚创建好的示例对象. 3.构造函数通常用来初始化示例属
-
python连接PostgreSQL过程解析
这篇文章主要介绍了python连接PostgreSQL过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1. 常用模块 # 连接数据库 connect()函数创建一个新的数据库连接对话并返回一个新的连接实例对象 PG_CONF_123 = { 'user':'emma', 'port':123, 'host':'192.168.1.123', 'password':'emma', 'database':'dbname'} conn = p
-
Python sys模块常用方法解析
这篇文章主要介绍了Python sys模块常用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 旨在记录 python sys 模块的常用方法 sys 模块常用方法及属性 sys.argv: 接收外部传递的参数. sys.exit([arg]): 程序退出,arg 为 0 正常退出. sys.getdefaultencoding(): 获取系统当前编码,一般默认为ascii. sys.setdefaultencoding(): 设置系统默