Python 爬取网页图片详解流程
简介
快乐在满足中求,烦恼多从欲中来
记录程序的点点滴滴。
输入一个网址从这个网址中解析出图片,并将它保存在本地
流程图
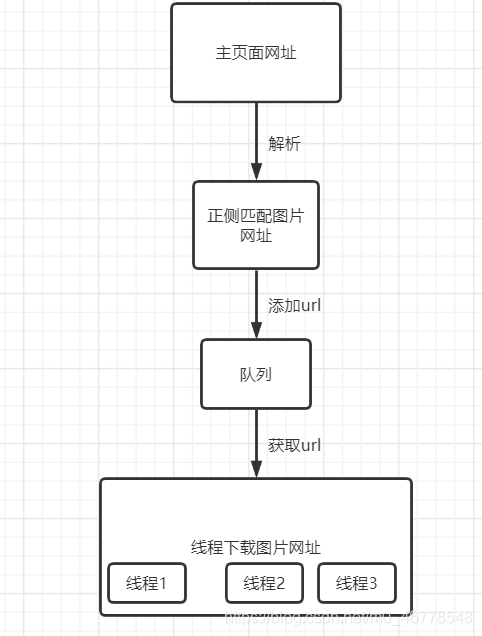
程序分析
解析主网址
def get_urls():
url = 'http://www.nipic.com/show/35350678.html' # 主网址
pattern = "(http.*?jpg)"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
r = requests.get(url,headers=header)
r.encoding = r.apparent_encoding
html = r.text
urls = re.findall(pattern,html)
return urls
url 为需要爬的主网址
pattern 为正则匹配
header 设置请求头
r = requests.get(url,headers=header) 发送请求
r.encoding = r.apparent_encoding 设置编码格式,防止出现乱码
| 属性 | 说明 |
|---|---|
| r.encoding | 从http header中提取响应内容编码 |
| r.apparent_encoding | 从内容中分析出的响应内容编码 |
urls = re.findall(pattern,html) 进行正则匹配
re.findall(pattern, string, flags=0)
正则 re.findall 的简单用法(返回string中所有与pattern相匹配的全部字串,返回形式为数组)
下载图片并存储
def download(url_queue: queue.Queue()):
while True:
url = url_queue.get()
root_path = 'F:\\1\\' # 图片存放的文件夹位置
file_path = root_path + url.split('/')[-1] #图片存放的具体位置
try:
if not os.path.exists(root_path): # 判断文件夹是是否存在,不存在则创建一个
os.makedirs(root_path)
if not os.path.exists(file_path): # 判断文件是否已存在
r = requests.get(url)
with open(file_path,'wb') as f:
f.write(r.content)
f.close()
print('图片保存成功')
else:
print('图片已经存在')
except Exception as e:
print(e)
print('线程名: ', threading.current_thread().name,"url_queue.size=", url_queue.qsize())
此函数需要传一个参数为队列
queue模块中提供了同步的、线程安全的队列类,queue.Queue()为一种先入先出的数据类型,队列实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步。
url_queue: queue.Queue() 这是一个队列类型的数据,是用来存储图片URL
url = url_queue.get() 从队列中取出一个url
url_queue.qsize() 返回队形内元素个数
全部代码
import requests
import re
import os
import threading
import queue
def get_urls():
url = 'http://www.nipic.com/show/35350678.html' # 主网址
pattern = "(http.*?jpg)"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
r = requests.get(url,headers=header)
r.encoding = r.apparent_encoding
html = r.text
urls = re.findall(pattern,html)
return urls
def download(url_queue: queue.Queue()):
while True:
url = url_queue.get()
root_path = 'F:\\1\\' # 图片存放的文件夹位置
file_path = root_path + url.split('/')[-1] #图片存放的具体位置
try:
if not os.path.exists(root_path):
os.makedirs(root_path)
if not os.path.exists(file_path):
r = requests.get(url)
with open(file_path,'wb') as f:
f.write(r.content)
f.close()
print('图片保存成功')
else:
print('图片已经存在')
except Exception as e:
print(e)
print('线程名:', threading.current_thread().name,"图片剩余:", url_queue.qsize())
if __name__ == "__main__":
url_queue = queue.Queue()
urls = tuple(get_urls())
for i in urls:
url_queue.put(i)
t1 = threading.Thread(target=download,args=(url_queue,),name="craw{}".format('1'))
t2 = threading.Thread(target=download,args=(url_queue,),name="craw{}".format('2'))
t1.start()
t2.start()
到此这篇关于Python 爬取网页图片详解流程的文章就介绍到这了,更多相关Python 爬取网页图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 爬取天气网卫星图片
项目地址: https://github.com/MrWayneLee/weather-demo 代码部分 下载生成文件功能 # 下载并生成文件 def downloadImg(imgDate, imgURLs, pathName): a,s,f = 0,0,0 timeStart = time.time() while a < len(imgURLs): req = requests.get(imgURLs[a]) imgName = str(imgURLs[a])[-13:-9] print
-
只用50行Python代码爬取网络美女高清图片
一.技术路线 requests:网页请求 BeautifulSoup:解析html网页 re:正则表达式,提取html网页信息 os:保存文件 import re import requests import os from bs4 import BeautifulSoup 二.获取网页信息 常规操作,获取网页信息的固定格式,返回的字符串格式的网页内容,其中headers参数可模拟人为的操作,'欺骗'网站不被发现 def getHtml(url): #固定格式,获取html内容 headers
-
Python爬取网站图片并保存的实现示例
先看看结果吧,去bilibili上拿到的图片=-= 第一步,导入模块 import requests from bs4 import BeautifulSoup requests用来请求html页面,BeautifulSoup用来解析html 第二步,获取目标html页面 hd = {'user-agent': 'chrome/10'} # 伪装自己是个(chrome)浏览器=-= def download_all_html(): try: url = 'https://www.bilibili
-
Python如何利用正则表达式爬取网页信息及图片
一.正则表达式是什么? 概念: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 个人理解: 简单来说就是使用正则表达式来写一个过滤器来过滤了掉杂乱的无用的信息(eg:网页源代码-)从中来获取自己想要的内容 二.实战项目 1.爬取内容 获取上海所有三甲医院的名称并保
-
Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
Python爬取动态网页中图片的完整实例
动态网页爬取是爬虫学习中的一个难点.本文将以知名插画网站pixiv为例,简要介绍动态网页爬取的方法. 写在前面 本代码的功能是输入画师的pixiv id,下载画师的所有插画.由于本人水平所限,所以代码不能实现自动登录pixiv,需要在运行时手动输入网站的cookie值. 重点:请求头的构造,json文件网址的查找,json中信息的提取 分析 创建文件夹 根据画师的id创建文件夹(相关路径需要自行调整). def makefolder(id): # 根据画师的id创建对应的文件夹 try: fol
-
python 爬取英雄联盟皮肤图片
一开始都是先去<英雄联盟>官网找到英雄及皮肤图片的网址: URL = r'https://lol.qq.com/data/info-heros.shtml' 从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号(如下图). 但是只有英雄的名字(英文)以及对应的编号并不能找到
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
Python 爬取网页图片详解流程
简介 快乐在满足中求,烦恼多从欲中来 记录程序的点点滴滴. 输入一个网址从这个网址中解析出图片,并将它保存在本地 流程图 程序分析 解析主网址 def get_urls(): url = 'http://www.nipic.com/show/35350678.html' # 主网址 pattern = "(http.*?jpg)" header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKi
-
java通过Jsoup爬取网页过程详解
这篇文章主要介绍了java通过Jsoup爬取网页过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,导入依赖 <!--java爬虫--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.3</version> </depe
-
Python获取网页数据详解流程
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单. 发送 GET 请求 当我们用浏览器打开东旭蓝天股票首页时,发送的最原始的请求就是 GET 请求,并传入url参数. import requests url='http://push2his.eastmoney.com/api/qt/stock/fflow/daykline/get' 用Python requests库的get函数得到数据并设置requests的请求头. header={ 'User-Agent'
-
基于Python的Post请求数据爬取的方法详解
为什么做这个 和同学聊天,他想爬取一个网站的post请求 观察 该网站的post请求参数有两种类型:(1)参数体放在了query中,即url拼接参数(2)body中要加入一个空的json对象,关于为什么要加入空的json对象,猜测原因为反爬虫.既有query参数又有空对象体的body参数是一件脑洞很大的事情. 一开始先在apizza网站 上了做了相关实验才发现上面这个规律的,并发现该网站的请求参数要为raw形式,要是直接写代码找规律不是一件容易的事情. 源码 import requests im
-
python实现AI聊天机器人详解流程
前言 开始几天,我是使用很原始的方法,自己去获取天气预报截图,再手动发送给小姐姐.连续几天之后我一想:不对呀,我怎么说也是一个程序猿,怎么能用这么 low 的方式呢. 联想起之前看到的一个开源 python 库-- wxpy,一个非常强大的微信 api 调用类库,正好满足我当前的需要,那话不多说,开干. 任务分解 调用微信 api 发送简单消息 获取当日天气预报截图信息 设置定时任务 调用微信 api 发送简单消息 本程序主要是通过 wxpy 库使用的,参考其官网文档,我们需要做如下准备工作:
-
Python爬取网页的所有内外链的代码
项目介绍 采用广度优先搜索方法获取一个网站上的所有外链. 首先,我们进入一个网页,获取网页的所有内链和外链,再分别进入内链中,获取该内链的所有内链和外链,直到访问完所有内链未知. 代码大纲 1.用class类定义一个队列,先进先出,队尾入队,队头出队: 2.定义四个函数,分别是爬取网页外链,爬取网页内链,进入内链的函数,以及调函数: 3.爬取百度图片(https://image.baidu.com/),先定义两个队列和两个数组,分别来存储内链和外链:程序开始时,先分别爬取当前网页的内链和外链,再
-
10分钟用Python快速搭建全文搜索引擎详解流程
有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个 代码所在 Git:https://github.com/asciimoo/searx 官方很贴心,很方便的是已经提供了docker 镜像,基本pull下来就可以很方便的使用了,执行命令 cid=$(sudo docker ps -a | grep searx | awk '{print $1}') echo searx cid is $cid if [ "$cid" != "" ];then su
-
Python导出并分析聊天记录详解流程
导出聊天记录生成词云看看你和对象聊了什么(可惜我没女朋友) 1.导出聊天记录打开消息管理器 导出的格式选择txt格式(我这里选择导出的路径是桌面所以在桌面上生成了一个包含聊天记录的.txt文件) 2.编写代码图中框出来的文本是我们不需要的(比如说图片会在这里面显示为[图片]表情显示为[表情]) 所以我们把它替换掉,我这里用到了正则: string = open(r'C:\\Users\\l1768\\Desktop\\消息记录.txt','r',encoding='utf-8').read()
-
浅谈Python爬取网页的编码处理
背景 中秋的时候,一个朋友给我发了一封邮件,说他在爬链家的时候,发现网页返回的代码都是乱码,让我帮他参谋参谋(中秋加班,真是敬业= =!),其实这个问题我很早就遇到过,之前在爬小说的时候稍微看了一下,不过没当回事,其实这个问题就是对编码的理解不到位导致的. 问题 很普通的一个爬虫代码,代码是这样的: # ecoding=utf-8 import re import requests import sys reload(sys) sys.setdefaultencoding('utf8') url