python人工智能human learn绘图可创建机器学习模型
目录
- 什么是 human-learn
- 安装 human-learn
- 互动绘图
- 创建模型并进行预测
- 预测新数据
- 解释结果
- 预测和评估测试数据
- 结论
如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则。
这些规则可用于预测新数据的标签。
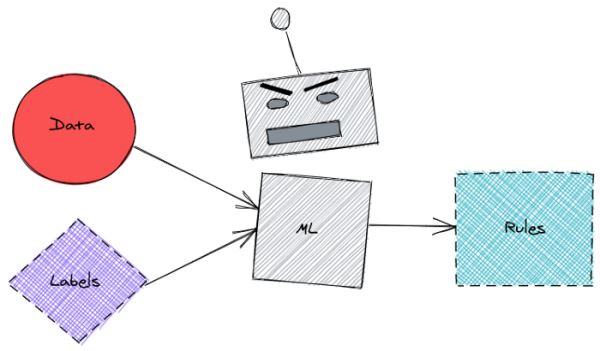
这很方便,但是在此过程中可能会丢失一些信息。也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测。
除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则?
是的,这可以通过 human-learn 来完成。
什么是 human-learn
human-learn 是一种工具,可让你使用交互式工程图和自定义模型来设置数据标记规则。在本文中,我们将探索如何使用 human-learn 来创建带有交互式图纸的模型。
安装 human-learn
pip install human-learn
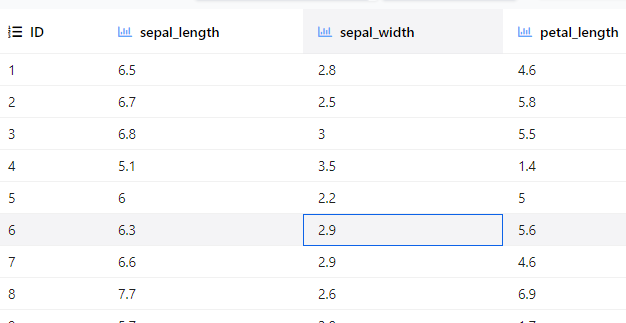
我将使用来自sklearn的Iris数据来展示human-learn的工作原理。
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import pandas as pd # Load data X, y = load_iris(return_X_y=True, as_frame=True) X.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] # Train test split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1) # Concatenate features and labels of the training data train = pd.concat([X_train, pd.DataFrame(y_train)], axis=1) train
互动绘图
human-learn 允许你绘制数据集,然后使用工程图将其转换为模型。 为了演示这是如何有用的,想象一下如何创建数据集的散点图,如下所示:

查看上面的图时,你会看到如何将它们分成3个不同的区域,如下所示:
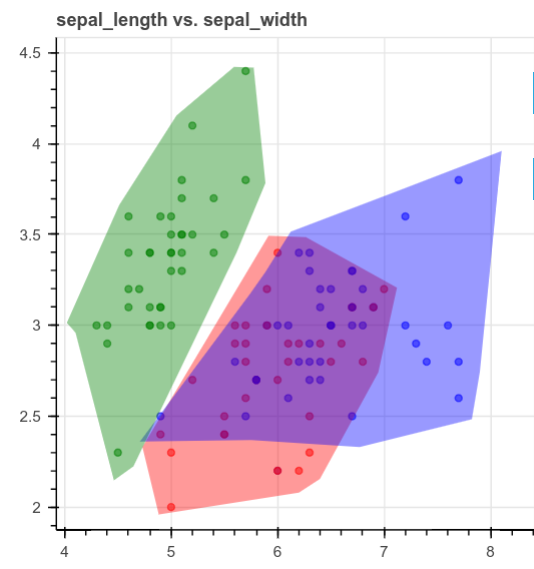
但是,可能很难将图形编写为规则并将其放入函数中,human-learn的交互式绘图将派上用场。
from hulearn.experimental.interactive import InteractiveCharts charts = InteractiveCharts(train, labels='target') charts.add_chart(x='sepal_length', y='sepal_width')
– 动图01
绘制方法:使用双击开始绘制多边形。然后单击以创建多边形的边。再次双击可停止绘制当前多边形。
我们对其他列也做同样的事情:
charts.add_chart(x='petal_length', y='petal_width')
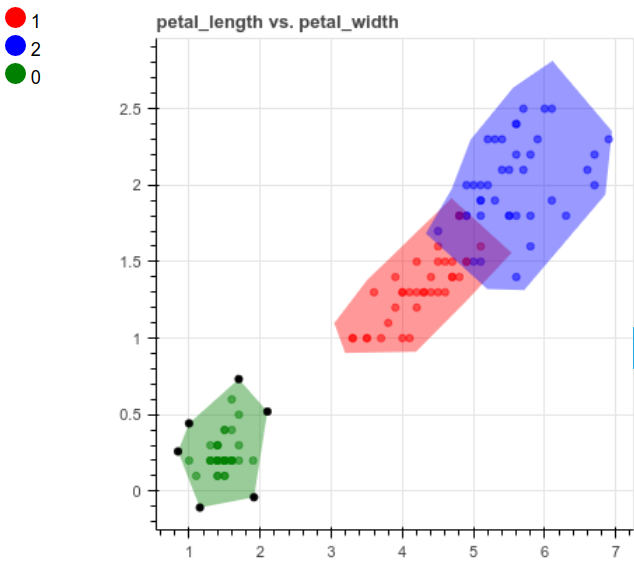
创建模型并进行预测
一旦完成对数据集的绘制,就可以使用以下方法创建模型:
from hulearn.classification import InteractiveClassifier model = InteractiveClassifier(json_desc=charts.data()) preds = model.fit(X_train, y_train).predict_proba(X_train) print(preds.shape) # Output: (150, 3)
cool! 我们将工程图输入InteractiveClassifier类,使用类似的方法来拟合sklearn的模型,例如fit和predict_proba。
让我们来看看pred的前5行:
print('Classes:', model.classes_)
print('Predictions:\n', preds[:5, :])
"""Output
Classes: [1, 2, 0]
Predictions:
[[5.71326574e-01 4.28530630e-01 1.42795945e-04]
[2.00079952e-01 7.99720168e-01 1.99880072e-04]
[2.00079952e-01 7.99720168e-01 1.99880072e-04]
[2.49812641e-04 2.49812641e-04 9.99500375e-01]
[4.99916708e-01 4.99916708e-01 1.66583375e-04]]
"""
需要说明的是,predict_proba给出了样本具有特定标签的概率。 例如,[5.71326574e-01 4.28530630e-01 1.42795945e-04]的第一个预测表示样本具有标签1的可能性为57.13%,样本具有标签2的可能性为42.85%,而样本为标签2的可能性为0.014% 该样本的标签为0。
预测新数据
# Get the first sample of X_test
new_sample = new_sample = X_test.iloc[:1]
# Predict
pred = model.predict(new_sample)
real = y_test[:1]
print("The prediction is", pred[0])
print("The real label is", real.iloc[0])
解释结果
为了了解模型如何根据该预测进行预测,让我们可视化新样本。
def plot_prediction(prediction: int, columns: list):
"""Plot new sample
Parameters
----------
prediction : int
prediction of the new sample
columns : list
Features to create a scatter plot
"""
index = prediction_to_index[prediction]
col1, col2 = columns
plt.figure(figsize=(12, 3))
plt.scatter(X_train[col1], X_train[col2], c=preds[:, index])
plt.plot(new_sample[col1], new_sample[col2], 'ro', c='red', label='new_sample')
plt.xlabel(col1)
plt.ylabel(col2)
plt.title(f"Label {model.classes_[index]}")
plt.colorbar()
plt.legend()
使用上面的函数在petal_length和petal_width绘图上绘制一个新样本,该样本的点被标记为0的概率着色。
plot_prediction(0, columns=['petal_length', 'petal_width'])

其他列也是如此,我们可以看到红点位于具有许多黄点的区域中! 这就解释了为什么模型预测新样本的标签为0。这很酷,不是吗?
预测和评估测试数据
现在,让我们使用该模型来预测测试数据中的所有样本并评估其性能。 开始使用混淆矩阵进行评估:
from sklearn.metrics import confusion_matrix, f1_score predictions = model.predict(X_test) confusion_matrix(y_test, predictions, labels=[0,1,2])
array([[13, 0, 0],
[ 0, 15, 1],
[ 0, 0, 9]])
我们还可以使用F1分数评估结果:
f1_score(y_test, predictions, average='micro')
结论
刚刚我们学习了如何通过绘制数据集来生成规则来标记数据。 这并不是说你应该完全消除机器学习模型,而是在处理数据时加入某种人工监督。
以上就是python人工智能human learn绘图可创建机器学习模型的详细内容,更多关于human learn绘图创建机器学习模型的资料请关注我们其它相关文章!
相关推荐
-

pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
python解释模型库Shap实现机器学习模型输出可视化
目录 安装所需的库 导入所需库 创建模型 创建可视化 1.Bar Plot 2.队列图 3.热图 4.瀑布图 5.力图 6.决策图 解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的.解释是必需的,这样我们可以选择最佳的模型,同时也使其健壮. 我们开始吧- 安装所需的库 使用pip安装Shap开始.下面给出的命令可以做到这一点. pip install shap 导入所需库 在这一步中,我们将导入加载数据.创建模型和创建该模型的可视化所需的库. df = pd
-
python机器学习Github已达8.9Kstars模型解释器LIME
目录 LIME 代 码 对单个样本进行预测解释 适用问题 简单的模型例如线性回归,LR等模型非常易于解释,但在实际应用中的效果却远远低于复杂的梯度提升树模型以及神经网络等模型. 现在大部分互联网公司的建模都是基于梯度提升树或者神经网络模型等复杂模型,遗憾的是,这些模型虽然效果好,但是我们却较难对其进行很好地解释,这也是目前一直困扰着大家的一个重要问题,现在大家也越来越加关注模型的解释性. 本文介绍一种解释机器学习模型输出的方法LIME.它可以认为是SHARP的升级版,Github链接:https
-
python机器学习创建基于规则聊天机器人过程示例详解
目录 聊天机器人 基于规则的聊天机器人 创建语料库 创建一个聊天机器人 总结 还记得这个价值一个亿的AI核心代码? while True: AI = input('我:') print(AI.replace("吗", " ").replace('?','!').replace('?','!')) 以上这段代码就是我们今天的主题,基于规则的聊天机器人 聊天机器人 聊天机器人本身是一种机器或软件,它通过文本或句子模仿人类交互. 简而言之,可以使用类似于与人类对话的软件进
-
python人工智能human learn绘图可创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
python人工智能human learn绘图创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
Python人工智能构建简单聊天机器人示例详解
目录 引言 什么是聊天机器人? 准备工作 创建聊天机器人 导入必要的库 定义响应集合 创建聊天机器人 运行聊天机器人 完整代码 结论 展望 引言 人工智能是计算机科学中一个非常热门的领域,近年来得到了越来越多的关注.它通过模拟人类思考过程和智能行为来实现对复杂任务的自主处理和学习,已经被广泛应用于许多领域,包括语音识别.自然语言处理.机器人技术.图像识别和推荐系统等. 本文将介绍如何使用Python构建一个简单的聊天机器人,以展示人工智能的基本原理和应用.我们将使用Python语言和自然语言处理
-
Python使用matplotlib简单绘图示例
本文实例讲述了Python使用matplotlib简单绘图.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #! python2 """ Created on Mon Apr 24 12:48:40 2017 @author: x-power """ import matplotlib.pyplot as plt #首先载入 matplotlib的绘图模块pyplot,并且重命名为plt. import numpy
-
Python利用matplotlib.pyplot绘图时如何设置坐标轴刻度
前言 matplotlib.pyplot是一些命令行风格函数的集合,使matplotlib以类似于MATLAB的方式工作.每个pyplot函数对一幅图片(figure)做一些改动:比如创建新图片,在图片创建一个新的作图区域(plotting area),在一个作图区域内画直线,给图添加标签(label)等.matplotlib.pyplot是有状态的,亦即它会保存当前图片和作图区域的状态,新的作图函数会作用在当前图片的状态基础之上. 在开始本文之前,不熟悉的朋友可以先看看这篇文章:Python
-
Python人工智能之路 jieba gensim 最好别分家之最简单的相似度实现
简单的问答已经实现了,那么问题也跟着出现了,我不能确定问题一定是"你叫什么名字",也有可能是"你是谁","你叫啥"之类的,这就引出了人工智能中的另一项技术: 自然语言处理(NLP) : 大概意思就是 让计算机明白一句话要表达的意思,NLP就相当于计算机在思考你说的话,让计算机知道"你是谁","你叫啥","你叫什么名字"是一个意思 这就要做 : 语义相似度 接下来我们用Python大法来实
-
Python人工智能之路 之PyAudio 实现录音 自动化交互实现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库 关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的 首先要先 pip 一个 PyAudio pip install pyaudio 一.PyAudio 实现麦克风录音 然后建立一个py文件,复制如下代码 import pyaudio import wave CHUNK = 1024 FORMAT = py
-
Python人工智能之波士顿房价数据分析
目录 1.数据概览分析 1.1 数据概览 1.2 数据分析 2. 项目总体思路 2.1 数据读取 2.2 模型预处理 (1)数据离群点处理 (2)数据归一化处理 2.3. 特征工程 2.4. 模型选择 2.5. 模型评价 2.6. 模型调参 3. 项目总结 [人工智能项目]机器学习热门项目-波士顿房价 1.数据概览分析 1.1 数据概览 本次提供: train.csv,训练集: test.csv,测试集: submission.csv 真实房价文件: 训练集404行数据,14列,每行数据表示房屋