分享MySQL 主从延迟与读写分离的七种解决方案
目录
- 一、强制走主库
- 二、从库延迟查询
- 三、判断主从是否延迟?决定选主库还是从库
- 1.针对这个问题,有什么解决方案?
- 四、从库节点判断主库位点
- 五、比较 GTID
- 六、引入缓存中间件
- 七、数据分片
- 1.转换到数据库方面
前言:
我们都知道互联网数据有个特性,大部分场景都是 读多写少,比如:微博、微信、淘宝电商,按照 二八原则,读流量占比甚至能达到 90%。
结合这个特性,我们对底层的数据库架构也会做相应调整。采用 读写分离。

处理过程:
- 客户端会集成 SDK,每次执行 SQL 时,会判断是 写 或 读 操作。
- 如果是 写 SQL,请求会发到 主库。
- 主数据库执行SQL,事务提交后,会生成 binlog ,并同步给 从库。
- 从库 通过 SQL 线程回放 binlog ,并在从库表中生成相应数据。
- 如果是 读 SQL,请求会通过 负载均衡 策略,挑选一个 从库 处理用户请求。
看似非常合理,细想却不是那么回事。
主库 与 从库 是采用异步复制数据,如果这两者之间数据还没有同步怎么办?
主库刚写完数据,从库还没来得及拉取最新数据,读 请求就来了,给用户的感觉,数据丢了?
针对这个问题,今天,我们就来探讨下有什么解决方案?
一、强制走主库
针对不用的业务诉求,区别性对待。
场景一:
如果是对数据的 实时性 要求不是很高,比如:大V有千万粉丝,发布一条微博,粉丝晚几秒钟收到这条信息,并不会有特别大的影响。这时,可以走 从库。
场景二:
如果对数据的 实时性 要求非常高,比如金融类业务。我们可以在客户端代码标记下,让查询强制走主库。
二、从库延迟查询
由于主从库之间数据同步需要一定的时间间隔,那么有一种策略是延迟从从库查询数据。
比如:
select sleep(1) select * from order where order_id=11111;
在正式的业务查询时,先执行一个sleep 语句,给从库预留一定的数据同步缓冲期。
因为是采用一刀切,当面对高并发业务场景时,性能会下降的非常厉害,一般不推荐这个方案。
三、判断主从是否延迟?决定选主库还是从库
之前写过一篇文章 《京东一面:MySQL 主备延迟有哪些坑?主备切换策略 》。
有讲过 什么是主备延迟?、主备延迟的常见原因?
方案一:
在从库 执行 命令 show slave status。
查看seconds_behind_master 的值,单位为秒,如果为 0,表示主备库之间无延迟。
方案二:
比较主从库的文件点位。
还是执行show slave status,响应结果里有截个关键参数。
- Master_Log_File 读到的主库最新文件。
- Read_Master_Log_Pos 读到的主库最新文件的坐标位置。
- Relay_Master_Log_File 从库执行到的最新文件。
- Exec_Master_Log_Pos 从库执行到的最新文件的坐标位置。
两两比较,上面的参数是否相等。
方案三:
比较 GTID 集合。
- Auto_Position=1 主从之间使用 GTID 协议。
- Retrieved_Gtid_Set 从库收到的所有binlog日志的 GTID 集合。
- Executed_Gtid_Set 从库已经执行完成的 GTID 集合。
比较 Retrieved_Gtid_Set 和 Executed_Gtid_Set 的值是否相等。
在执行业务SQL操作时,先判断从库是否已经同步最新数据。从而决定是操作主库,还是操作从库。
缺点:
无论采用上面哪一种方案,如果主库的写操作频繁不断,那么从库的值永远跟不上主库的值,那么读流量永远是打在了主库上。
1.针对这个问题,有什么解决方案?
这个问题跟 MQ消息队列 既要求高吞吐量又要保证顺序是一样的,从全局来看确实无解,但是缩小范围就容易多了,我们可以保证一个分区内的消息有序。
回到 主从库 之间的数据同步问题,从库查询哪条记录,我们只要保证之前对应的写binglog已经同步完数据即可,可以不用管主从库的所有的事务binlog 是否同步。
问题是不是一下简单多了。
四、从库节点判断主库位点
在从库执行下面命令,返回是一个正整数 M,表示从库从参数节点开始执行了多少个事务。
select master_pos_wait(file, pos[, timeout]);
- file 和 pos 表示主库上的文件名和位置。
- timeout 可选, 表示这个函数最多等待 N 秒。
缺点:
master_pos_wait 返回结果无法与具体操作的数据行做关联,所以每次接收读请求时,从库还是无法确认是否已经同步数据,方案实用性不高。
五、比较 GTID
执行下面查询命令:
- 阻塞等待,直到从库执行的事务中包含
gtid_set,返回 0。 - 超时,返回 1。
select wait_for_executed_gtid_set(gtid_set, 1);
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端。具体操作,将参数session_track_gtids 设置为OWN_GTID,调用 API 接口mysql_session_track_get_first 返回结果解析出 GTID。
处理流程:
- 发起 写 SQL 操作,在主库成功执行后,返回这个事务的 GTID。
- 发起 读 SQL 操作时,先在从库执行
select wait_for_executed_gtid_set (gtid_set, 1)。 - 如果返回 0,表示已经从库已经同步了数据,可以在从库执行 查询 操作。
- 否则,在主库执行 查询 操作。
缺点:
跟上面的 master_pos_wait 类似,如果 写操作 与 读操作 没有上下文关联,那么 GTID 无法传递 。方案实用性不高。
六、引入缓存中间件
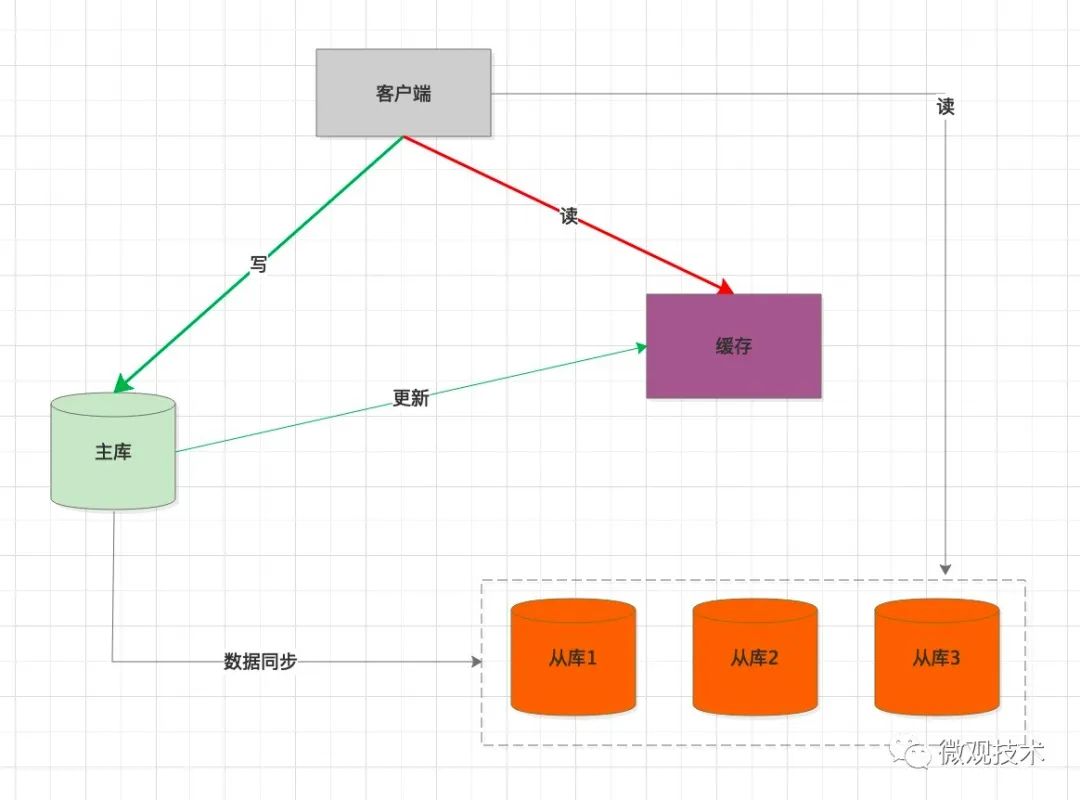
高并发系统,缓存作为性能优化利器,应用广泛。我们可以考虑引入缓存作为缓冲介质。
处理过程:
- 客户端 写 SQL ,操作主库。
- 同步将缓存中的数据删除。
- 当客户端读数据时,优先从缓存加载。
- 如果 缓存中没有,会强制查询主库预热数据。
缺点:
K-V 存储,适用一些简单的查询条件场景。如果复杂的查询,还是要查询从库。
七、数据分片

参考 Redis Cluster 模式, 集群网络拓扑通常是 3主 3从,主节点既负责写,也负责读。
通过水平分片,支持数据的横向扩展。由于每个节点都是独立的服务器,可以提高整体集群的吞吐量。
1.转换到数据库方面
常见的解决方式,是分库分表,每次读写都是操作主库的一个分表,从库只用来做数据备份。当主库发生故障时,主从切换,保证集群的高可用性。
到此这篇关于分享MySQL 主从延迟与读写分离的七种解决方案的文章就介绍到这了,更多相关MySQL主从延迟读写分离解决方案内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL主从复制延迟原因以及解决方案
来源:公众号「神谕的暗影长廊」 在异步或半同步的复制结构中,从库出现延迟是一件十分正常的事. 虽出现延迟正常,但是否需要关注,则一般是由业务来评估. 如:从库上有需要较高一致性的读业务,并且要求延迟小于某个值,那么则需要关注. 简单概述一下复制逻辑: 1.主库将对数据库实例的变更记录到binlog中. 2.主库会有binlog dump线程实时监测binlog的变更并将这些新的events推给从库(Master has sent all binlog to slave; waiting for
-
MYSQL主从不同步延迟原理分析及解决方案
1. MySQL数据库主从同步延迟原理.要说延时原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率很比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施.DML和DDL的IO操作是随即的,不是顺序的,成本高很多,还可能可slave上的其他查询产生lock争
-
Mysql读写分离过期常用解决方案
mysql读写分离的坑 读写分离的主要目标是分摊主库的压力,由客户端选择后端数据库进行查询.还有种架构就是在MYSQL和客户端之间有一个中间代理层proxy,客户端之连接proxy,由proxy根据请求类型和上下文决定请求的分发路由. 客户端直连方案:因为少了一层proxy转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便.但是这种方案,由于要了解后端部署细节,所以在出现主备切换.库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息. 带proxy架构:对客户端比较友好
-

分享MySQL 主从延迟与读写分离的七种解决方案
目录 一.强制走主库 二.从库延迟查询 三.判断主从是否延迟?决定选主库还是从库 1.针对这个问题,有什么解决方案? 四.从库节点判断主库位点 五.比较 GTID 六.引入缓存中间件 七.数据分片 1.转换到数据库方面 前言: 我们都知道互联网数据有个特性,大部分场景都是 读多写少,比如:微博.微信.淘宝电商,按照 二八原则,读流量占比甚至能达到 90%. 结合这个特性,我们对底层的数据库架构也会做相应调整.采用 读写分离. 处理过程: 客户端会集成 SDK,每次执行 SQL 时,会判断是 写
-
springboot结合mysql主从来实现读写分离的方法示例
1.实现的功能 基于springboot框架,application.yml配置多个数据源,使用AOP以及AbstractRootingDataSource.ThreadLocal来实现多数据源切换,以实现读写分离.mysql的主从数据库需要进行设置数据之间的同步. 2.代码实现 application.properties中的配置 spring.datasource.druid.master.driver-class-name=com.mysql.jdbc.Driver spring.data
-
关于MySQL与Golan分布式事务经典的七种解决方案
目录 1.基础理论 1.1 事务 1.2 分布式事务 2.分布式事务的解决方案 2.1 两阶段提交/XA 2.2 SAGA 2.3 TCC 2.4 本地消息表 2.5 事务消息 2.6 最大努力通知 2.7 AT事务模式 3.异常处理 3.1 异常情况 3.2 子事务屏障 3.3 子事务屏障原理 3.4 子事务屏障小结 4.分布式事务实践 4.1 一个SAGA事务 4.2 处理网络异常 4.3 处理回滚 5.总结 前言: 随着业务的快速发展.业务复杂度越来越高,几乎每个公司的系统都会从单体走向分
-
MySQL主从同步、读写分离配置步骤
现在使用的两台服务器已经安装了MySQL,全是rpm包装的,能正常使用. 为了避免不必要的麻烦,主从服务器MySQL版本尽量保持一致; 环境:192.168.0.1 (Master) 192.168.0.2 (Slave) MySQL Version:Ver 14.14 Distrib 5.1.48, for pc-linux-gnu (i686) using readline 5.1 1.登录Master服务器,修改my.cnf,添加如下内容: server-id = 1 //数据库ID号,
-
利用MySQL主从配置实现读写分离减轻数据库压力
大型网站为了软解大量的并发访问,除了在网站实现分布式负载均衡,远远不够.到了数据业务层.数据访问层,如果还是传统的数据结构,或者只是单单靠一台服务器扛,如此多的数据库连接操作,数据库必然会崩溃,数据丢失的话,后果更是 不堪设想.这时候,我们会考虑如何减少数据库的联接,一方面采用优秀的代码框架,进行代码的优化,采用优秀的数据缓存技术如:memcached,如果资金丰厚的话,必然会想到假设服务器群,来分担主数据库的压力.Ok切入今天文章主题,利用MySQL主从配置,实现读写分离,减轻数据库压力.这种
-
Yii实现MySQL多数据库和读写分离实例分析
本文实例分析了Yii实现MySQL多数据库和读写分离的方法.分享给大家供大家参考.具体分析如下: Yii Framework是一个基于组件.用于开发大型 Web 应用的高性能 PHP 框架.Yii提供了今日Web 2.0应用开发所需要的几乎一切功能,也是最强大的框架之一,下文我们来介绍Yii实现MySQL多库和读写分离的方法 前段时间为SNS产品做了架构设计,在程序框架方面做了不少相关的压力测试,最终选定了YiiFramework,至于为什么没选用公司内部的 PHP框架,其实理由很充分,公司的框
-
MySQL数据库主从复制与读写分离
目录 一.主从复制 主从复制三线程 主从复制的过程: 主从复制的策略: 主从复制高延迟 二.读写分离 读写分离概念 读写分离原因与场景 总结 一.主从复制 主从复制:在实际的生产中,为了解决Mysql的单点故障以及提高MySQL的整体服务性能,一般都会采用主从复制.即:对数据库中的数据.语句做备份. 主从复制三线程 Mysql的主从复制中主要有三个线程:master(binlog dump thread).slave(I/O thread .SQL thread),M
-
MySQL主从延迟问题解决
今天我们就来看看为什么会产生主从延迟以及主从延迟如何处理等相关问题. 坐好了,准备发车! 主从常见架构 随着日益增长的访问量,单台数据库的应接能力已经捉襟见肘.因此采用主库写数据,从库读数据这种将读写分离开的主从架构便随之衍生了出来. 在生产环境中,常见的主从架构有很多种,在这里给大家介绍几种比较常见的架构模式. 主从复制原理 了解了主从的基本架构及相关配置后,下面就要进入正题了. 对于主从来说,通常的操作是主库用来写入数据,从库用来读取数据.这样的好处是通过将读写压力分散开,避免了所有的请求都
-
详解MySQL的主从复制、读写分离、备份恢复
一.MySQL主从复制 1.简介 我们为什么要用主从复制? 主从复制目的: 可以做数据库的实时备份,保证数据的完整性: 可做读写分离,主服务器只管写,从服务器只管读,这样可以提升整体性能. 原理图: 从上图可以看出,同步是靠log文件同步读写完成的. 2.更改配置文件 两天机器都操作,确保 server-id 要不同,通常主ID要小于从ID.一定注意. # 3306和3307分别代表2台机器 # 打开log-bin,并使server-id不一样 #vim /data/3306/my.cnf lo
-
MySQL的使用中实现读写分离的教程
mysql-proxy实现读写分离 MySQL Proxy是一个处于你的client端和MySQL server端之间的简单程序,它可以监测.分析或改变它们的通信.它使用灵活,没有限制,常见的用途包括:负载平衡,故障.查询分析,查询过滤和修改等等. MySQL Proxy就是这么一个中间层代理,简单的说,MySQL Proxy就是一个连接池,负责将前台应用的连接请求转发给后台的数据库,并且通过使用lua脚本,可以实现复杂的连接控制和过滤,从而实现读写分离和负载平衡.对于应用来说,MySQL Pr