Django中celery的使用项目实例
目录
- 1、django应用Celery
- 2 、项目应用
- 1.异步任务redis
- 2.定时任务
- 3.任务绑定
- 4.任务钩子
- 5.任务编排
- 6、celery管理和监控
- 总结
1、django应用Celery
django框架请求/响应的过程是同步的,框架本身无法实现异步响应。
但是我们在项目过程中会经常会遇到一些耗时的任务, 比如:发送邮件、发送短信、大数据统计等等,这些操作耗时长,同步执行对用户体验非常不友好,那么在这种情况下就需要实现异步执行。
异步执行前端一般使用ajax,后端使用Celery。
2 、项目应用
django项目应用celery,主要有两种任务方式,一是异步任务(发布者任务),一般是web请求,二是定时任务。
celery组成
Celery是由Python开发、简单、灵活、可靠的分布式任务队列,是一个处理异步任务的框架,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务。Celery侧重于实时操作,但对调度支持也很好,其每天可以处理数以百万计的任务。特点:
简单:熟悉celery的工作流程后,配置使用简单
高可用:当任务执行失败或执行过程中发生连接中断,celery会自动尝试重新执行任务
快速:一个单进程的celery每分钟可处理上百万个任务
灵活:几乎celery的各个组件都可以被扩展及自定制
Celery由三部分构成:
消息中间件(Broker):官方提供了很多备选方案,支持RabbitMQ、Redis、Amazon SQS、MongoDB、Memcached 等,官方推荐RabbitMQ
任务执行单元(Worker):任务执行单元,负责从消息队列中取出任务执行,它可以启动一个或者多个,也可以启动在不同的机器节点,这就是其实现分布式的核心
结果存储(Backend):官方提供了诸多的存储方式支持:RabbitMQ、 Redis、Memcached,SQLAlchemy, Django ORM、Apache Cassandra、Elasticsearch等
架构如下:
工作原理:
任务模块Task包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往消息队列,而定时任务由Celery Beat进程周期性地将任务发往消息队列;
任务执行单元Worker实时监视消息队列获取队列中的任务执行;
Woker执行完任务后将结果保存在Backend中;

本文使用的是redis数据库作为消息中间件和结果存储数据库
1.异步任务redis
1.安装库
pip install celery pip install redis
2.celery.py
在主项目目录下,新建 celery.py 文件:
import os
import django
from celery import Celery
from django.conf import settings
# 设置系统环境变量,安装django,必须设置,否则在启动celery时会报错
# celery_study 是当前项目名
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_study.settings')
django.setup()
celery_app = Celery('celery_study')
celery_app.config_from_object('django.conf:settings')
celery_app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)

注意:是和settings.py文件同目录,一定不能建立在项目根目录,不然会引起 celery 这个模块名的命名冲突
同时,在主项目的init.py中,添加如下代码:
from .celery import celery_app __all__ = ['celery_app']

3.settings.py
在配置文件中配置对应的redis配置:
# Broker配置,使用Redis作为消息中间件 BROKER_URL = 'redis://127.0.0.1:6379/0' # BACKEND配置,这里使用redis CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0' # 结果序列化方案 CELERY_RESULT_SERIALIZER = 'json' # 任务结果过期时间,秒 CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 时区配置 CELERY_TIMEZONE='Asia/Shanghai' # 指定导入的任务模块,可以指定多个 #CELERY_IMPORTS = ( # 'other_dir.tasks', #)

注意:所有配置的官方文档:Configuration and defaults — Celery 5.2.0b3 documentation
4.tasks.py
在子应用下建立各自对应的任务文件tasks.py(必须是tasks.py这个名字,不允许修改)
from celery import shared_task
@shared_task
def add(x, y):
return x + y
@shared_task
def mul(x, y):
return x * y
@shared_task
def xsum(numbers):
return sum(numbers)

5.调用任务
from .tasks import *
# Create your views here.
def task_add_view(request):
add.delay(100,200)
return HttpResponse(f'调用函数结果')


6.启动celery
pip install eventlet
celery -A celery_study worker -l debug -P eventlet
注意 :celery_study是项目名
使用redis时,有可能会出现如下类似的异常
AttributeError: 'str' object has no attribute 'items'
这是由于版本差异,需要卸载已经安装的python环境中的 redis 库,重新指定安装特定版本(celery4.x以下适用 redis2.10.6, celery4.3以上使用redis3.2.0以上):
xxxxxxxxxx pip install redis==2.10.6
7.获取任务结果
在 views.py 中,通过 AsyncResult.get() 获取结果
from celery import result
def get_result_by_taskid(request):
task_id = request.GET.get('task_id')
# 异步执行
ar = result.AsyncResult(task_id)
if ar.ready():
return JsonResponse({'status': ar.state, 'result': ar.get()})
else:
return JsonResponse({'status': ar.state, 'result': ''})

AsyncResult类的常用的属性和方法:
- state: 返回任务状态,等同status;
- task_id: 返回任务id;
- result: 返回任务结果,同get()方法;
- ready(): 判断任务是否执行以及有结果,有结果为True,否则False;
- info(): 获取任务信息,默认为结果;
- wait(t): 等待t秒后获取结果,若任务执行完毕,则不等待直接获取结果,若任务在执行中,则wait期间一直阻塞,直到超时报错;
- successful(): 判断任务是否成功,成功为True,否则为False;
2.定时任务
在第一步的异步任务的基础上,进行部分修改即可
1.settings.py
from celery.schedules import crontab
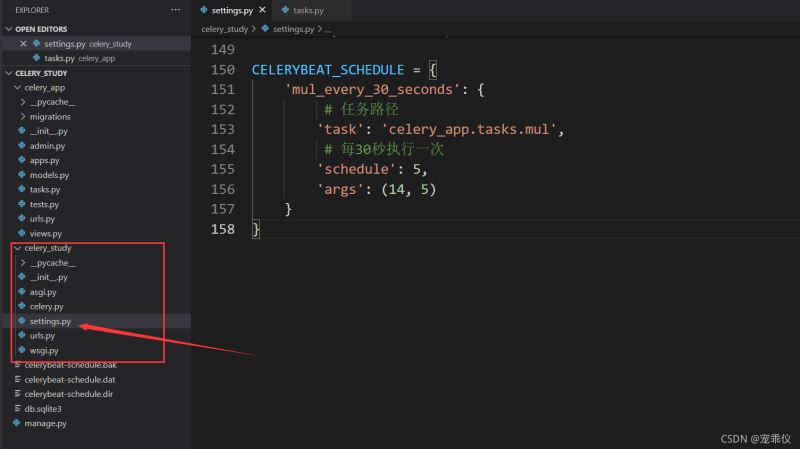
CELERYBEAT_SCHEDULE = {
'mul_every_30_seconds': {
# 任务路径
'task': 'celery_app.tasks.mul',
# 每30秒执行一次
'schedule': 5,
'args': (14, 5)
}
}
说明(更多内容见文档:Periodic Tasks — Celery 5.2.0b3 documentation):
- task:任务函数
- schedule:执行频率,可以是整型(秒数),也可以是timedelta对象,也可以是crontab对象,也可以是自定义类(继承celery.schedules.schedule)
- args:位置参数,列表或元组
- kwargs:关键字参数,字典
- options:可选参数,字典,任何 apply_async() 支持的参数
- relative:默认是False,取相对于beat的开始时间;设置为True,则取设置的timedelta时间
在task.py中设置了日志
from celery import shared_task
import logging
logger = logging.getLogger(__name__))
@shared_task
def mul(x, y):
logger.info('___mul__'*10)
return x * y
2.启动celery
(两个cmd)分别启动worker和beat
celery -A worker celery_study -l debug -P eventlet celery beat -A celery_study -l debug
3.任务绑定
Celery可通过task绑定到实例获取到task的上下文,这样我们可以在task运行时候获取到task的状态,记录相关日志等
方法:
- 在装饰器中加入参数 bind=True
- 在task函数中的第一个参数设置为self
在task.py 里面写
from celery import shared_task
import logging
logger = logging.getLogger(__name__)
# 任务绑定
@shared_task(bind=True)
def add(self,x, y):
logger.info('add__-----'*10)
logger.info('name:',self.name)
logger.info('dir(self)',dir(self))
return x + y
其中:self对象是celery.app.task.Task的实例,可以用于实现重试等多种功能
from celery import shared_task
import logging
logger = logging.getLogger(__name__)
# 任务绑定
@shared_task(bind=True)
def add(self,x, y):
try:
logger.info('add__-----'*10)
logger.info('name:',self.name)
logger.info('dir(self)',dir(self))
raise Exception
except Exception as e:
# 出错每4秒尝试一次,总共尝试4次
self.retry(exc=e, countdown=4, max_retries=4)
return x + y
启动celery
celery -A worker celery_study -l debug -P eventlet
4.任务钩子
Celery在执行任务时,提供了钩子方法用于在任务执行完成时候进行对应的操作,在Task源码中提供了很多状态钩子函数如:on_success(成功后执行)、on_failure(失败时候执行)、on_retry(任务重试时候执行)、after_return(任务返回时候执行)
方法:通过继承Task类,重写对应方法即可,
from celery import Task
class MyHookTask(Task):
def on_success(self, retval, task_id, args, kwargs):
logger.info(f'task id:{task_id} , arg:{args} , successful !')
def on_failure(self, exc, task_id, args, kwargs, einfo):
logger.info(f'task id:{task_id} , arg:{args} , failed ! erros: {exc}')
def on_retry(self, exc, task_id, args, kwargs, einfo):
logger.info(f'task id:{task_id} , arg:{args} , retry ! erros: {exc}')
# 在对应的task函数的装饰器中,通过 base=MyHookTask 指定
@shared_task(base=MyHookTask, bind=True)
def add(self,x, y):
logger.info('add__-----'*10)
logger.info('name:',self.name)
logger.info('dir(self)',dir(self))
return x + y
启动celery
celery -A worker celery_study -l debug -P eventlet
5.任务编排
在很多情况下,一个任务需要由多个子任务或者一个任务需要很多步骤才能完成,Celery也能实现这样的任务,完成这类型的任务通过以下模块完成:
- group: 并行调度任务
- chain: 链式任务调度
- chord: 类似group,但分header和body2个部分,header可以是一个group任务,执行完成后调用body的任务
- map: 映射调度,通过输入多个入参来多次调度同一个任务
- starmap: 类似map,入参类似*args
- chunks: 将任务按照一定数量进行分组
文档:Next Steps — Celery 5.2.0b3 documentation
1.group
urls.py:
path('primitive/', views.test_primitive),
views.py:
from .tasks import *
from celery import group
def test_primitive(request):
# 创建10个并列的任务
lazy_group = group(add.s(i, i) for i in range(10))
promise = lazy_group()
result = promise.get()
return JsonResponse({'function': 'test_primitive', 'result': result})
说明:
通过task函数的 s 方法传入参数,启动任务
上面这种方法需要进行等待,如果依然想实现异步的方式,那么就必须在tasks.py中新建一个task方法,调用group,示例如下:
tasks.py:
@shared_task
def group_task(num):
return group(add.s(i, i) for i in range(num))().get()
urls.py:
path('first_group/', views.first_group),
views.py:
def first_group(request):
ar = tasks.group_task.delay(10)
return HttpResponse('返回first_group任务,task_id:' + ar.task_id)
2.chain
默认上一个任务的结果作为下一个任务的第一个参数
def test_primitive(request):
# 等同调用 mul(add(add(2, 2), 5), 8)
promise = chain(tasks.add.s(2, 2), tasks.add.s(5), tasks.mul.s(8))()
# 72
result = promise.get()
return JsonResponse({'function': 'test_primitive', 'result': result})
3.chord
任务分割,分为header和body两部分,hearder任务执行完在执行body,其中hearder返回结果作为参数传递给body
def test_primitive(request):
# header: [3, 12]
# body: xsum([3, 12])
promise = chord(header=[tasks.add.s(1,2),tasks.mul.s(3,4)],body=tasks.xsum.s())()
result = promise.get()
return JsonResponse({'function': 'test_primitive', 'result': result})
6、celery管理和监控
celery通过flower组件实现管理和监控功能 ,flower组件不仅仅提供监控功能,还提供HTTP API可实现对woker和task的管理
文档:Flower - Celery monitoring tool — Flower 1.0.1 documentation
安装flower
pip install flower
启动flower
flower -A celery_study --port=5555
说明:
- -A:项目名
- --port: 端口号
访问
在浏览器输入:http://127.0.0.1:5555
通过api操作
curl http://127.0.0.1:5555/api/workers
总结
到此这篇关于Django中celery使用项目的文章就介绍到这了,更多相关Django中celery使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Django使用Celery异步任务队列的使用
1 Celery简介 Celery是异步任务队列,可以独立于主进程运行,在主进程退出后,也不影响队列中的任务执行. 任务执行异常退出,重新启动后,会继续执行队列中的其他任务,同时可以缓存停止期间接收的工作任务,这个功能依赖于消息队列(MQ.Redis). 1.1 Celery原理 Celery的 架构 由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成. 消息中间件:Celery本身不提供消息服务,但
-
Django中使用Celery的方法步骤
(一).概述 Celery是一个简单.灵活和可靠的基于多任务的分布式系统,为运营提供用于维护此系统的工具.专注于实时处理的任务队列,同时也支持任务的调度.执行单元为任务(task),利用多线程这些任务可以被并发的在单个或多个职程(worker)上运行. Celery通过消息机制通信,通常通过中间人(broker)来分配和调节客户端与职程服务器(worker)之间的通信.客户端发送一条消息,中间人把消息分配给一个职程,最后由职程来负责执行此任务. Celery可以有多个职程和中间人,这样提高了高可
-
Django中使用Celery的教程详解
Django教程 Python下有许多款不同的 Web 框架.Django是重量级选手中最有代表性的一位.许多成功的网站和APP都基于Django. Django是一个开放源代码的Web应用框架,由Python写成. Django遵守BSD版权,初次发布于2005年7月, 并于2008年9月发布了第一个正式版本1.0 . Django采用了MVC的软件设计模式,即模型M,视图V和控制器C. 一.前言 Celery是一个基于python开发的分布式任务队列,如果不了解请阅读笔者上一篇博文Celer
-

Django中celery的使用项目实例
目录 1.django应用Celery 2 .项目应用 1.异步任务redis 2.定时任务 3.任务绑定 4.任务钩子 5.任务编排 6.celery管理和监控 总结 1.django应用Celery django框架请求/响应的过程是同步的,框架本身无法实现异步响应. 但是我们在项目过程中会经常会遇到一些耗时的任务, 比如:发送邮件.发送短信.大数据统计等等,这些操作耗时长,同步执行对用户体验非常不友好,那么在这种情况下就需要实现异步执行. 异步执行前端一般使用ajax,后端使用Celery
-
Django中celery执行任务结果的保存方法
如下所示: pip3 install django-celery-results INSTALLED_APPS = ( ..., 'django_celery_results',) # 注意这个是下划线'_' python3 manage.py migrate django_celery_results CELERY_RESULT_BACKEND = 'django-db' #在settings.py文件中配置 注意异步任务views.py中调用时,想要记录结果必须是"任务函数.delay(*a
-
异步任务队列Celery在Django中的使用方法
前段时间在Django Web平台开发中,碰到一些请求执行的任务时间较长(几分钟),为了加快用户的响应时间,因此决定采用异步任务的方式在后台执行这些任务.在同事的指引下接触了Celery这个异步任务队列框架,鉴于网上关于Celery和Django结合的文档较少,大部分也只是粗粗介绍了大概的流程,在实践过程中还是遇到了不少坑,希望记录下来帮助有需要的朋友. 一.Django中的异步请求 Django Web中从一个http请求发起,到获得响应返回html页面的流程大致如下:http请求发起 --
-
Django中使用celery完成异步任务的示例代码
本文主要介绍如何在django中用celery完成异步任务,web项目中为了提高用户体验可以对一些耗时操作放到异步队列中去执行,例如激活邮件,后台计算操作等等 当前项目环境为: django==1.11.8 celery==3.1.25 redis==2.10.6 pip==9.0.1 python3==3.5.2 django-celery==3.1.17 一,创建Django项目及celery配置 1,创建Django项目 1>打开终端输入:django-admin startproject
-
django中使用Celery 布式任务队列过程详解
本文记录django中如何使用celery完成异步任务. Celery 是一个简单.灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具. 它是一个专注于实时处理的任务队列,同时也支持任务调度. 官方网站 中文文档 示例一:用户发起request,并等待response返回.在本些views中,可能需要执行一段耗时的程序,那么用户就会等待很长时间,造成不好的用户体验 示例二:网站每小时需要同步一次天气预报信息,但是http是请求触发的,难道要一小时请求一次吗? 使用cele
-
Django中使用Celery的方法示例
起步 在 <分布式任务队列Celery使用说明> 中介绍了在 Python 中使用 Celery 来实验异步任务和定时任务功能.本文介绍如何在 Django 中使用 Celery. 安装 pip install django-celery 这个命令使用的依赖是 Celery 3.x 的版本,所以会把我之前安装的 4.x 卸载,不过对功能上并没有什么影响.我们也完全可以仅用Celery在django中使用,但使用 django-celery 模块能更好的管理 celery. 使用 可以把有关 C
-
如何使用Celery和Docker处理Django中的定期任务
在构建和扩展Django应用程序时,不可避免地需要定期在后台自动运行某些任务. 一些例子: 生成定期报告 清除缓存 发送批量电子邮件通知 执行每晚维护工作 这是构建和扩展不属于Django核心的Web应用程序所需的少数功能之一.幸运的是,Celery提供了一个强大的解决方案,该解决方案非常容易实现,称为Celery Beat. 在下面的文章中,我们将向您展示如何使用Docker设置Django,Celery和Redis,以便通过Celery Beat定期运行自定义Django Admin命令.
-
Django中如何使用celery异步发送短信验证码详解
目录 1.celery介绍 1.1 celery应用举例 1.2 Celery有以下优点 1.3 Celery 特性 2.工作原理 2.1 Celery 扮演生产者和消费者的角色 3.异步发短信 总结 1.celery介绍 1.1 celery应用举例 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理,如果你的业务场景中需要用到异步任务,就可以考虑使用celery 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着