Python标准库time使用方式详解
目录
- 1、time库
- 1.1、获取格林威治西部的夏令时地区的偏移秒数
- 1.2、时间函数
- 1.3、格式化时间、日期
- 1.4、单调时钟
1、time库
- 时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
- 结构化时间(struct_time)方式:struct_time元组共有9个元素
- 格式化的时间字符串(format_string),时间格式的字符串
1.1、获取格林威治西部的夏令时地区的偏移秒数
- 如果该地区在格林威治东部会返回负值(如西欧,包括英国)
- 对夏令时启用地区才能使用
# coding:utf-8 import time # 获取格林威治西部的夏令时地区的偏移秒数。 print(time.altzone)

1.2、时间函数
- 时间戳
指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数 - 时间元组
用一个元组装起来的9组数字
|
字段 |
含义 |
值 |
|
tm_year |
4位数年 |
2008 |
|
tm_mon |
月 |
1 到 12 |
|
tm_mday |
日 |
1 到 31 |
|
tm_hour |
小时 |
0 到 23 |
|
tm_min |
分钟 |
0 到 59 |
|
tm_sec |
秒 |
0 到 61(60或61 是闰秒) |
|
tm_wday |
一周的第几日 |
0 到 6(0是周一) |
|
tm_yday |
一年的第几日 |
1 到 366(儒略历) |
|
tm_isdst |
夏令时 |
-1, 0, 1 是决定是否为夏令时的旗帜 |
# coding:utf-8 import time # 返回当前时间的时间戳(1970纪元后经过的浮点秒数) print(time.time()) # 接收时间戳返回一个24个定长可读形式的字符串 print(time.ctime()) # Thu Jul 7 20:17:14 2022 print(len(time.ctime()), type(time.ctime())) # 24 <class 'str'> # 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组 print(time.localtime()) print(time.localtime(time.time())) # 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组 print(time.gmtime()) print(time.gmtime(time.time())) # 接收时间元组并返回一个可读的形式为"Thu Jul 7 20:11:04 2022"(2022年7月7日 周四20时11分04秒)的字符串,长度固定为24字符 print(time.asctime()) print(time.asctime(time.gmtime())) print(time.asctime(time.localtime())) print(len(time.asctime()), type(time.asctime())) # 24 <class 'str'> # 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数) # print(time.mktime()) # 参数不可为空 TypeError: time.mktime() takes exactly one argument (0 given) print(time.mktime(time.gmtime())) print(time.mktime(time.localtime())) print(type(time.mktime(time.gmtime()))) # 浮点秒数<class 'float'> # 返回以秒为单位的时间浮点值 print(time.perf_counter()) print(type(time.perf_counter())) # 返回以纳秒为单位的时间整数值 print(time.perf_counter_ns()) # <class 'float'> print(type(time.perf_counter_ns())) # <class 'int'>

1.3、格式化时间、日期
- 时间格式,格式化日期和时间时使用
|
格式符号 |
符号的含义 |
|
%y |
两位数的年份表示(00-99) |
|
%Y |
四位数的年份表示(000-9999) |
|
%m |
月份(01-12) |
|
%d |
月内中的一天(0-31) |
|
%H |
24小时制小时数(0-23) |
|
%I |
12小时制小时数(01-12) |
|
%M |
分钟数(00-59) |
|
%S |
秒(00-59) |
|
%a |
本地简化星期名称 |
|
%A |
本地完整星期名称 |
|
%b |
本地简化的月份名称 |
|
%B |
本地完整的月份名称 |
|
%c |
本地相应的日期表示和时间表示 |
|
%j |
年内的一天(001-366) |
|
%p |
本地A.M.或P.M.的等价符 |
|
%U |
一年中的星期数(00-53)星期天为星期的开始 |
|
%w |
星期(0-6),星期天为 0,星期一为 1,以此类推。 |
|
%W |
一年中的星期数(00-53)星期一为星期的开始 |
|
%x |
本地相应的日期表示 |
|
%X |
本地相应的时间表示 |
|
%Z |
当前时区的名称 |
|
%% |
%号本身 |
# coding:utf-8
import time
import datetime
# 格式化日期
print(time.strftime('%Y-%m-%d %H:%M:%S'))
print(time.strftime('%Y-%m-%d %I:%M:%S'))
print(time.strftime('%X'))
print(time.strftime('%Z'))
# 将字符串转 时间元组
# '%a %b %d %H:%M:%S %Y'
print(time.strptime('2022-07-07 09:58:24', '%Y-%m-%d %H:%M:%S'))
print(time.strptime('2022-07-07 09:58:24', '%Y-%m-%d %I:%M:%S'))

1.4、单调时钟
- 单调时钟是不能向后移动的时钟
- 常用来计算程序运行处理时长
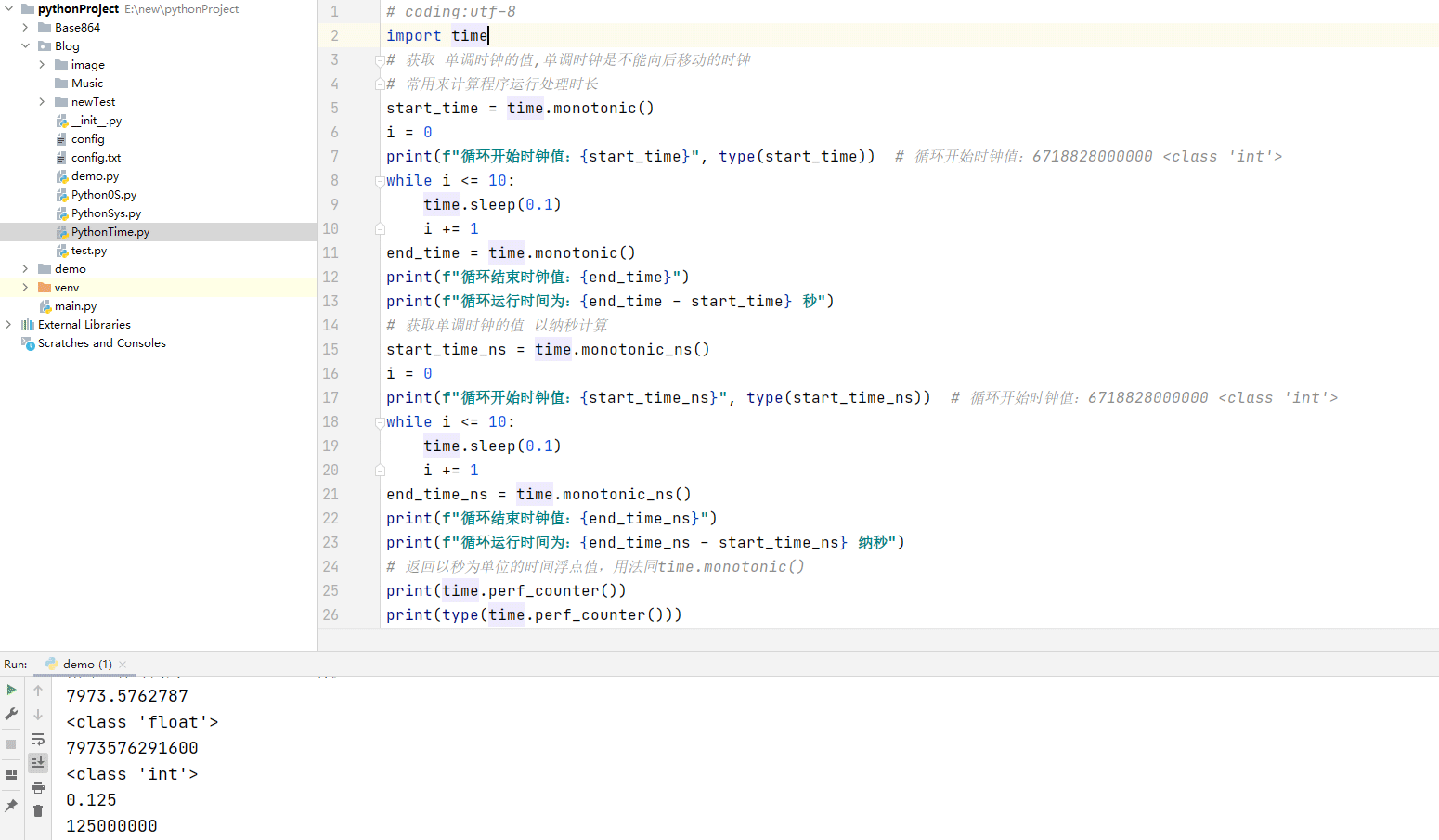
# coding:utf-8
import time
# 获取 单调时钟的值,单调时钟是不能向后移动的时钟
# 常用来计算程序运行处理时长
start_time = time.monotonic()
i = 0
print(f"循环开始时钟值:{start_time}", type(start_time)) # 循环开始时钟值:6718828000000 <class 'int'>
while i <= 10:
time.sleep(0.1)
i += 1
end_time = time.monotonic()
print(f"循环结束时钟值:{end_time}")
print(f"循环运行时间为:{end_time - start_time} 秒")
# 获取单调时钟的值 以纳秒计算
start_time_ns = time.monotonic_ns()
i = 0
print(f"循环开始时钟值:{start_time_ns}", type(start_time_ns)) # 循环开始时钟值:6718828000000 <class 'int'>
while i <= 10:
time.sleep(0.1)
i += 1
end_time_ns = time.monotonic_ns()
print(f"循环结束时钟值:{end_time_ns}")
print(f"循环运行时间为:{end_time_ns - start_time_ns} 纳秒")
# 返回以秒为单位的时间浮点值,用法同time.monotonic()
print(time.perf_counter())
print(type(time.perf_counter()))
# 返回以纳秒为单位的时间整数值,用法同time.monotonic_ns()
print(time.perf_counter_ns()) # <class 'float'>
print(type(time.perf_counter_ns())) # <class 'int'>
# 返回当前系统时间与CPU时间的浮动值(以秒为单位)
print(time.process_time())
# 返回当前系统时间与CPU时间的浮动值(以纳秒为单位)
print(time.process_time_ns())
# 睡眠,参数的单位为秒
time.sleep(1) # 程序等待1秒钟后再执行
到此这篇关于Python标准库time使用方式详解的文章就介绍到这了,更多相关Python标准库time 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python标准库之time模块的语法与简单使用
目录 表示时间的方式 1. 调用语法: 2. time概述 3. 时间获取 4. 时间格式化(将时间以合理的方式展示出来) 5. 程序计时应用 6. 示例 总结 表示时间的方式 时间戳表示法: 即以整型或浮点型表示的是一个以秒为单位的时间间隔.这个时间的基础值是从1970年的1月1号零点开始算起. 格式化的时间字符串: 即以格式化字符串的格式输出时间形式. 元组格式表示法: 即一种Python的数据结构表示.这个元组有9个整型内容(不能少),分别表示不同的时间含义. 索引(Index) 属性(A
-
一篇文章带你了解python标准库--datetime模块
目录 1. datetime模块介绍 1.1 datetime模块包含的类 1.2 datetime模块中包含的常量 2. datetime实例的方法 3. 日期格式化符号 总结 1. datetime模块介绍 1.1 datetime模块包含的类 1.2 datetime模块中包含的常量 2. datetime实例的方法 案例代码 import locale from datetime import datetime,date,time locale.setlocale(locale.LC_C
-
详解Python常用标准库之时间模块time和datetime
目录 time时间模块 time -- 获取本地时间戳 localtime -- 获取本地时间元组(UTC) gmtime -- 获取时间元组(GMT) mktime -- 时间元组获取时间戳 ctime -- 获取时间字符串 asctime -- 时间元组获取时间字符串 strftime -- 格式化时间 strptime -- 格式化时间 sleep -- 时间睡眠 perf_counter -- 时间计时 模拟进度条 程序计时 时间转换示意图 datetime时间模块 date类 time
-
一篇文章带你了解python标准库--time模块
目录 1. 调用语法: 2. time概述 3. 时间获取 4. 时间格式化(将时间以合理的方式展示出来) 5. 程序计时应用 6. 示例 总结 Time库是python中处理时间的标准库 1. 调用语法: import time time.<b>() 计算机时间的表达,提供获取系统时间并格式化输出功能 提供提供系统精确即使功能,用于程序性能分析 2. time概述 time库包括三类函数 时间获取: time() ctime() gmtime() 时间格式化: strftime() strp
-
Python标准库datetime之datetime模块用法分析详解
目录 1.日期时间对象 2.创建日期时间对象 2.1.通过datetime.datetime.utcnow()创建 2.2.通过datetime.datetime.today()函数创建 2.3.通过datetime.datetime.now()创建 2.4.通过datetime.datetime()创建 2.5.查看创建的对象 2.6.查看datetime可以处理的最大的日期时间对象及最小的日期时间对象 3.日期事件对象的属性 4.日期时间对象转换为时间元组 5.将日期时间对象转化为公元历开始
-
Python标准库之time库的使用教程详解
目录 1.时间戳 2.结构化时间对象 3.格式化时间字符串 4.三种格式之间的转换 time模块中的三种时间表示方式: 时间戳 结构化时间对象 格式化时间字符串 1.时间戳 时间戳1970.1.1到指定时间到间隔,单位是秒 import time print(time.time()) 输出: 1649834054.98593 计算一个小时之前的时间戳 #计算一个小时之前的时间戳 print(time.time() - 3600) 输出: 1649830637.5699048 2.结构化时间对象
-
Python标准库time使用方式详解
目录 1.time库 1.1.获取格林威治西部的夏令时地区的偏移秒数 1.2.时间函数 1.3.格式化时间.日期 1.4.单调时钟 1.time库 时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量 结构化时间(struct_time)方式:struct_time元组共有9个元素 格式化的时间字符串(format_string),时间格式的字符串 1.1.获取格林威治西部的夏令时地区的偏移秒数 如果该地区在格林威治东部会返回负值(
-
python 标准库原理与用法详解之os.path篇
os中的path 查看源码会看到,在os.py中有这样几行 if 'posix' in _names: name = 'posix' linesep = '\n' from posix import * #省略若干代码 elif 'nt' in _names: from nt import * try: from nt import _exit __all__.append('_exit') except ImportError: pass import ntpath as path #...
-
Python标准库shutil用法实例详解
本文实例讲述了Python标准库shutil用法.分享给大家供大家参考,具体如下: shutil模块提供了许多关于文件和文件集合的高级操作,特别提供了支持文件复制和删除的功能. 文件夹与文件操作 copyfileobj(fsrc, fdst, length=16*1024): 将fsrc文件内容复制至fdst文件,length为fsrc每次读取的长度,用做缓冲区大小 fsrc: 源文件 fdst: 复制至fdst文件 length: 缓冲区大小,即fsrc每次读取的长度 import shuti
-
Python urllib库的使用指南详解
目录 urlopen Request User-Agent 添加更多的Header信息 添加一个特定的header 随机添加/修改User-Agent 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 在Python中有很多库可以用来抓取网页,我们先学习urllib. 在 python2 中,urllib 被分为urllib,urllib2等 urlopen 我们先来段代码: # urllib_request.py # 导入urllib.request 库 impo
-
Python selenium 三种等待方式详解(必会)
很多人在群里问,这个下拉框定位不到.那个弹出框定位不到-各种定位不到,其实大多数情况下就是两种问题:1 有frame,2 没有加等待.殊不知,你的代码运行速度是什么量级的,而浏览器加载渲染速度又是什么量级的,就好比闪电侠和凹凸曼约好去打怪兽,然后闪电侠打完回来之后问凹凸曼你为啥还在穿鞋没出门?凹凸曼分分中内心一万只羊驼飞过,欺负哥速度慢,哥不跟你玩了,抛个异常撂挑子了. 那么怎么才能照顾到凹凸曼缓慢的加载速度呢?只有一个办法,那就是等喽.说到等,又有三种等法,且听博主一一道来: 1. 强制等待
-
Python中捕获键盘的方式详解
python中捕获键盘操作一共有两种方法 第一种方法: 使用pygame中event方法 使用方式如下:使用键盘右键为例 if event.type = pygame.KEYDOWN and event.key =pygame.K_RIGHT: print('向右移动') 第二种方法: 使用pygame中的key模块 1,使用pygame.key.get_pressed()返回一个包含键盘中所有按键的元组,元组用一个变量接收.如: keys_pressed = pygame.ke
-
对python3标准库httpclient的使用详解
如下所示: import http.client, urllib.parse import http.client, urllib.parse import random USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; M
-
Python pandas库中的isnull()详解
问题描述 python的pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值,我们通过几个例子学习它的使用方法. 首先我们创建一个dataframe,其中有一些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[
-
Python常用库Numpy进行矩阵运算详解
Numpy支持大量的维度数组和矩阵运算,对数组运算提供了大量的数学函数库! Numpy比Python列表更具优势,其中一个优势便是速度.在对大型数组执行操作时,Numpy的速度比Python列表的速度快了好几百.因为Numpy数组本身能节省内存,并且Numpy在执行算术.统计和线性代数运算时采用了优化算法. Numpy的另一个强大功能是具有可以表示向量和矩阵的多维数组数据结构.Numpy对矩阵运算进行了优化,使我们能够高效地执行线性代数运算,使其非常适合解决机器学习问题. 与Python列表相比
-
python PaddleOCR库用法及知识点详解
说明 1.PaddleOCR是基于深度学习的ocr识别库,中文识别精度相当还不错,能够应对大多数文字提取需求. 2.需要依次安装三个依赖库,shapely库可能会受到系统的影响,出现安装错误. 安装命令 pip install paddlepaddle pip install shapely pip install paddleocr 代码实现 ocr = PaddleOCR(use_angle_cls=True,) # 输入待识别图片路径 img_path = r"d:\Desktop\4A3