java实现MapReduce对文件进行切分的示例代码
比如有海量的文本文件,如订单,页面点击事件的记录,量特别大,很难搞定。
那么我们该怎样解决海量数据的计算?
1、获取总行数
2、计算每个文件中存多少数据
3、split切分文件
4、reduce将文件进行汇总
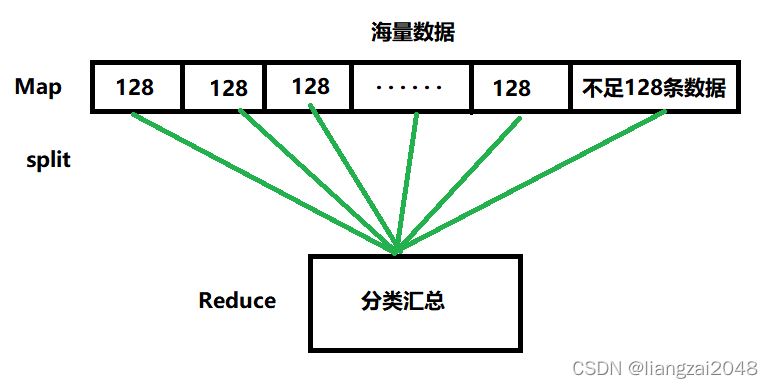
例如这里有百万条数据,单个文件操作太麻烦,所以我们需要进行切分
在切分文件的过程中会出现文件不能整个切分的情况,可能有剩下的数据并没有被读取到,所以我们每个切分128条数据,不足128条再保留到一个文件中
创建MapTask
import java.io.*;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTask extends Thread {
//用来接收具体的哪一个文件
private File file;
private int flag;
public MapTask(File file, int flag) {
this.file = file;
this.flag = flag;
}
@Override
public void run() {
try {
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
HashMap<String, Integer> map = new HashMap<String, Integer>();
while ((line = br.readLine()) != null) {
/**
* 统计班级人数HashMap存储
*/
String clazz = line.split(",")[4];
if (!map.containsKey(clazz)) {
map.put(clazz, 1);
} else {
map.put(clazz, map.get(clazz) + 1);
}
}
br.close();
BufferedWriter bw = new BufferedWriter(
new FileWriter("F:\\IDEADEMO\\shujiabigdata\\part\\part---" + flag));
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
bw.write(key + ":" + value);
bw.newLine();
}
bw.flush();
bw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
创建Map
import java.io.File;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Map {
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 多线程连接池(线程池)
ExecutorService executorService = Executors.newFixedThreadPool(8);
// 获取文件列表
File file = new File("F:\\IDEADEMO\\shujiabigdata\\split");
File[] files = file.listFiles();
//创建多线程对象
int flag = 0;
for (File f : files) {
//为每一个文件启动一个线程
MapTask mapTask = new MapTask(f, flag);
executorService.submit(mapTask);
flag++;
}
executorService.shutdown();
long end = System.currentTimeMillis();
System.out.println(end-start);
}
}
创建ClazzSum
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.HashMap;
public class ClazzSum {
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
BufferedReader br = new BufferedReader(
new FileReader("F:\\IDEADEMO\\shujiabigdata\\data\\bigstudents.txt"));
String line;
HashMap<String, Integer> map = new HashMap<String, Integer>();
while ((line = br.readLine()) != null) {
String clazz = line.split(",")[4];
if (!map.containsKey(clazz)) {
map.put(clazz, 1);
} else {
map.put(clazz, map.get(clazz) + 1);
}
}
System.out.println(map);
long end = System.currentTimeMillis();
System.out.println(end-start);
}
}
创建split128
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.ArrayList;
public class Split128 {
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(
new FileReader("F:\\IDEADEMO\\shujiabigdata\\data\\students.txt"));
//用作标记文件,也作为文件名称
int index = 0;
BufferedWriter bw = new BufferedWriter(
new FileWriter("F:\\IDEADEMO\\shujiabigdata\\split01\\split---" + index));
ArrayList<String> list = new ArrayList<String>();
String line;
//用作累计读取了多少行数据
int flag = 0;
int row = 0;
while ((line = br.readLine()) != null) {
list.add(line);
flag++;
// flag = 140
if (flag == 140) {// 一个文件读写完成,生成新的文件
row = 0 + 128 * index;
for (int i = row; i <= row + 127; i++) {
bw.write(list.get(i));
bw.newLine();
}
bw.flush();
bw.close();
/**
* 生成新的文件
* 计数清零
*/
index++;
flag = 12;
bw = new BufferedWriter(
new FileWriter("F:\\IDEADEMO\\shujiabigdata\\split01\\split---" + index));
}
}
//文件读取剩余128*1.1范围之内
for (int i = list.size() - flag; i < list.size(); i++) {
bw.write(list.get(i));
bw.newLine();
}
bw.flush();
bw.close();
}
}
创建Reduce
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.HashMap;
public class Reduce {
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
HashMap<String, Integer> map = new HashMap<String, Integer>();
File file = new File("F:\\IDEADEMO\\shujiabigdata\\part");
File[] files = file.listFiles();
for (File f : files) {
BufferedReader br = new BufferedReader(new FileReader(f));
String line;
while ((line = br.readLine()) != null) {
String clazz = line.split(":")[0];
int sum = Integer.valueOf(line.split(":")[1]);
if (!map.containsKey(clazz)) {
map.put(clazz, sum);
} else {
map.put(clazz, map.get(clazz) + sum);
}
}
}
long end = System.currentTimeMillis();
System.out.println(end-start);
System.out.println(map);
}
}
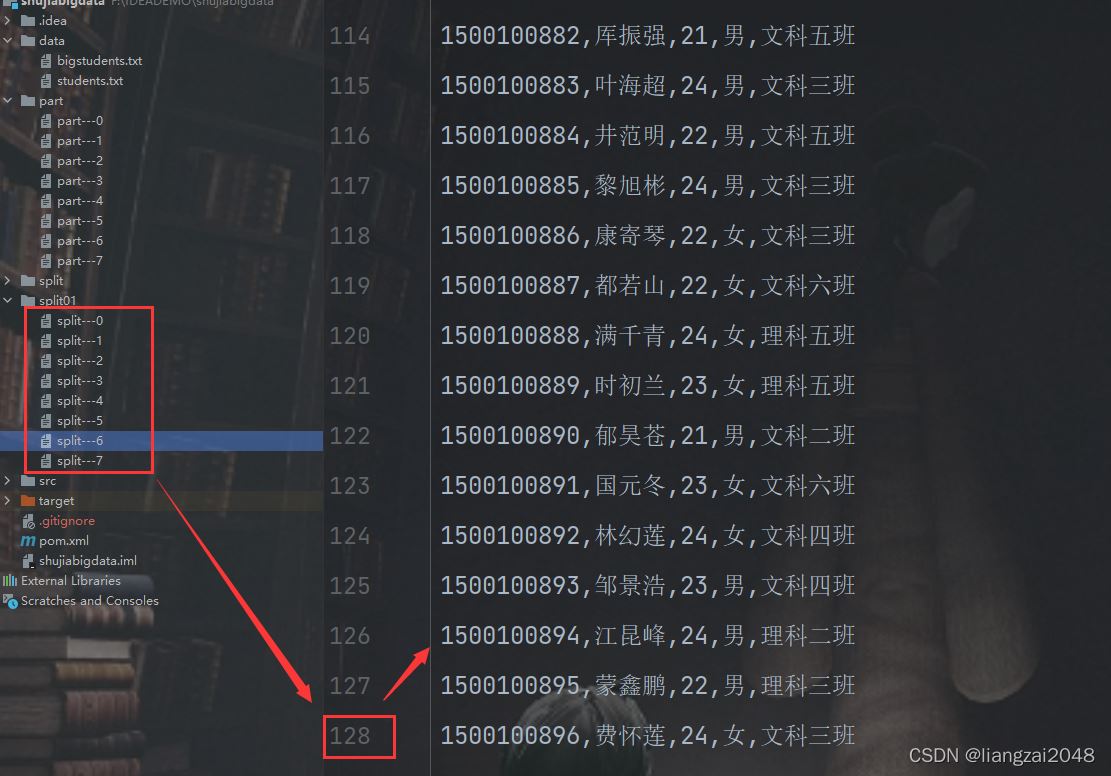
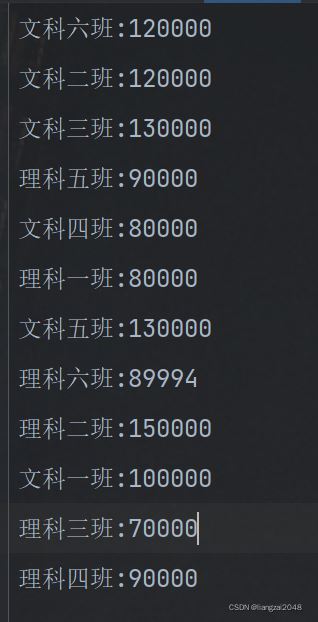
最后将文件切分了8份,这里采用了线程池,建立线程连接,多个线程同时启动,比单一文件采用多线程效率更高更好使。
到此这篇关于java实现MapReduce对文件进行切分的示例代码的文章就介绍到这了,更多相关java MapReduce 文件切分内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java/Web调用Hadoop进行MapReduce示例代码
Hadoop环境搭建详见此文章http://www.jb51.net/article/33649.htm. 我们已经知道Hadoop能够通过Hadoop jar ***.jar input output的形式通过命令行来调用,那么如何将其封装成一个服务,让Java/Web来调用它?使得用户可以用方便的方式上传文件到Hadoop并进行处理,获得结果.首先,***.jar是一个Hadoop任务类的封装,我们可以在没有jar的情况下运行该类的main方法,将必要的参数传递给它.input 和outpu
-
java 矩阵乘法的mapreduce程序实现
java 矩阵乘法的mapreduce程序实现 map函数:对于矩阵M中的每个元素m(ij),产生一系列的key-value对<(i,k),(M,j,m(ij))> 其中k=1,2.....知道矩阵N的总列数;对于矩阵N中的每个元素n(jk),产生一系列的key-value对<(i , k) , (N , j ,n(jk)>, 其中i=1,2.......直到i=1,2.......直到矩阵M的总列数. map package com.cb.matrix; import stati
-
Java函数式编程(七):MapReduce
译注:map(映射)和reduce(归约,化简)是数学上两个很基础的概念,它们很早就出现在各类的函数编程语言里了,直到2003年Google将其发扬光大,运用到分布式系统中进行并行计算后,这个组合的名字才开始在计算机界大放异彩(那些函数式粉可能并不这么认为).本文我们会看到Java 8在摇身一变支持函数式编程后,map和reduce组合的首次亮相(这里只是初步介绍,后续还会有针对它们的专题). 对集合进行归约 现在为止我们已经介绍了几个操作集合的新技巧了:查找匹配元素,查找单个元素,集合转化.这
-
云计算实验:Java MapReduce编程
目录 [实验作业]简单流量统计 [实验作业]索引倒排输出行号 实验题目: MapReduce:编程 实验内容: 本实验利用 Hadoop 提供的 Java API 进行编程进行 MapReduce 编程. 实验目标: 掌握MapReduce编程. 理解MapReduce原理 [实验作业]简单流量统计 有如下这样的日志文件: 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200 13726
-
Java基础之MapReduce框架总结与扩展知识点
一.MapTask工作机制 MapTask就是Map阶段的job,它的数量由切片决定 二.MapTask工作流程: 1.Read阶段:读取文件,此时进行对文件数据进行切片(InputFormat进行切片),通过切片,从而确定MapTask的数量,切片中包含数据和key(偏移量) 2.Map阶段:这个阶段是针对数据进行map方法的计算操作,通过该方法,可以对切片中的key和value进行处理 3.Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputColle
-
java实现MapReduce对文件进行切分的示例代码
比如有海量的文本文件,如订单,页面点击事件的记录,量特别大,很难搞定.那么我们该怎样解决海量数据的计算? 1.获取总行数2.计算每个文件中存多少数据3.split切分文件4.reduce将文件进行汇总 例如这里有百万条数据,单个文件操作太麻烦,所以我们需要进行切分在切分文件的过程中会出现文件不能整个切分的情况,可能有剩下的数据并没有被读取到,所以我们每个切分128条数据,不足128条再保留到一个文件中 创建MapTask import java.io.*; import java.util.Ha
-
java接收ios文件上传的示例代码
本文实例为大家分享了java如何接收ios文件上传的具体代码,供大家参考,具体内容如下 ios Multipart/form-data POST请求java后台spring接口一直出错,搞了两天,终于解决了,积累下来 package com.xx.controller; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.util.Iterator
-
java对于目录下文件的单词查找操作代码实现
这篇文章主要介绍了java对于目录下文件的单词查找操作代码实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 写入文件的目录.代码通过找目录下的文件,进行相关函数的操作.如果目录下面包含子目录.代码设有调用递归的方法,在寻找子目录下的文件 在进行相关的函数操作.函数主要是按用户输入的个数要求输出文件中出现次数最多的前几位字母. package com.keshangone; //将想要输出的数据写入新的文件里面 import java.util
-
Java实现一个简单的文件上传案例示例代码
Java实现一个简单的文件上传案例 实现流程: 1.客户端从硬盘读取文件数据到程序中 2.客户端输出流,写出文件到服务端 3.服务端输出流,读取文件数据到服务端中 4.输出流,写出文件数据到服务器硬盘中 下面上代码 上传单个文件 服务器端 package FileUpload; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.Serve
-
Java实现Excel文件加密解密的示例代码
目录 概述 示例大纲 工具 Java代码示例 示例1加密工作簿 示例2解密工作簿 示例3加密工作表 示例4加密工作表指定数据范围 示例5设置工作表公式隐藏 示例6解密Excel工作表 概述 设置excel文件保护时,通常可选择对整个工作簿进行加密保护,打开文件时需要输入密码:或者对指定工作表进行加密,即设置表格内容只读,无法对工作表进行编辑.另外,也可以对工作表特定区域设置保护,即设置指定区域可编辑或者隐藏数据公式,保护数据信息来源.无需设置文档保护时,可撤销密码保护,即解密文档.下面,将通过j
-
Python3 实现文件批量重命名示例代码
在Python中os模块里,os.renames() 方法用于递归重命名目录或文件.类似rename(). rename()方法语法格式如下: os.rename(old,new) old是需要修改的目录/文件名,new是修改后的目录/文件名,通过这个方法我们可以很轻松的完成批量在文件/目录增加固定前缀或者批量删除文件/目录固定前缀 . 以下代码Windows下和Linux都可以使用. 示例如下: 增加前缀'[Linuxidc.]': import os path='/home/linuxidc
-
Java 添加Word目录的2种方法示例代码详解
目录是一种能够快速.有效地帮助读者了解文档或书籍主要内容的方式.在Word中,插入目录首先需要设置相应段落的大纲级别,根据大纲级别来生成目录表.本文中生成目录分2种情况来进行: 1.文档没有设置大纲级别,生成目录前需要手动设置 2.文档已设置大纲级别,通过域代码生成目录 使用工具: •Free Spire.Doc for Java 2.0.0 (免费版) •IntelliJ IDEA 工具获取途径1:通过官网下载jar文件包,解压并导入jar文件到IDEA程序. 工具获取途径2:通过Maven仓
-
Java spring boot 实现支付宝支付功能的示例代码
一.准备工作: 1.登陆支付宝开发者中心,申请一个开发者账号. 地址:https://openhome.alipay.com/ 2.进入研发服务: 3.点击链接进入工具下载页面: 4.点击下载对应版本的RSA公钥生成器: 5.生成公钥密钥(记录你的应用私钥): 6.在支付宝配置公钥(点击保存): 二.搭建demo 1.引入jia包: <dependency> <groupId>com.alipay.sdk</groupId> <artifactId>alip
-
以Spring Boot的方式显示图片或下载文件到浏览器的示例代码
以Java web的方式显示图片到浏览器以Java web的方式下载服务器文件到浏览器 以Spring Boot的方式显示图片或下载文件到浏览器 请求例子:http://localhost:8080/image/1564550185144.jpeg 示例代码: import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.R
-
JAVA实现PDF转HTML文档的示例代码
本文是基于PDF文档转PNG图片,然后进行图片拼接,拼接后的图片转为base64字符串,然后拼接html文档写入html文件实现PDF文档转HTML文档. 引入Maven依赖 <!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox --> <dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox